monocular专题
MonoHuman: Animatable Human Neural Field from Monocular Video 翻译
MonoHuman:来自单目视频的可动画人类神经场 摘要。利用自由视图控制来动画化虚拟化身对于诸如虚拟现实和数字娱乐之类的各种应用来说是至关重要的。已有的研究试图利用神经辐射场(NeRF)的表征能力从单目视频中重建人体。最近的工作提出将变形网络移植到NeRF中,以进一步模拟人类神经场的动力学,从而动画化逼真的人类运动。然而,这种流水线要么依赖于姿态相关的表示,要么由于帧无关的优化而缺乏运动一致性
HumanNeRF:Free-viewpoint Rendering of Moving People from Monocular Video 翻译
HumanNeRF:单目视频中运动人物的自由视点绘制 引言。我们介绍了一种自由视点渲染方法- HumanNeRF -它适用于一个给定的单眼视频ofa人类执行复杂的身体运动,例如,从YouTube的视频。我们的方法可以在任何帧暂停视频,并从任意新的摄像机视点或甚至针对该特定帧和身体姿势的完整360度摄像机路径渲染主体。这项任务特别具有挑战性,因为它需要合成身体的照片级真实感细节,如从输入视频中可能

Monocular Model-Based 3D Tracking of Rigid Objects:2005年综述
1 Introduction 在视频序列中跟踪一个物体意味着在物体或摄像机移动时,持续识别其位置。根据物体类型、物体和摄像机的自由度以及目标应用的不同,有多种方法可供选择。二维跟踪通常旨在跟踪物体或物体部分的图像投影,这些物体的三维位移会导致可以建模为二维变换的运动。为处理由于透视效应或变形引起的外观变化,需要一个自适应模型。它可以提供物体图像位置,表示为其质心和尺度或仿射变换 [141, 26

NID-SLAM: Robust Monocular SLAM using Normalised Information Distance - Part2
在上一篇博客中, 我介绍了NID-SLAM中的的Robust Direct NID Tracking的实现。这篇继续记录一下文章中 Multi-resolution NID Tracking的部分。 Multi-resolution NID Tracking 文中提到LSD-SLAM中为提高鲁棒性而使用image-pyramid的方法。LSD-SLAM中是对待匹配的原始图像建立图像金字塔。NI

Paper Share_ NID-SLAM_ Robust Monocular SLAM using Normalised Information Distance
【写在前面】 一直都有写博客的意愿,但是一直都没有实际行动。尝试了几次也都没有坚持下来。这次打算逼自己一下,坚持下去。 这次决心坚持写博客也是出于记录平时自己日常所学的考虑。平时有时间或者需要会去看论文,但是一篇论文当时看的时候似乎是懂了,但是过几天就没什么印象了。感觉这样效果很不好。所以打算写博客记录自己所看的论文。其一是加深自己的理解,其二是记录分析的内容和过程,方便日后查看与
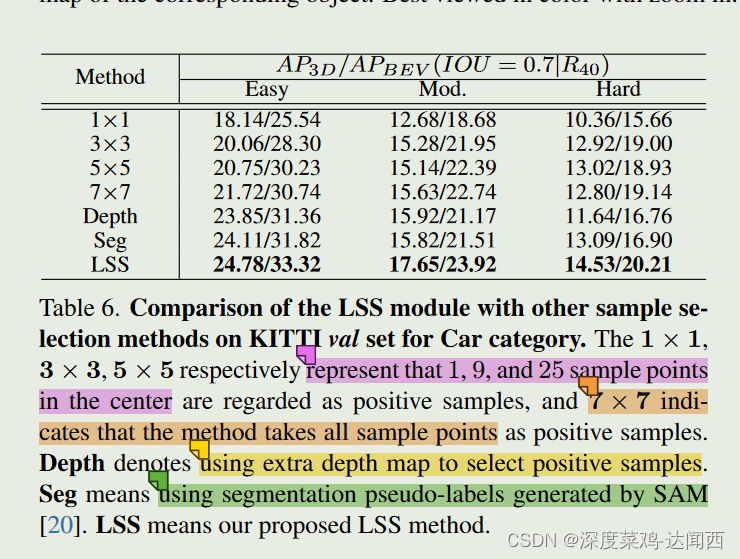
论文笔记 - :MonoLSS: Learnable Sample Selection For Monocular 3D Detection
论文笔记✍MonoLSS: Learnable Sample Selection For Monocular 3D Detection 📜 Abstract 🔨 主流做法+限制 : 以前的工作以启发式的方式使用特征来学习 3D 属性,没有考虑到不适当的特征可能会产生不利影响。 🔨 本文做法: 本文引入了样本选择,即只训练合适的样本来回归 3D 属性。 为了自适应地选择样本,
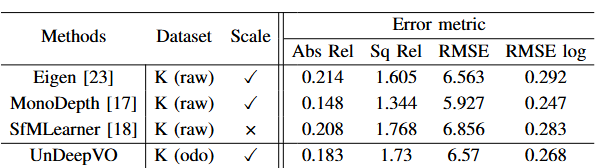
UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning 论文阅读
论文链接 UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning 0. Abstract 提出了一种名为 UnDeepVO 的新型单目视觉里程计(VO)系统。 UnDeepVO 能够使用深度神经网络估计单目相机的 6-DoF 位姿及其视图深度两个显着特征:一是无监督深度学习方案,二是绝对规模恢复

【论文阅读-姿态估计】CVPR2021_CanonPose: Self-Supervised Monocular 3D Human Pose Estimation in the Wild
本文将介绍一篇基于自监督的3D人体姿态估计方法,作者来自德国汉诺威大学和加拿大英属哥伦比亚大学。 论文链接:https://arxiv.org/abs/2011.14679 代码链接: 尚未公开 主要思想: 本文提出了一个利用多视角2D图像估计3D人体姿态的模型,主要框架如下图所示。 首先将同一姿态不同视角下的图像分别输入两个共享权重的Lifting网络,这部分网络输出为两个分支,一个分支输出
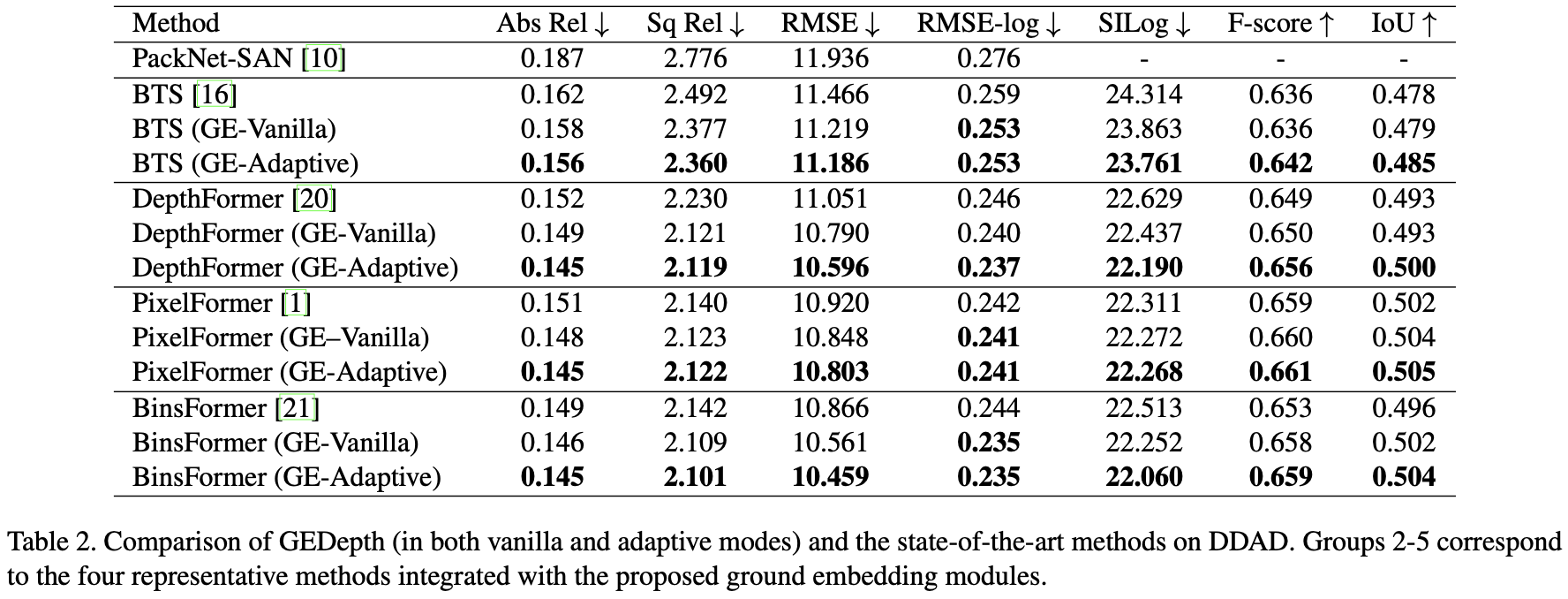
GEDepth:Ground Embedding for Monocular Depth Estimation
参考代码:gedepth 出发点与动机 相机的外参告诉了相机在世界坐标系下的位置信息,那么可以用这个外参构建一个地面基础深度作为先验,后续只需要在这个地面基础深度先验基础上添加offset就可以得到结果深度,这样可以极大简化深度估计网络学习的难度,自然深度估计的性能就上去了。先不说这个深度估计的实际效果如何,但是这个将复杂的问题简单化的思路是可以借鉴的。但是这个鲁棒性如何就需要打问号了,BEV感

【3D目标检测】Categorical Depth Distribution Network for Monocular 3D Object Detection
目录 概述细节网络结构类别深度分布损失函数 与OFT-Net 的对比 概述 本文是基于单目图像的3D目标检测方法。 【2021】【CaDNN 】 研究的问题: 以往的深度信息学习方法(无论是显示学习还是隐式学习)都存在一些问题,会导致后面边界框定位困难显示学习的方法将深度估计和目标检测分开训练,导致得到的深度图是次优的,进而导致边界框定位性能差。隐式学习的方法会出现特征涂抹的问

《论文阅读》Deep Online Correction for Monocular Visual Odometry
留个笔记自用 Deep Online Correction for Monocular Visual Odometry 做什么 Monocular Visual Odometry单目视觉里程计 相机在运动过程中连续两帧之间会存在overlap,即会同时观测到三维世界中的某些场景以及特征点。而这些场景特征点会投射到2D图片上,通过图片的对齐或者特征的匹配,可以找到前后图片上特点或patch的

#每天一篇论文 Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud
Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud 单目伪激光雷达点云3D目标检测 摘要 单目3D场景理解任务,例如目标大小估计,车头角度估计和3D位置估计,非常具有挑战性。当前成功的三维场景理解方法需要使用三维传感器。另一方面,基于单一图像的方法性能明显较差。在这项工作中,我们的目标是通过增强基于激光雷达的算法来处理单个图
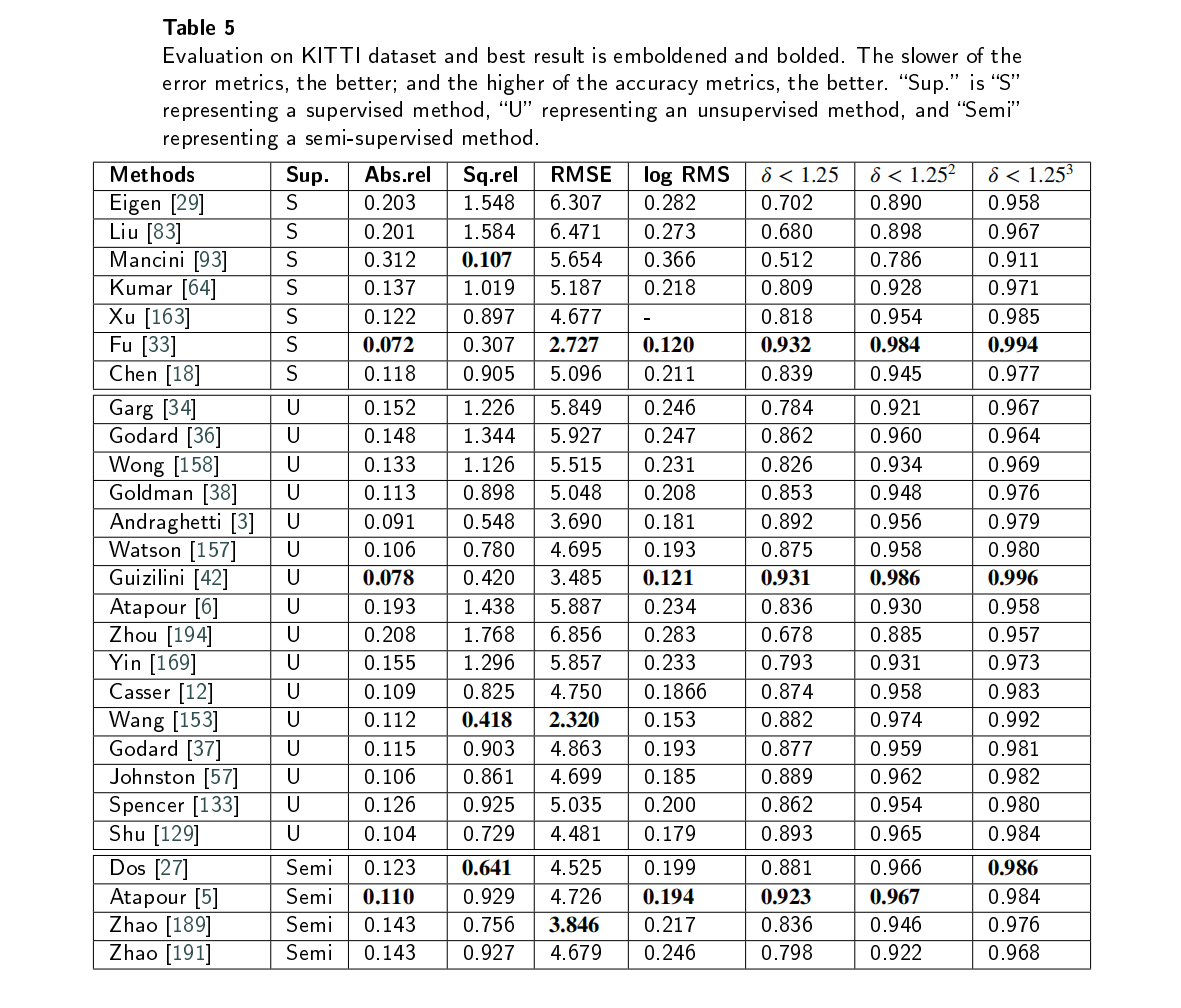
Deep Learning for Monocular Depth Estimation: A Review.基于深度学习的深度估计
传统的深度估计方法通常是使用双目相机,计算两个2D图像的视差,然后通过立体匹配和三角剖分得到深度图。然而,双目深度估计方法至少需要两个固定的摄像机,当场景的纹理较少或者没有纹理的时候,很难从图像中捕捉足够的特征来匹配。所以最近单目深度估计发展的越来越快,但是由于单目图像缺乏可靠的立体视觉关系,因此在三维空间中回归深度本质上是一种不适定问题。 单目图像采用二维形式来重新反射三维世界,然而,有一维场景
Monocular Total capture: posing face, body, and hands in the wild
(2)公式算POF, 即关节到关节的单位向量, 跟PAF中2维向量不同, 这里是3维向量公式(4)中, j m B j_m^B jmB是2d image detected keypoints, Π ( J ~ m B ( θ , ϕ , t ) ) \mathbf \Pi(\widetilde{\mathbf J}^B_m(\theta, \phi, t)) Π(J mB(θ,ϕ,t)

ORB-SLAM2: an Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras
orb-slam2 对 1进行了改进, 从overview图中就可以看出 主要体现在 对stereo camera 和 depth camera的支持 加入了full BA

EventCap: Monocular 3D Capture of High-Speed Human Motionsusing an Event Camera论文笔记
论文翻译 Abstract 高帧率是捕捉快速人体运动的关键要求。在这种情况下,现有的基于无标记图像的方法受到照明要求、高数据带宽和随之而来的高计算开销的限制。在这篇文章中,我们提出了event cap——第一个使用单个事件摄像机对高速人体运动进行三维捕捉的方法。我们的方法结合了基于模型的优化和基于CNN的人体姿态检测来捕捉高频运动细节并减少跟踪中的漂移。因此,与使用高帧率视频相比,我们可以以毫

【VINS-Mono论文全文翻译】:VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator
文章目录 摘要一、引言二、相关工作三、概述四、数据预处理A.视觉处理前端B.IMU预积分 五、估计器初始化(松耦合初始化提供优化初始值和状态)A.滑动窗口(Sliding Window)纯视觉SfMB.视觉惯性联合校准 六、紧耦合单目VIOA.公式B.IMU测量残差C.视觉测量残差(视觉重投影误差部分)D.边缘化E.摄像机速率状态估计的纯运动视觉惯性BAF.IMU前向传递以达到IMU速率状态
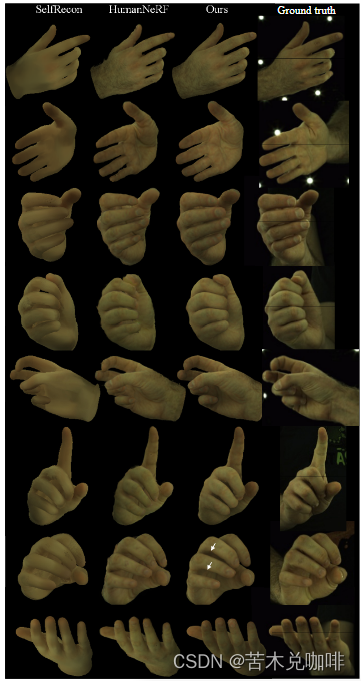
Hand Avatar: Free-Pose Hand Animation and Rendering from Monocular Video
Github: https://seanchenxy.github.io/HandAvatarWeb 1、结构摘要 MANO-HD模型:作为高分辨率网络拓扑来拟合个性化手部形状将手部几何结构分解为每个骨骼的刚性部分,再重新组合成对的几何编码,得到一个跨部分的一致占用场纹理建模:在MANO-HD表面设计了可驱动的anchor,记录反照率;定向软占用用于描述光线-表面关系,生成照明场,进一步用于解
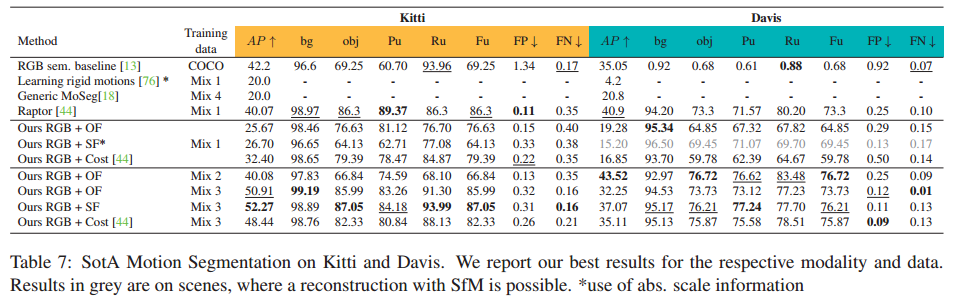
On Moving Object Segmentation from Monocular Video with Transformers 论文阅读
论文信息 标题:On Moving Object Segmentation from Monocular Video with Transformers 作者: 来源:ICCV 时间:2023 代码地址:暂无 Abstract 通过单个移动摄像机进行移动对象检测和分割是一项具有挑战性的任务,需要了解识别、运动和 3D 几何。将识别和重建结合起来可以归结为融合问题,其中需要结合外观和运动特征
On Moving Object Segmentation from Monocular Video with Transformers 论文阅读
论文信息 标题:On Moving Object Segmentation from Monocular Video with Transformers 作者: 来源:ICCV 时间:2023 代码地址:暂无 Abstract 通过单个移动摄像机进行移动对象检测和分割是一项具有挑战性的任务,需要了解识别、运动和 3D 几何。将识别和重建结合起来可以归结为融合问题,其中需要结合外观和运动特征

Monocular arbitrary moving object discovery and segmentation 论文阅读
基本信息 题目:Monocular Arbitrary Moving Object Discovery and Segmentation 作者: 来源:BMVC 时间:2021 代码地址:https://github.com/michalneoral/Raptor Abstract 我们提出了一种发现和分割场景中独立移动的物体或其部分的方法。给定三个单眼视频帧,该方法输出语义上有意义的区域

Monocular arbitrary moving object discovery and segmentation 代码复现
环境 https://github.com/michalneoral/Raptor 1.创建environment.yaml name: raptorchannels:- pytorch- conda-forgedependencies:- python=3.8- pytorch=1.9.0- torchvision=0.10.0- cudatoolkit=11.1- pip con
Monocular arbitrary moving object discovery and segmentation 论文阅读
基本信息 题目:Monocular Arbitrary Moving Object Discovery and Segmentation 作者: 来源:BMVC 时间:2021 代码地址:https://github.com/michalneoral/Raptor Abstract 我们提出了一种发现和分割场景中独立移动的物体或其部分的方法。给定三个单眼视频帧,该方法输出语义上有意义的区域
![[論文筆記] Monocular Pose Estimation of 3D Objects using Temporally Consistent Local Color Histograms](https://img-blog.csdn.net/20180914044107931?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Rlbm5pc19MZWVf/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[論文筆記] Monocular Pose Estimation of 3D Objects using Temporally Consistent Local Color Histograms
Real-Time Monocular Pose Estimation of 3D Objects using Temporally Consistent Local Color Histograms 這是小弟第一篇論文筆記,將來應該會每週更新一篇論文筆記,自己還很菜,文中有些基礎部分知識還沒理解的部分會略過,有機會的話會再補足,若內文有錯誤還請各位多多包涵不吝指正。 背景介紹: 實踐中

ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras
[1] Mur-Artal R, Tardós J D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1-8. 为了方便阅读转自【泡泡机器人翻译专栏】ORB-SLAM2:一种开源的VSLA
ORB-SLAM2: an Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras
https://www.sohu.com/a/154011668_715754 泡泡机器人翻译作品 原文:ORB-SLAM2: an Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras 作者:Raúl Mur-Artal and Juan D. Tardós 摘要 ORB-SLAM2是基于单目,双目和R