本文主要是介绍【论文阅读】Geographically and temporally weighted neural networks for ground-level PM2.5,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract:
气溶胶光学厚度AOD数据(aerosol optical depth)和地面观测站数据构成了对PM2.5的可靠量测,一般的 AOD-PM2.5关系都是使用线性模型进行模拟的。使用深度学习的方法可以模拟非线性关系,但是没有考虑空间因素。本实验使用中国地区的satellite AOD products、NDVI data 、meteorological factors 和station PM2.5 measurements 作为输入数据,得到非地面观测站区域的数据(也许从某种意义上说算是一种插值方法),并在此基础上得到分辨率为0.1°的PM2.5 区域数据
Introduction
global modeling和spatio-temporal modeling是两种对PM2.5的描述方法。global modeling(LR, MLR, SEM, machine learning models)不随时间和地点变化,在所有研究区域都使用相同的系数;spatiotemporal modeling使用随时间和空间变化的系数,考虑到了AOD-PM2.5之间关系的时空动态性。本文的目标是在机器学习中综合时空异质性建立时空动态的AOD-PM2.5非线性模型
也就是建立geographically and temporally weighted neural networks (GTWNNs)
Study region and data
站点数据:中国地区2015年全年的小时级PM2.5数据进行逐日平均
卫星数据:MODIS C6 Terra 和 Aqua AOD的 AOD_550_Dark_Target_Deep_Blue_Combined_Mean_Mean产品,10km分辨率(AOD产品详情),两种AOD产品直接取值或者求平均。此外NDVI用以反映土地利用情况
气象数据:NASA的重分析数据MERRA-2,空间分辨率为0.625° longitude × 0.5° latitude,变量包括 wind speed、air temperature、relative humidity、surface pressure 以及 planetary boundary layer height
数据预处理和匹配:目的是获取时间和空间一致的数据集。
1、统一投影到同一个坐标系 2、线性方法重采样到 0.1 degree 3、提取地面站点所在位置的卫星和气象数据
GTWGRNN model
模型结构的数学表示如下:
![]()
其中![]() 代表在格网 j 的PM2.5预测值,即位置
代表在格网 j 的PM2.5预测值,即位置![]() 以及年天数 j 。为以地面PM2.5作为输入的时空函数,使用的是generalized regression neural network (GRNN)模型
以及年天数 j 。为以地面PM2.5作为输入的时空函数,使用的是generalized regression neural network (GRNN)模型
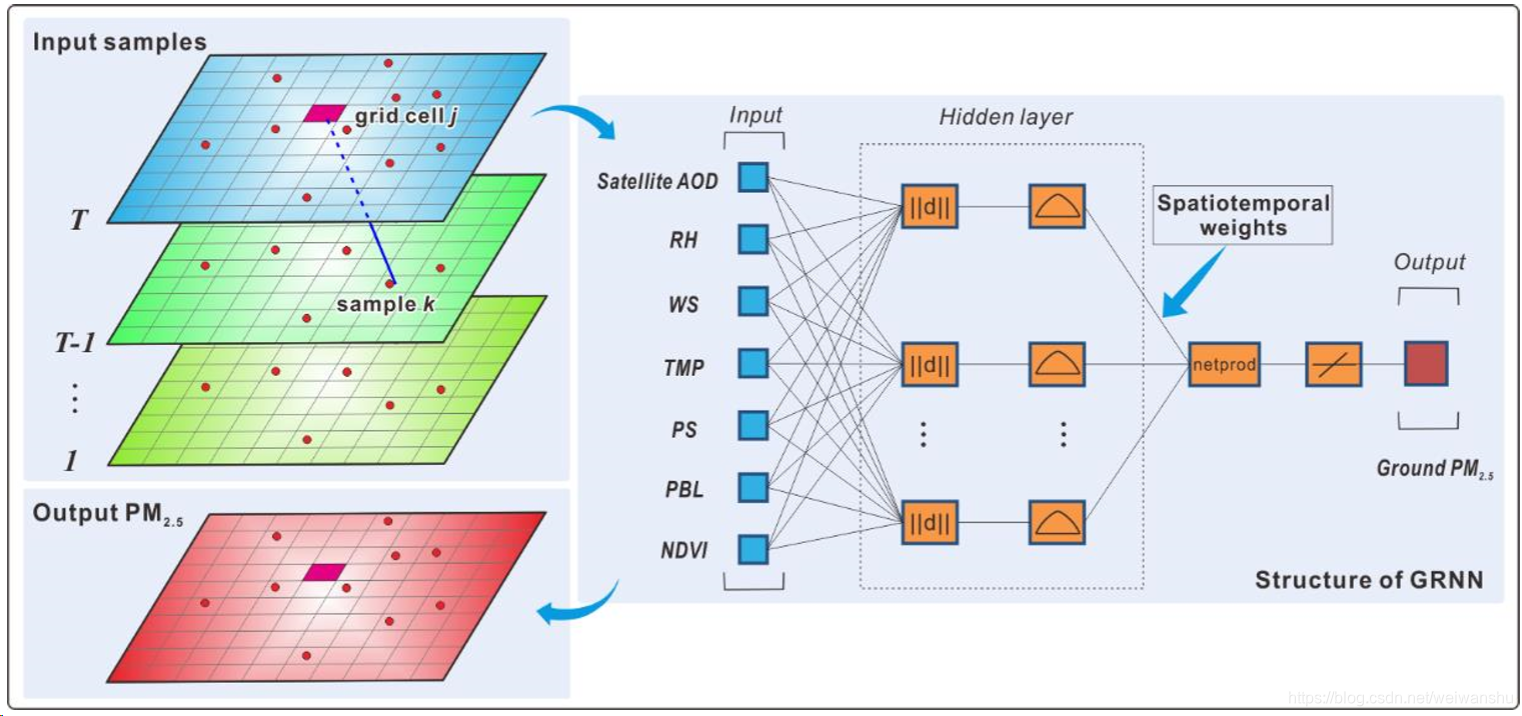
分成三层:
1、输入层:satellite AOD, RH, WS, TMP, PS, PBL 以及NDVI等
2、隐藏层:其神经元数量与构建GRNN模型的样本数量相同
3、汇总层:only one node
样本选择(地理和时间权重)
为了体现时空差异性,引入了地理和时间权重的概念,具体体现在
① 使用第 T 天以及之前天数的数据
② 使用 Gaussian distance decay-based weighting function 来衡量在时空维度 k 样本对 prediction grid cell j 的重要性,即

ds 和 dt 是 k 对 prediction grid cell j 的时空距离;
λ 平衡时空作用;λ = 0 时表示时间距离不产生影响,λ = ∞ 时表示只有时间产生影响;
hst 表示 k 样本对 prediction grid cell j 的衰减带宽
目前,在构建![]() 时只考虑权值大于 1E-6的样本点
时只考虑权值大于 1E-6的样本点
参数选择
cross-validation technique 来选择 λ 和 hst 的值。
还涉及到固定带宽(最邻近点数发生变化)还是可变带宽(最邻近点数不发生变化)的问题,本研究使用的是adaptive bandwidth
Model evaluation
常用的方法是10 fold cross-validation technique,又可以分成sample-based和site-based两种,其划分方式不太相同
① sample-based cross-validation:samples were divided into 10 folds
效果:reflect the overall predictive ability
② site-based cross-validation:the grid cells containing monitoring sites ( the “site” here refers to “grid cell”)
效果: the spatial prediction performance more reasonably.
结果
这篇关于【论文阅读】Geographically and temporally weighted neural networks for ground-level PM2.5的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
