本文主要是介绍On Moving Object Segmentation from Monocular Video with Transformers 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文信息
标题:On Moving Object Segmentation from Monocular Video with Transformers
作者:

来源:ICCV
时间:2023
代码地址:暂无
Abstract
通过单个移动摄像机进行移动对象检测和分割是一项具有挑战性的任务,需要了解识别、运动和 3D 几何。将识别和重建结合起来可以归结为融合问题,其中需要结合外观和运动特征来进行分类和分割。
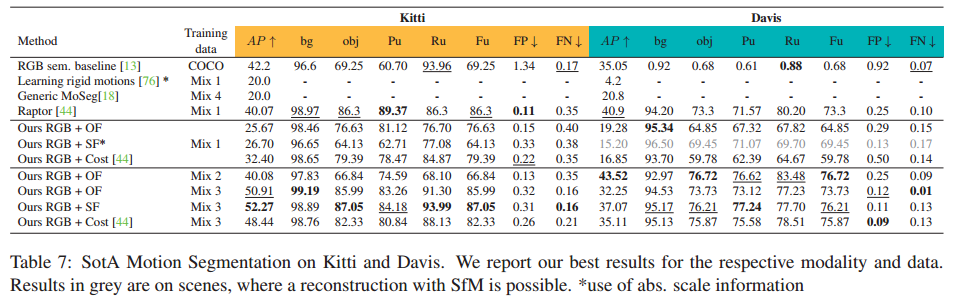
在本文中,我们提出了一种用于单目运动分割的新颖融合架构 - M3Former,它利用Transformer的强大性能进行分割和多模态融合。由于从单目视频重建运动是不适定的,我们系统地分析了该问题的不同 2D 和 3D 运动表示及其对分割性能的重要性。最后,我们分析了训练数据的效果,并表明需要不同的数据集才能在 Kitti 和 Davis 上实现 SotA 性能。
Introduction
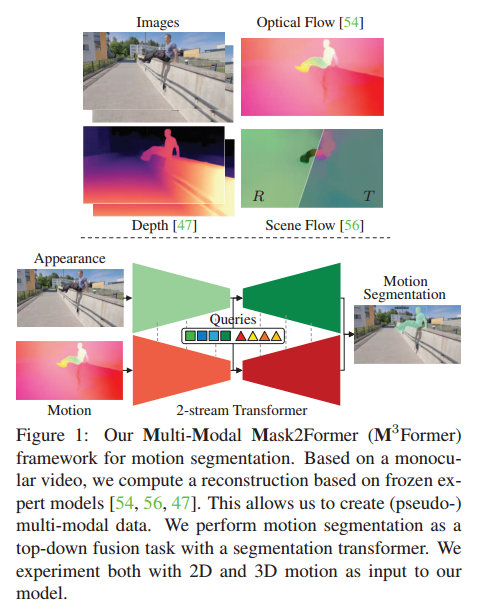
我们将我们的框架称为多模态 Mask2Former (M3Former),因为我们将来自多种模态的信息与屏蔽注意力相结合。由于单目视频仅提供单一模态流,因此我们利用冻结专家模型 [47,54,56] 来计算不同的运动表示,请参见图 1。我们的贡献有四个方面:
-
我们设计了一种新颖的带有编码器和解码器的双流架构。我们分析了该框架内不同融合策略的性能。
-
我们在我们的框架内系统地分析了之前工作中不同运动表示(光流、场景流、高维嵌入)的效果。
-
我们凭经验展示不同训练数据的效果。平衡不同来源的运动模式和语义类别对于现实视频的强大性能至关重要。
-
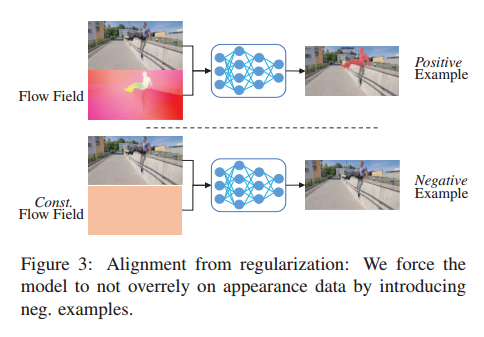
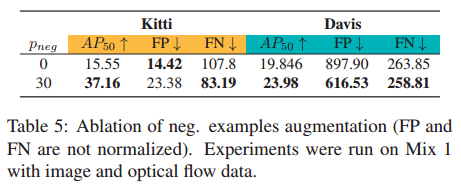
我们引入了一种非常简单的增强技术,以实现更好的多模态对齐。通过引入负数。在没有运动信息的示例中,我们迫使网络不要过度依赖外观数据。
Problem Statement
给定来自单个摄像机的视频 { I 1 , I 2 , . . . , I N } \{I_1, I_2, ..., I_N \} {I1,I2,...,IN},我们想要检测并分割通用的独立移动对象。对象被定义为空间连接的像素组,属于同一语义类。所有标签都合并为一个“对象”,因为只有运动状态很重要。检测器在训练期间只能看到有限数量的类。通用对象检测假设训练和测试类标签集之间不平衡。我们想要识别任何移动的物体,即使我们在训练期间从未见过的类。当一个物体的表观运动不是由相机自身运动引起时,该物体被定义为独立移动。当只有一部分在运动时,物体仍然被认为是运动的,例如当一个人移动一只手臂时,那么整个人就应该被分割。
Appoach
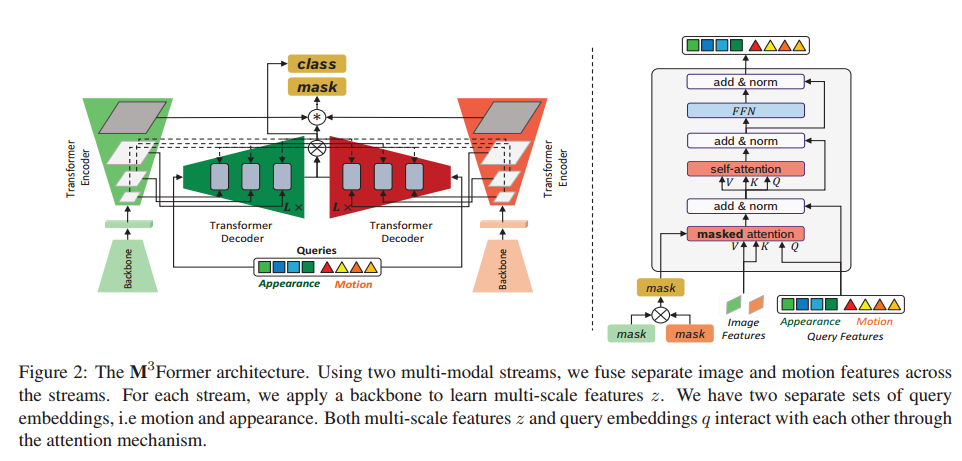
我们为该任务引入了 M3Former 架构,如图 2 所示。我们方法的主要思想是通过注意力灵活地融合外观和运动数据的多尺度特征。
Motion Representation
我们分析了单模态推理和与外观特征融合的性能。给定两个图像 I 1 , I 2 ∈ R H × W × 3 I_1, I_2 ∈ R_{H×W×3} I1,I2∈RH×W×3,我们对两帧之间的运动 F 1 → 2 F_{1→2} F1→2 感兴趣。
optical flow:RAFT
Higher-dimensional Motion Costs:光流是实际 3D 运动的 2D 投影。多个运动可以映射到同一个投影,因此重建是不明确的。从光流重建物体和相机运动有多种退化情况[76]。退化情况在应用程序中很常见,例如道路上的所有车辆共线行驶。
为了稳健地检测移动物体,我们需要某种形式的独立于运动结构的 3D 先验。 [76] 的作者制定了四个手工标准来计算两帧之间的更高维成本函数 C 12 ∈ R H × W × 14 C_{12} ∈ R^{H×W×14} C12∈RH×W×14。该成本函数在违反静态场景假设的区域具有更高的成本。计算涉及估计光流[54]、光学扩展[75]、相机运动[24]和单目深度[47]。 [44]的作者通过使用后向 F 2 → 1 F_{2→1} F2→1 和前向运动 F 2 → 3 F_{2→3} F2→3,将此成本函数扩展为三帧公式 C 13 ∈ R H × W × 28 C_{13} ∈ R^{H×W×28} C13∈RH×W×28。这种成本嵌入的计算涉及最多四个神经网络,每个神经网络都在自己的特定数据集上进行训练。
Scene Flow:
存在一个更简单的 minimal formulation-3D scene flow。给定两个 RGBD 框架 { I 1 , Z 1 } \{I_1, Z_1\} {I1,Z1} 和 { I 2 , Z 2 } \{I_2, Z_2\} {I2,Z2},我们将运动计算为刚体变换场 F ∈ R H × W × 6 ∈ S E 3 F ∈ R^{H×W×6} ∈ SE3 F∈RH×W×6∈SE3。 RAFT-3D [56] 是 2D 光流网络 [54] 的直接 3D 等效,并且自然地包括几何优化。这项工作的主要思想是计算每个像素的运动 g ∈ SE3,而不对语义做出任何假设。
由于以相同的刚体运动移动,像素自然地组合成具有语义意义的对象。我们围绕这个想法 - 给定场景中的多个刚体运动,我们想要推断实例分割。
虽然用于光流训练的数据集有许多不同的[1,48,10,22],但用于场景流训练的数据集较少[41]。我们发现,现有模型权重不能很好地转移到我们的所有训练数据集。因此,我们针对训练数据对 RAFT-3D 进行微调,但在评估期间使用已发布的检查点 [56]。 3D 运动估计的性能很大程度上取决于深度图质量。训练主要以高质量或真实深度进行。在对野外数据进行推理时,我们无法获得 Z1、Z2 的准确绝对比例单目深度。我们根据深度质量来消除运动估计和分割的性能。
Fusion
基于图像的检测器可以很好地解决分割和检测任务,但在运动分类上表现不佳。在训练数据有限的情况下,简单地使用单目视频数据进行运动分割是一项具有挑战性的任务。当使用运动作为中间数据表示(充当归纳偏差)时,该任务就可以解决。然而,为了稳健地分割具有语义意义的移动对象,将图像和运动数据结合在一起至关重要。因此,运动分割任务可以被视为多模态融合问题。
Transformer非常灵活 - 例如将Transformer适应视频实例分割只需要更改位置编码和很少的微调[13]。
这种灵活性是一个关键优势,因为它为将来使用更长的时间窗口留下了可能性。以类似的方式,我们添加特定于模态的位置编码,并组合来自多种模态的数据而不是时间帧。当使用多种模式时,我们将双流架构中的特征与专用参数 θ r g b 、 θ m o t i o n θ_{rgb}、θ_{motion} θrgb、θmotion 相结合。每个分支首先分别对其自己的模态进行训练,然后通过对两个分支进行微调来学习融合。我们尝试了多种方法来融合不同位置的信息。我们的不同流基于 SotA 分割架构 Mask2Former [14]。
Experiments


在我们的第一个实验中,我们专注于单一模式。
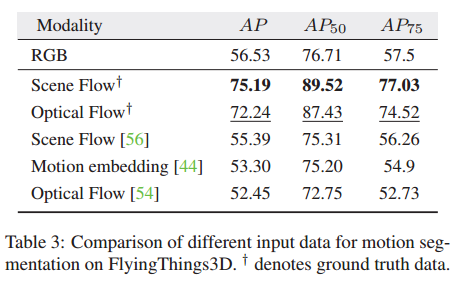
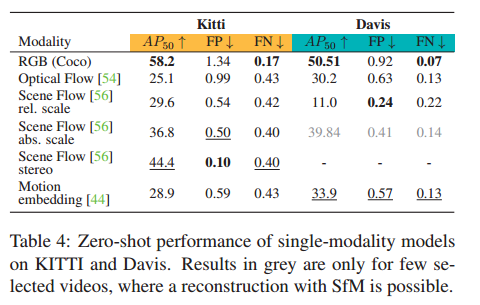
我们训练了 30 个 epoch,更多细节请参见 Suppl。秒。 7.1.表 3 显示了 FlyingThings3D 测试拆分的结果。我们使用 3D 输入数据获得了最佳结果,这表明 3D 运动使网络更容易学习任务,并且通常优于 2D 运动。
预测运动和真实运动之间的差距为现成的估计器留下了改进的空间。有趣的是,我们包括一个纯图像基线模型。我们可以在此数据集上训练强大的图像检测器,因为前景物体始终处于运动状态并且与背景不同。请注意,如果数据包含对象类(可以移动但不能移动),情况就不会如此。
稍后我们将看到,纯图像基线如何仅在不惩罚误报的指标上表现良好。
这篇关于On Moving Object Segmentation from Monocular Video with Transformers 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







