ground专题

《Programming from the Ground Up》阅读笔记:p95-p102
《Programming from the Ground Up》学习第6天,p95-p102总结,总计8页。 一、技术总结 1.directive(伪指令) 很多资料喜欢把directive和instruction都翻译成“指令”,这样在看到指令这个词时就不知道到底指的是什么?这里参考其它人的做法,将directive称为“伪指令”。 2.rept & .endr 语法: .rept

《Programming from the Ground Up》阅读笔记:p103-p116
《Programming from the Ground Up》学习第7天,p103-p116总结,总计14页。 一、技术总结 1.读写文件 (1)linux.s linux.s: #file name:linux.s# system call numbers(按数字大小排列,方便查看).equ SYS_READ, 0.equ SYS_WRITE, 1.equ SYS_OPEN,
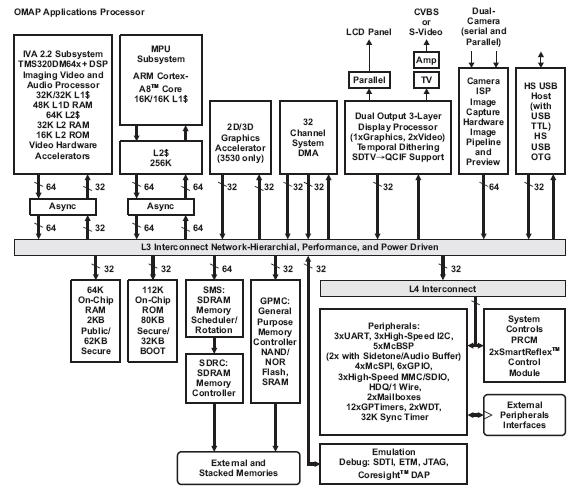
OpenGL embedded is gaining ground?
NV 6月份发布的Tegra: http://mobile.pconline.com.cn/news/hgxz/0806/1317151.html Ti 11 月发布的OMAP35X: http://live.csdn.net/Issue627/LivePlay.aspx
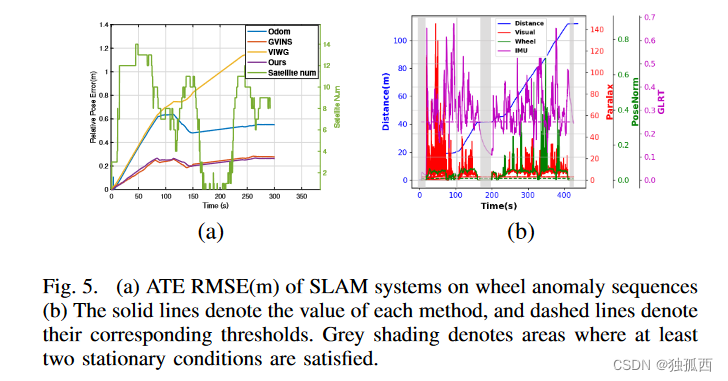
论文阅读:Ground-Fusion: A Low-cost Ground SLAM System Robust to Corner Cases
前言 最近看到一篇ICRA2024上的新文章,是关于多传感器融合SLAM的,好像使用了最近几年文章中较火的轮式里程计。感觉这篇文章成果不错,代码和数据集都是开源的,今天仔细读并且翻译一下,理解创新点、感悟研究方向、指导自己的研究。这篇文章通篇略读,主要做了工作做了一个紧耦合的RGBD - Wheel - IMUGNSS SLAM系统,然后加了两个创新点工作,一个是初始化,一个是传感器退化检测。
【Vuforia+Unity】AR04-地面、桌面平面识别功能(Ground Plane Target)
不论你是否曾有过相关经验,只要跟随本文的步骤,你就可以成功地创建你自己的AR应用。 官方教程Ground Plane in Unity | Vuforia Library 这个功能很棒,但是要求也很不友好,只能支持部分移动设备,具体清单如下: 01.Vuforia的地面识别功能仅支持的设备清单: Recommended Devices | Vuforia Library IOS
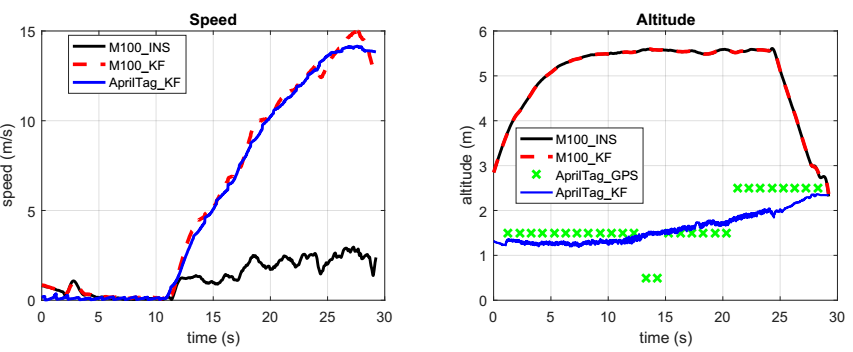
Autonomous Landing of a Multirotor Micro Air Vehicle on a High Velocity Ground Vehicle论文翻译
说明:本文为本人原创翻译,除了对原文进行翻译,还对部分知识点进行了拓展。未经允许,不得转载。 这篇论文在百度学术、谷歌学术等平台很容易就找到了,链接就不提供了。如果有翻译错误或者理解错误的地方,恳请看到的人及时指出,万分感激。 多旋翼飞行器在高速移动的地面交通工具上的自主降落 摘要:虽然自主多旋翼微型飞行器(MAV)对于某些需要固定悬停飞行能力的任

round sphere around ground background space-around space-between space-evenly
round sphere around ground background space-around space-between space-evenly round around ground surround round sphere around ground background around surround around evenly between space-around spa
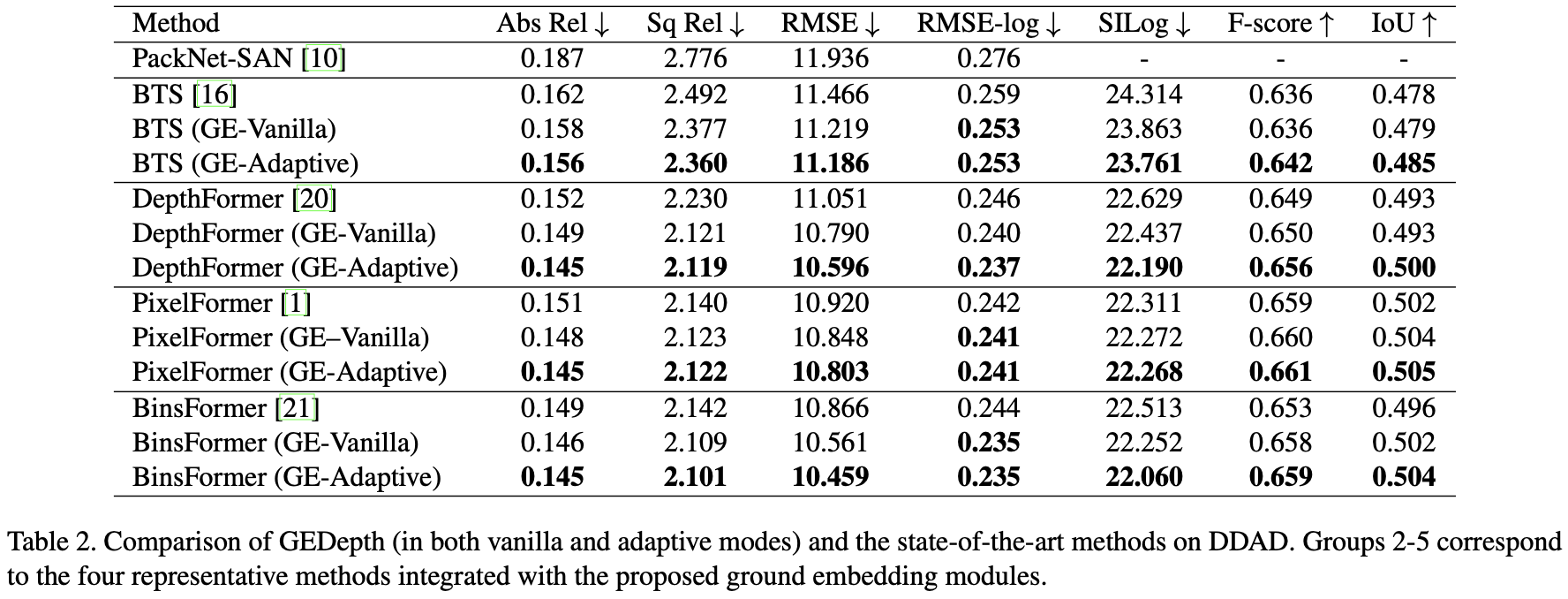
GEDepth:Ground Embedding for Monocular Depth Estimation
参考代码:gedepth 出发点与动机 相机的外参告诉了相机在世界坐标系下的位置信息,那么可以用这个外参构建一个地面基础深度作为先验,后续只需要在这个地面基础深度先验基础上添加offset就可以得到结果深度,这样可以极大简化深度估计网络学习的难度,自然深度估计的性能就上去了。先不说这个深度估计的实际效果如何,但是这个将复杂的问题简单化的思路是可以借鉴的。但是这个鲁棒性如何就需要打问号了,BEV感
使用labelme标注ground truth
step1:标注 直接在Anconda prompt 中输入 labelme 即可打开标注软件 Step2: json 转png 原文链接:https://blog.csdn.net/weixin_45437022/article/details/114751314?spm=1001.2101.3001.6650.3&utm_medium=distribute.pc_relevant.n
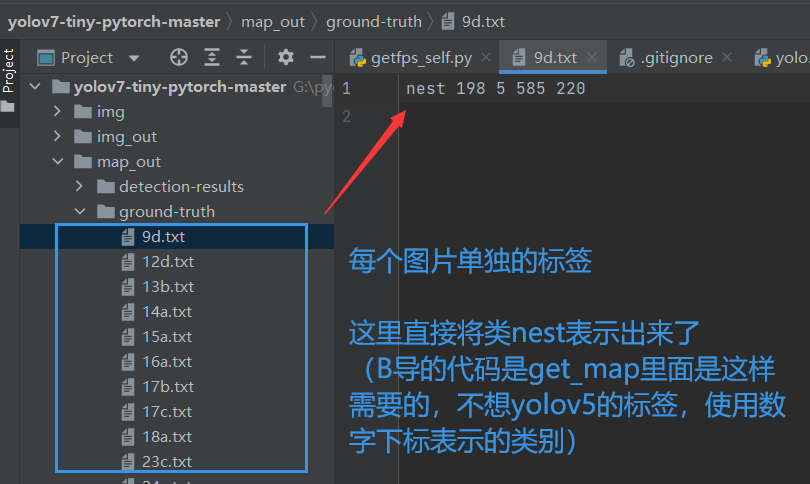
从B导的yolox、yolov7-tiny的标签中提取出来ground truth
原始的test.txt内容如下: 提取出来的内容如下: import osif __name__ == '__main__':# 将每行的内容单独读取到一个列表中with open('test.txt', 'r') as f: # 这个是Main里面的test.txt内容datalist = f.readlines()data = []for d in datalist:data

【点云学习系列】之Fast segmentation of 3d point clouds for ground vehicles
简介 在上一篇文章pcl学习系列之GroundSegmentation滤波(一)通过使用pcl库来回归拟合平面进行地面点提取,本篇博文介绍一篇2010年的快速地面点云分割算法,该论文链接:Fast segmentation of 3d point clouds for ground vehicles,当然,作者还是很赞的开源了代码,传送门Github。当然,我也调试作者的代码,同时进行一定的

浦项钢铁启用创业孵化器“CHANGeUP GROUND Pohang”
CHANGeUP GROUND Pohang志在成为亚洲的“新太平洋硅谷”浦项钢铁举行了“CHANGeUP GROUND Pohang”揭幕仪式,该孵化器的目标是扶持初创企业将积极向CHANGeUP GROUND的租户提供优质基础设施及项目浦项钢铁集团董事长Jeong-Woo Choi表示:“我们的管理理念——企业公民(Corporate Citizenship)——已作为新的文化认同而扎根。CH

ground truth 在深度学习任务中代表的是什么意思?
1、概念 在深度学习领域,ground truth (中文意思是“地面真实值”或“基准真实值”,简单理解就是真实值) 是指用于训练和评估模型的准确标签或数据。它是机器学习算法的参考标准,用于衡量模型的性的和判断模型的准确性,本文将介绍 “ground truth” 在深度学习中的应用。 2、在深度学习中的作用 在深度学习任务中,我们通常需要训练一个模型来预测输出 输入数据的某些属性或标签。

读论文:CNN for Very Fast Ground Segmentation in Velodyne LiDAR Data
https://arxiv.org/pdf/1709.02128v1.pdf 提取地面点的传统方法是基于特征(强度,几何)。有一定局限性,比如地面起伏大的时候。 而这篇文章用FCN的方法训练提取地面点,这种方法其实是像素级别的语义分割,也可以用在别的物体的分类上。 具体以后补。
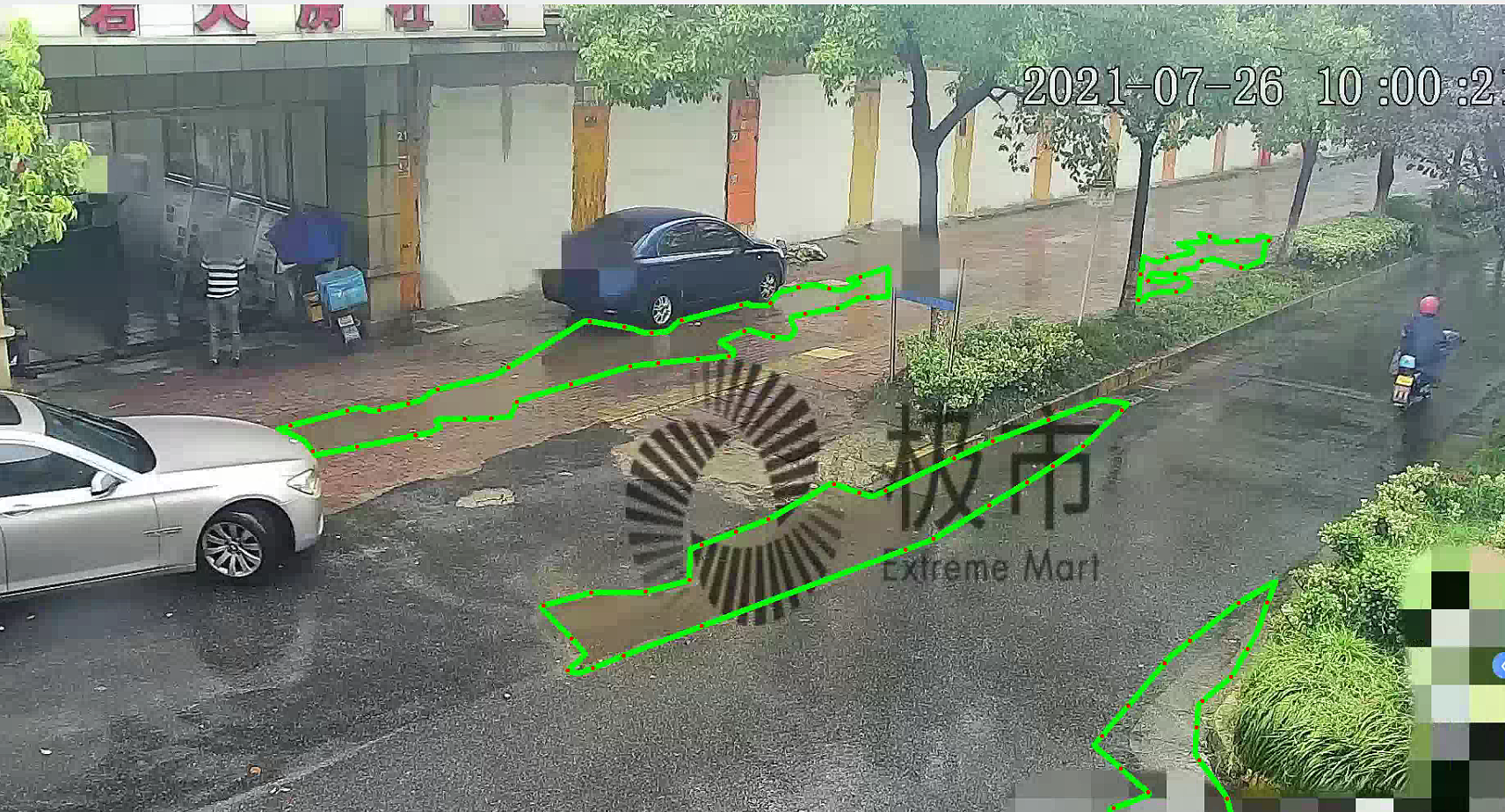
基于语义分割Ground Truth(GT)转换yolov5图像分割标签(路面积水检测例子)
基于语义分割Ground Truth(GT)转换yolov5图像分割标签(路面积水检测例子) 概述 随着开发者在issues中对 用yolov5做分割任务的呼声高涨,yolov5团队真的在帮开发者解决问题,v6.0版本之后推出了最新的解决方案并配指导教程。 之前就有使用改进yolo添加分割头的方式实现目标检测和分割的方法,最新的v7.0版本有了很好的效果,yolov8在分割方面也是重拳出
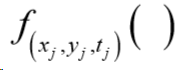
【论文阅读】Geographically and temporally weighted neural networks for ground-level PM2.5
Abstract: 气溶胶光学厚度AOD数据(aerosol optical depth)和地面观测站数据构成了对PM2.5的可靠量测,一般的 AOD-PM2.5关系都是使用线性模型进行模拟的。使用深度学习的方法可以模拟非线性关系,但是没有考虑空间因素。本实验使用中国地区的satellite AOD products、NDVI data 、meteorological factors 和stat

CVPR2023 I NeRF-Supervised Deep Stereo:不需要任何ground-truth数据
论文题目:NeRF-Supervised Deep Stereo 作者:Fabio Tosi ;Alessio Tonioni; Daniele De Gregorio等人 作者机构:University of Bologna(博洛尼亚大学);Google Inc(全球最大的搜索引擎之一);Eyecan.ai(韩国专注于开发眼动追踪技术的公司) 在公众号「3D视觉工坊」后台回复「原论文」,可获