本文主要是介绍#每天一篇论文 Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud
单目伪激光雷达点云3D目标检测
摘要
单目3D场景理解任务,例如目标大小估计,车头角度估计和3D位置估计,非常具有挑战性。当前成功的三维场景理解方法需要使用三维传感器。另一方面,基于单一图像的方法性能明显较差。在这项工作中,我们的目标是通过增强基于激光雷达的算法来处理单个图像输入,从而弥合3D传感和2D传感在3D目标检测方面的性能差距。具体来说,我们进行单目深度估计,并将输入图像提升到点云表示,我们称之为伪激光雷达点云。然后我们可以用我们的伪激光雷达端到端训练一个基于激光雷达的三维检测网络。按照两阶段3D检测算法的流程,我们在输入图像中检测2D目标建议,并从伪激光雷达中为每个建议提取一个点云截锥。然后为每个截锥检测一个定向的三维边界框。为了处理大量噪音伪激光雷达,我们提出了两个创新点:(1)使用二维-三维包围盒一致性约束,调整预测的三维包围盒,使其投影到图像上后与其对应的二维方案有较高的重叠度;(2)使用实例遮罩代替包围盒作为二维方案的表示,以减少点云视景中不属于对象的点的数量。通过对KITTI基准的评估,我们在所有单目视觉方法中,鸟瞰和3D目标检测方面都取得了一流的性能,有效地将性能提高了四倍于以前的最先进水平。
贡献
(1)提出了一种单目三维目标检测流水线,增强了基于激光雷达的单目图像检测方法;
(2)通过实验证明了该框架的瓶颈在于单目深度估计不准确导致的伪激光雷达噪声;
(3)提出在训练过程中使用包围盒一致性损失和在测试过程中使用一致性优化来调整三维包围盒预测;
(4)证明了使用实例掩码作为二维检测方案表示的优点;
(5)在标准的三维目标检测基准上,我们实现了最先进的性能,并且比所有的单目方法都有了前所未有的改进。
方法
目标是仅从一个RGB图像估计对象的定向3D边界框

1.深度估计
本文采用单目深度估计DORN算法
2.深度图–点云图生成
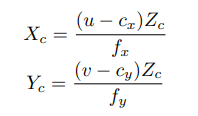
(cx, cy) 像素中心. fx and fy are the focal length of the camera along x and y axes
3.伪激光雷达和激光雷达区别
伪激光雷达与激光雷达点云的区别在于点云的密度。虽然高成本的激光雷达可以提供高分辨率的点云,但激光雷达点的数量仍然比伪激光雷达点云少至少一个数量级。
2D实例Mask检测
为了为每个对象生成一个点云截面,我们首先在2D中检测一个对象建议。

Amodel 3D目标检测
基于生成的伪激光雷达和二维实例Mask,可以提取一组点云截头体,然后通过这些截面体训练出一种基于两级激光雷达的三维边界检测算法。
2D - 3D 边界盒关联
为了缓解局部失准问题,本文作者使用边界盒一致性的几何约束来改进三维边界盒估计。由于三维包围盒估计不准确,其二维投影也很可能与相应的二维方案不匹配。首先估计三维8个点顶点,然后将2D估计的边框投影到3D边框,通过关联3D和2D边框,通过几何一致性约束三维边界盒。

边界框一致性损失
在训练过程中,我们提出了一个基于点网的三维盒子修正模块2,用于包围盒的细化。3D盒校正模块以分割后的点云和3D盒估计模块提取的特征作为输入,输出3D包围盒参数的校正。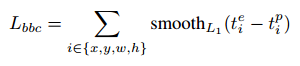
实验结果
1.数据集
实例分割先用Cityspace训练然后用kitti训练


这篇关于#每天一篇论文 Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








