temporally专题
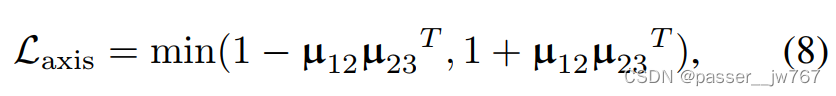
【计算机图形学】3D Implicit Transporter for Temporally Consistent Keypoint Discovery
对3D Implicit Transporter for Temporally Consistent Keypoint Discovery的简单理解 文章目录 1. 现有方法限制和文章改进2. 方法2.1 寻找时间上一致的3D特征点2.1.1 3D特征Transporter2.1.2 几何隐式解码器2.1.3 损失函数 2.2 使用一致特征点的操纵 1. 现有方法限制和文章改

Automatic Temporally Coherent Video Colorization
系列文章目录 视频着色领域相关论文 《一》 文章目录 前言 一、着色概述 二、相关方法 1.基于涂鸦的方法 2、基于参考的方法 3、基于学习的方法 三、网络框架 1、生成器 2、鉴别器 四、结果分析 总结 前言 视频及图像的着色(Colorization)技术旨在为单张或多个序列的灰度图像添加颜色,使彩色图像具有感知意义和视觉吸引力。随着深度学习技术在计算
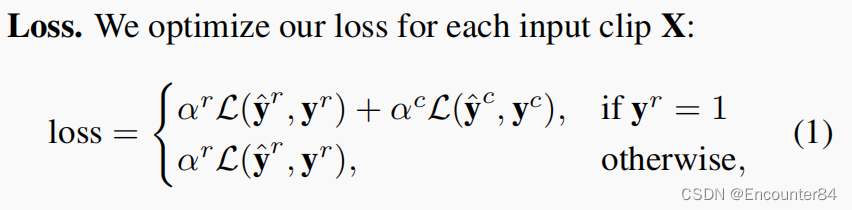
TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks论文阅读笔记
Abstract 由于未修剪的视频占用大量的内存空间,目前SOTA的TAL方法使用了预先处理好的视频特征。这些特征是从视频编码器中提取出来的,它们通常被用于动作分类任务的训练,这使得这些特征不一定适合于时序动作检测。在这项工作中,我们提出了一种新的用于视频片段特征的有监督预训练范式,它不仅训练活动分类活动,还考虑背景剪辑和全局视频信息,以提高时间敏感度。大量的实验表明,使用我们的新的预训练策略训

(CVPR2021) Video MoCo: Contrastive Video Representation Learning with Temporally Adversarial Example
使用对抗的方法,引入了对于时序robust的正样本,具体方式为使用lstm随机drop掉video clip中的一些帧,同时由于负样本的队列中,越早进入的样本与正样本的差距越大,故给队列中的负样本一个权重系数(小于1),越新的样本权重越大。 损失函数: 生成器: 判别器: 实验结果: 结论:
![[論文筆記] Monocular Pose Estimation of 3D Objects using Temporally Consistent Local Color Histograms](https://img-blog.csdn.net/20180914044107931?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Rlbm5pc19MZWVf/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[論文筆記] Monocular Pose Estimation of 3D Objects using Temporally Consistent Local Color Histograms
Real-Time Monocular Pose Estimation of 3D Objects using Temporally Consistent Local Color Histograms 這是小弟第一篇論文筆記,將來應該會每週更新一篇論文筆記,自己還很菜,文中有些基礎部分知識還沒理解的部分會略過,有機會的話會再補足,若內文有錯誤還請各位多多包涵不吝指正。 背景介紹: 實踐中
【论文阅读】Geographically and temporally weighted neural networks for ground-level PM2.5
Abstract: 气溶胶光学厚度AOD数据(aerosol optical depth)和地面观测站数据构成了对PM2.5的可靠量测,一般的 AOD-PM2.5关系都是使用线性模型进行模拟的。使用深度学习的方法可以模拟非线性关系,但是没有考虑空间因素。本实验使用中国地区的satellite AOD products、NDVI data 、meteorological factors 和stat

Mobile Video Object Detection with Temporally-Aware Feature Maps
Mobile Video Object Detection with Temporally-Aware Feature Maps 来源: 谷歌,CVPR 2018 文章链接:https://arxiv.org/abs/1711.06368v2 最新研究 CVPR2019(在此基础上进一步提升速度):https://arxiv.org/abs/1903.10172 代码:https://githu
Conditional Generation of Temporally-ordered Event Sequences翻译
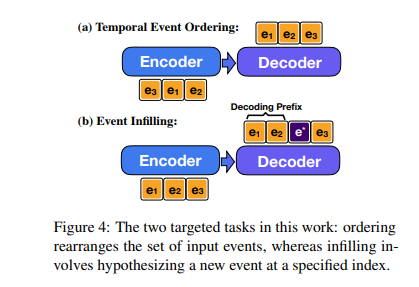
摘要 叙事结构知识模型已被证明可用于一系列与事件相关的任务,但它们通常无法捕捉事件之间的时间关系。我们提出了一个单一模型,既可以解决时间排序问题,即将给定的事件按照它们发生的顺序进行排序,也可以解决事件填充问题,即预测适合现有时间顺序序列的新事件。我们使用基于 BART 的条件生成模型,该模型可以同时捕获时间性和常见事件,这意味着它可以灵活地应用于该空间中的不同任务。我们的模型被训练为去噪自编码
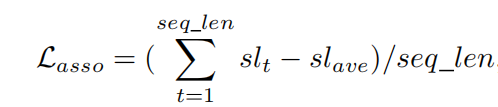
Temporally Identity-Aware SSD with Attentional LSTM 论文学习
多目标跟踪常用的是tracking by detection,这种方法就是将每帧中所有感兴趣的目标物体均检测出来,然后与前一帧检测出来的目标进行关联,从而实现跟踪效果。这种方法的前提就是要拥有一种表现好的目标检测算法还有好的关联方法。 具体流程是: step1:使用目标检测算法将每帧中感兴趣的目标检测出来,得到对应的(坐标,分类,可信度),假设检测出来的目标个数为M step2:通过某种方式
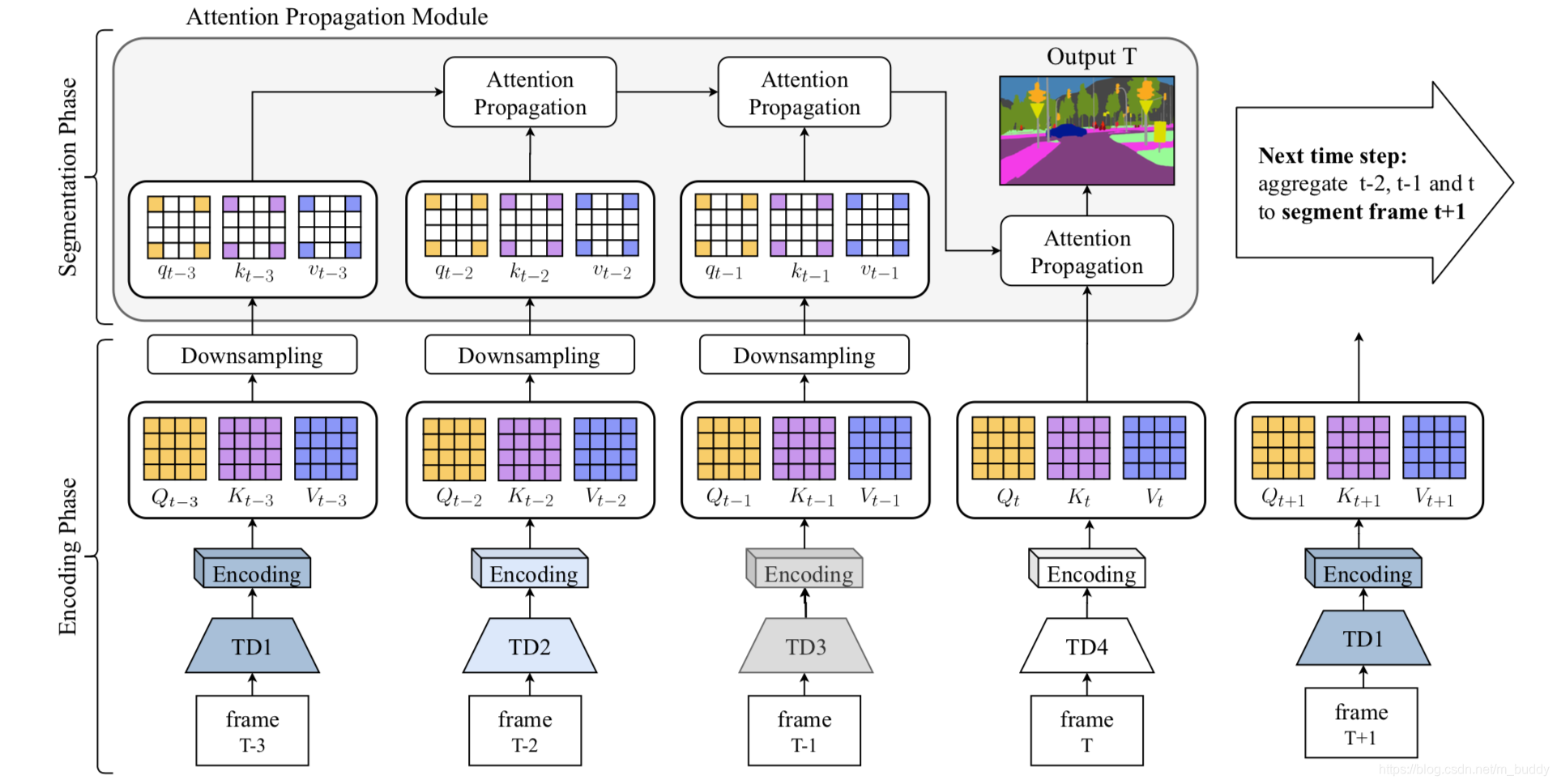
《TDNet:Temporally Distributed Networks for Fast Video Semantic Segmentation》论文笔记
代码地址:TDNet 1. 概述 导读:这篇文章提出了一个基于时序分布网络的视频语义分割算法TDNet(Temporally Distributed Network),它的设计思想来自于这么一个观察:较深的网络输出的特征是可以由一系列的浅层网络输出的特征进行组合得到。而在视频分割任务中视频是具有时序属性的,而且视频分割也是有时序属性的,因而就可以在一定的时序范围内使用浅层的网络进行特征抽取,
Mobile Video Object Detection with Temporally-Aware Feature Maps(具有时间感知特征映射的移动视频目标检测)
英文原文 摘要 本文介绍了一种用于视频中物体检测的在线模型,该模型旨在在低功率移动和嵌入式设备上实时运行。 我们的方法将快速的单图像目标检测模型与卷积长短期记忆(LSTM)层相结合,创造了混合的循环卷积体系结构。 此外,我们提出了一个有效的Bottleneck-LSTM层,与常规LSTM相比,可显着降低计算成本。 我们的网络通过使用Bottleneck-LSTM在帧间精化和传播特征图来实现时间

【论文翻译】Mobile Video Object Detection with Temporally-Aware Feature Maps
写在前面 来源: 谷歌,CVPR 2018 文章链接:https://arxiv.org/abs/1711.06368v2 最新研究 CVPR2019(在此基础上进一步提升速度):https://arxiv.org/abs/1903.10172 我的翻译:https://blog.csdn.net/u014386899/article/details/102475750 代码:htt
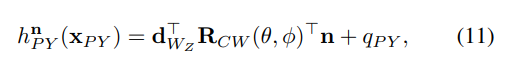
经典文献阅读之--Online Extrinsic Camera Calibration for Temporally Consistent IPM (IPM外参标定)
0. 简介 对于视觉而言,如何使用鸟瞰图来完成车道线的识别和标定是非常重要的,对于鸟瞰图来说,其实有很多种,之前读者的博客中也已经提到过《逆透视变换(IPM)多种方式及代码总结》、《IPM 鸟瞰图公式转换与推导》。这个当然内容还是不太详细,对于各位想要复现难度会比较大,这个时候可以看一下《单应矩阵的推导与理解》这篇文章的详细推导。其实只需要知道精确的外参和内参,以及相机的高度,以及期望的W和H(