本文主要是介绍Hand Avatar: Free-Pose Hand Animation and Rendering from Monocular Video,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Github: https://seanchenxy.github.io/HandAvatarWeb
1、结构摘要
- MANO-HD模型:作为高分辨率网络拓扑来拟合个性化手部形状
- 将手部几何结构分解为每个骨骼的刚性部分,再重新组合成对的几何编码,得到一个跨部分的一致占用场
- 纹理建模:在MANO-HD表面设计了可驱动的anchor,记录反照率;定向软占用用于描述光线-表面关系,生成照明场,进一步用于解耦与姿态无关的反照率和与姿态相关的照明
2、重建方法
- 传统:纹理图、彩色网格。
- 蒙皮的方法很难为任意查询找到准确的蒙皮权重,而部分感知方法通常存在跨部分不一致问题
- 思路:(1)显示网格描述手型,MANO-HD(12337个顶点+24608个面);(2)局部占用场(PairOF):每两个部分级几何编码通过物理连接重新组装,以产生跨部分一致的场;(3)对于手部纹理,通过由反照率场和照明场组成的自遮挡感知阴影场(SeLF)计算纹理,反照率场通过MANO-HD表面的anchor(位置和反照率编码)模拟手部区域,照明场应对自遮挡。
3、Method
- MANO-HD 是一个通用的高分辨率手部网格模型,可以通过单目 RGB 视频数据拟合个性化手部形状。
- 关注详细的个性化纹理,包括反照率和照明。为了增强表面纹理表示,以显式网格为指导开发了局部表示。遵循局部建模范式,并使用重心采样在 MANO-HD 表面上均匀放置anchor以跟踪局部信息。
- 在关节自遮挡条件下专门对照明进行nerf建模。
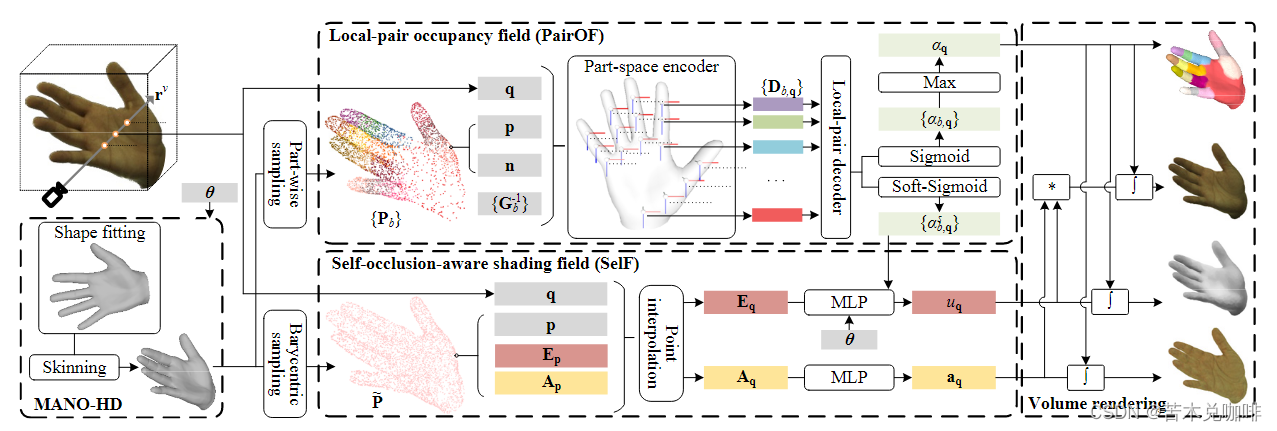
- MANO-HD
(1)细分网格(提升分辨率):在边缘的中间点添加定点统一细分MANO网格,增加顶点和面;添加顶点的蒙皮权重由其重要的顶点的平均值给出。为了消除蒙皮过程中的伪影,优化了上采样蒙皮权重以获得更好的动态性能。
(2)Shape Fitting:摆脱 β,使用MLP推导并细化形状。 - Local-Pair Occupancy Field
给定查询点x,PairOF预测占用值α。手表面:{q|αq = 0.5}。
(1)Part-Space Encoder:线划分手部网格,在网格上均匀采样得到点云,法线,并转换回规范空间通过PointNet提取几何特征。
(2)Local-Pair Decoder:作者认为划分的局部之间有很强的关系,基于 PointNet 的局部对解码器 Qpair 来融合每个配对编码并预测占用值,最后,通过融合part-level值获得全局占用值。 - Self-Occlusion-Aware Shading Field
给定query q,通过SelF(q)预测反照率和照明度
(1)对于视图方向上的光线投射,我们统一采样N个查询,每个查询具有占用场α、反照率a和光照值u。我们用立体渲染神经场: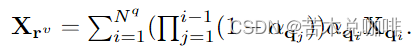
(2)Albedo Field:因为手部表面点是不变的,因此在MANO-HD表面固定anchor。在MANO-HD模板上均匀采样获得N个点的点云P,并用重心坐标表示它们(重心anchor更均匀,以覆盖手部表面)。然后,我们开发了随机初始化的反照率编码A,并将它们附加到锚点上。给定手部姿势,可以根据变形的顶点和固定的重心坐标重新采样锚点,形成变形点云P。对于查询 q,我们在P 中找到 n 个最近点,并使用逆欧几里得距离作为权重插值 A。因此,我们得到反照率编码 Aq,然后将其馈送到 MLP 以预测反照率值 aq,即 aq = Malbedo(Aq)。
(3)Directed Soft Occupancy:
对于自遮挡照明估计,我们需要骨骼部分的近远关系。也就是说,当 q 接近多个部分时,查询 q 的光照会受到自遮挡的影响。虽然占用值可以描述q和部分之间的关系,但值几乎是二进制的,因此只能描述内外关系。因此,在sigmoid函数中引入软因子τ,软化占用值:
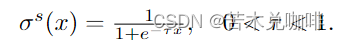
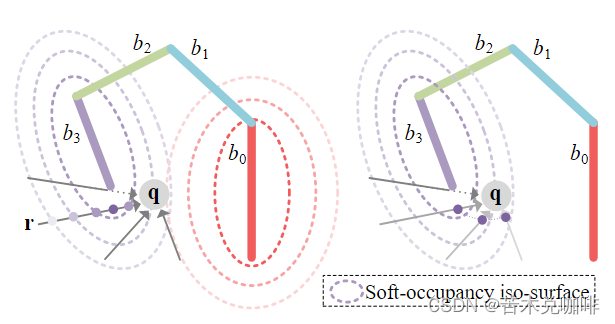
此外,作者设计了定向软占用来反映光线投射和铰接部分之间的近远关系,而不是对单个查询进行建模。对于可以达到 q 的光线投射 r,有向软占用 αs b,q,r 定义为光线命中 q 之前 r 的最大值。对于离散化,我们在光线投射 r 上统一采样查询 {qi}N qi=1,并将有向软占用计算为 αs b,q,r = max{αs b,qi |qi ≤ q},其中 qi ≤ q 选择光线在到达 q 之前遍历的查询。例如,下图中最深紫色查询的 αs b3,q,r 等于 αs b3。
(4)Illumination Field:当我们考虑了自遮挡的情况后,我们需要估计一个查询点的照明强度。这个强度受到许多因素的影响,包括光源分布、辐照度和反射。在这个问题中,我们关心的是辐照度,它表示能量到达一个特定点的数量。
为了解决这个问题,我们使用了两个关键线索:手部的姿态和查询点的位置。我们通过对这些信息进行编码,得到了关于姿态和位置的表征。
然而,自遮挡是一个复杂的问题。我们引入了一个被称为软因子 τ 的参数,将其加入到 Sigmoid 函数中,以柔化占用值。这个 Sigmoid 函数用于描述一个点是否被遮挡,软因子使得它的取值范围从0到1之间。
为了更好地处理自遮挡,我们引入了一个称为“有向软占用”的概念。它表示在一个射线方向上,能量被部分阻挡的程度。如果一条射线在到达查询点之前接近了多个部位,那么查询点的照明将受到自遮挡的影响。
我们选择了一组射线方向,使得它们能够到达查询点,并能描述所有关节部位的近-远关系。此外,我们还考虑到一个关节部位只会影响其周围的照明情况。
最终,我们使用一个多层感知器(MLP)来预测查询点的照明强度。这个预测过程涵盖了姿态信息、位置信息以及有向软占用作为输入,从而得到了查询点的照明强度估计值。
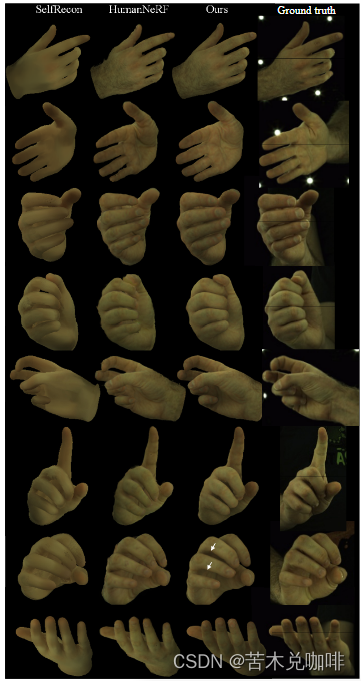
4、实验

可以看到,该方法重建的效果还是很好地:
这篇关于Hand Avatar: Free-Pose Hand Animation and Rendering from Monocular Video的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





