本文主要是介绍GEDepth:Ground Embedding for Monocular Depth Estimation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考代码:gedepth
出发点与动机
相机的外参告诉了相机在世界坐标系下的位置信息,那么可以用这个外参构建一个地面基础深度作为先验,后续只需要在这个地面基础深度先验基础上添加offset就可以得到结果深度,这样可以极大简化深度估计网络学习的难度,自然深度估计的性能就上去了。先不说这个深度估计的实际效果如何,但是这个将复杂的问题简单化的思路是可以借鉴的。但是这个鲁棒性如何就需要打问号了,BEV感知中外参的变化带来的问题依然很头疼。
方法设计
文章的核心内容部分在左上部分,也就是如何去构建地面基础深度,文中给出了两种地面深度生成的方法:内外参映射、地面坡度加内外参,自然第二种的精度更高。这个基础深度再同你过一个学习到的加权参数 M a t t e n M_{atten} Matten去调和基础深度和网络本身预测的深度
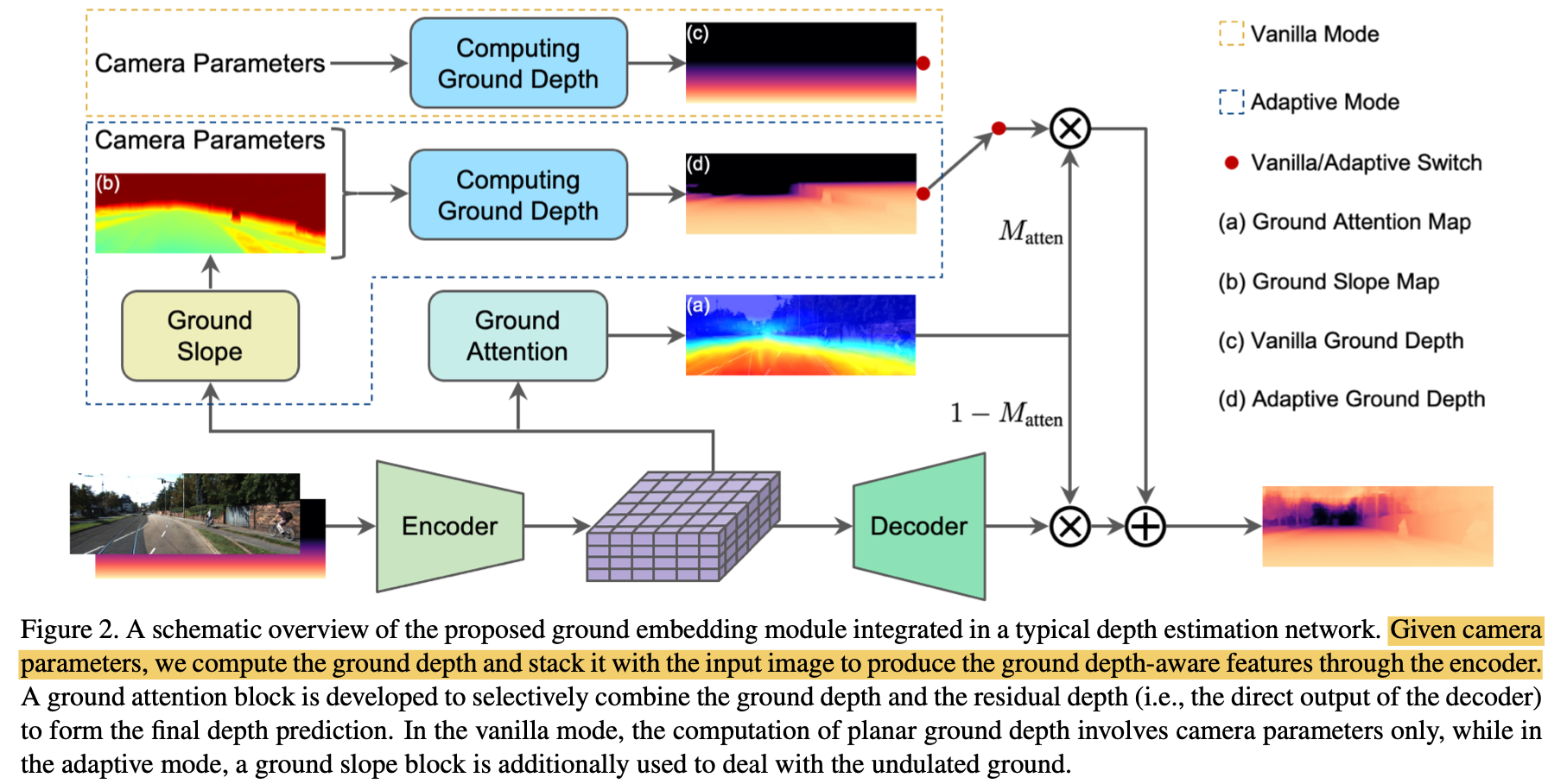
单纯由内外参估计地面深度
这个借助内外参可以在平直路面实现基础地面深度估计,什么路面坡度、障碍物什么的都不考虑,单纯计算地面的深度。其计算出来的效果如下

借助地面坡度预测细化地面基础深度
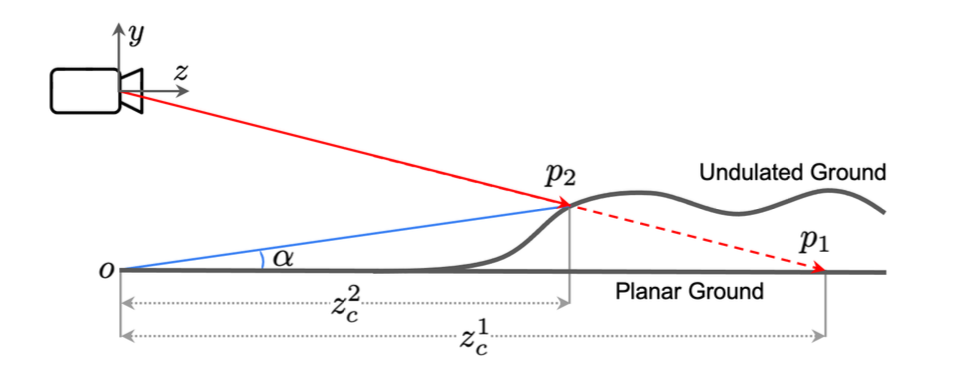
单纯依靠内外参得到的地面基础深度是相当粗糙的,完全不能用,那么可以借用下图定义的路面坡度 α \alpha α来细化路面的实际情况,这个坡度的计算自然也需要预先通过真值计算得到,相当于是对真值在不同的维度做了监督
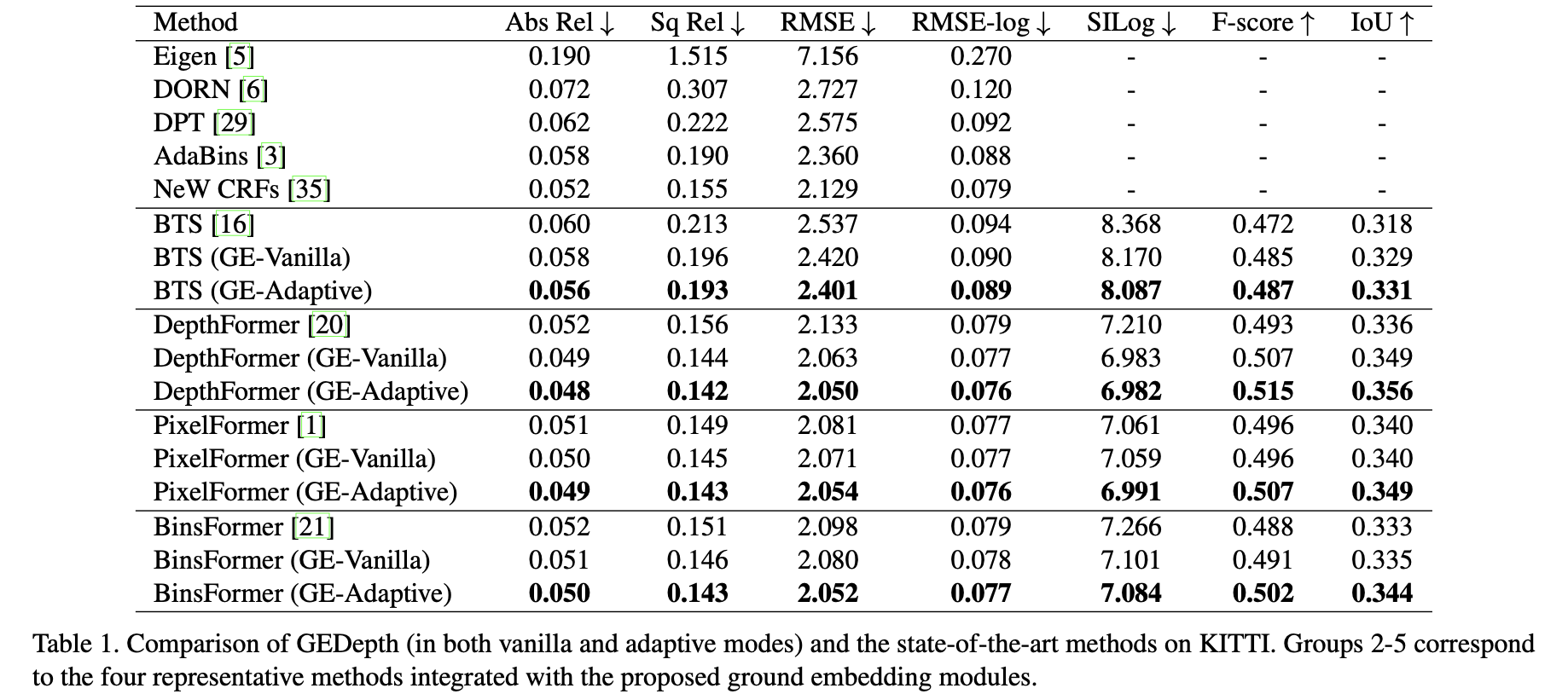
实验结果
KITTI上的性能比较:
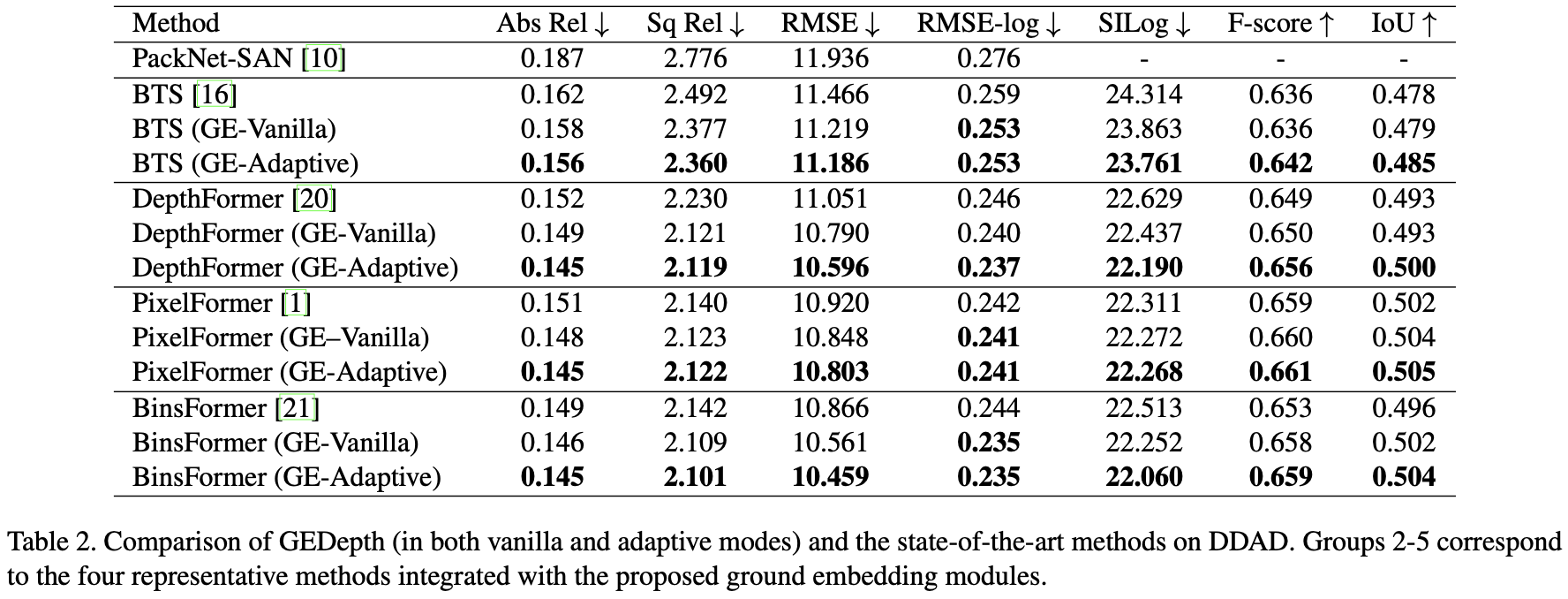
DDAD数据集:
这篇关于GEDepth:Ground Embedding for Monocular Depth Estimation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







