本文主要是介绍《TDNet:Temporally Distributed Networks for Fast Video Semantic Segmentation》论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码地址:TDNet
1. 概述
导读:这篇文章提出了一个基于时序分布网络的视频语义分割算法TDNet(Temporally Distributed Network),它的设计思想来自于这么一个观察:较深的网络输出的特征是可以由一系列的浅层网络输出的特征进行组合得到。而在视频分割任务中视频是具有时序属性的,而且视频分割也是有时序属性的,因而就可以在一定的时序范围内使用浅层的网络进行特征抽取,之后在经过组合可以达到深层网络输出特征的效果。这样的思路迁移也是相当简单的,那么怎么来实现文章中说的将多个浅层特征进行组合呢?文章对此的解决办法是使用一个新的APM(attention propagation module)来实现,减少分割目标移动对分割性能的影响。此外,还引入了知识蒸馏的概念,从使其可以在浅层网络输出特征与组合特征的两个层面进行知识迁移,从而提升学生网络的性能。文章的方法在Cityscapes/CamVid/NYUD-v2数据集上取得了不错的效果,不过说是视频分割怎么没有DAVIS呢-_-||?
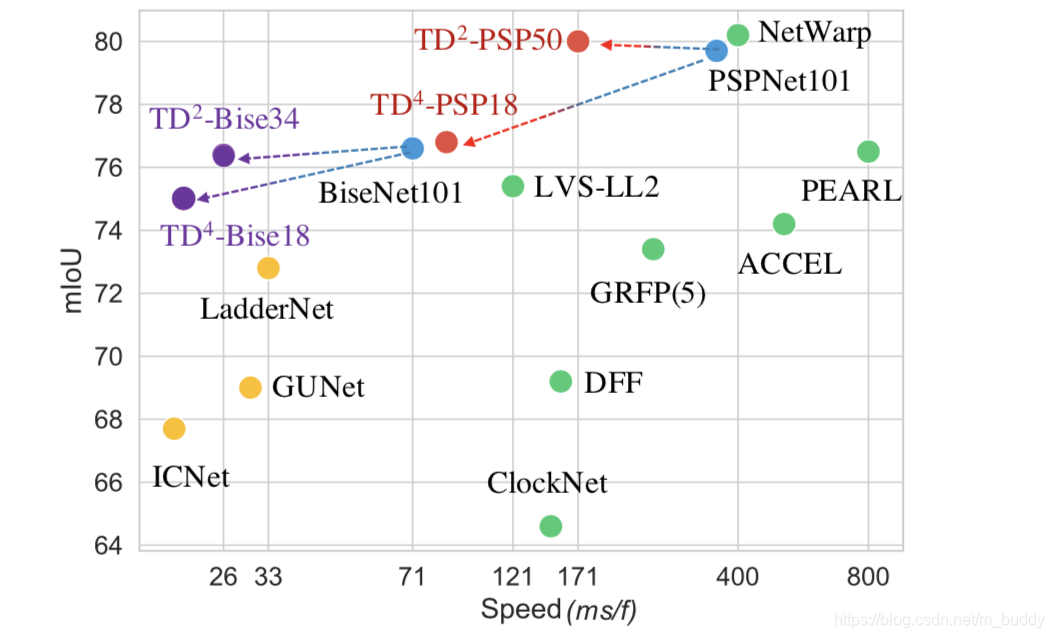
这篇文章使用 N N N(每个子网络是原始网络尺寸的 1 N \frac{1}{N} N1)个子网络去构建文章提到的特征抽取网络组,之后再将这些子网络的结果进行组合得到最后用于分割的特征图,组合部分使用了文章提出的APM(attention propagatuion module)的方式进行,从而减少分割目标运动对分割带来的影响。在inference的时候由于利用了视频帧时序上的特点,因此当前帧只需要用子网络进行infer之后将这个特征与之前的 N − 1 N-1 N−1个特征组合,之后进行分割,因而速度来所是很快的,就是需要消耗部分存储空间。其性能在Cityscapes数据集上与其它一些方法的比较见下图1所示:
2. 方法设计
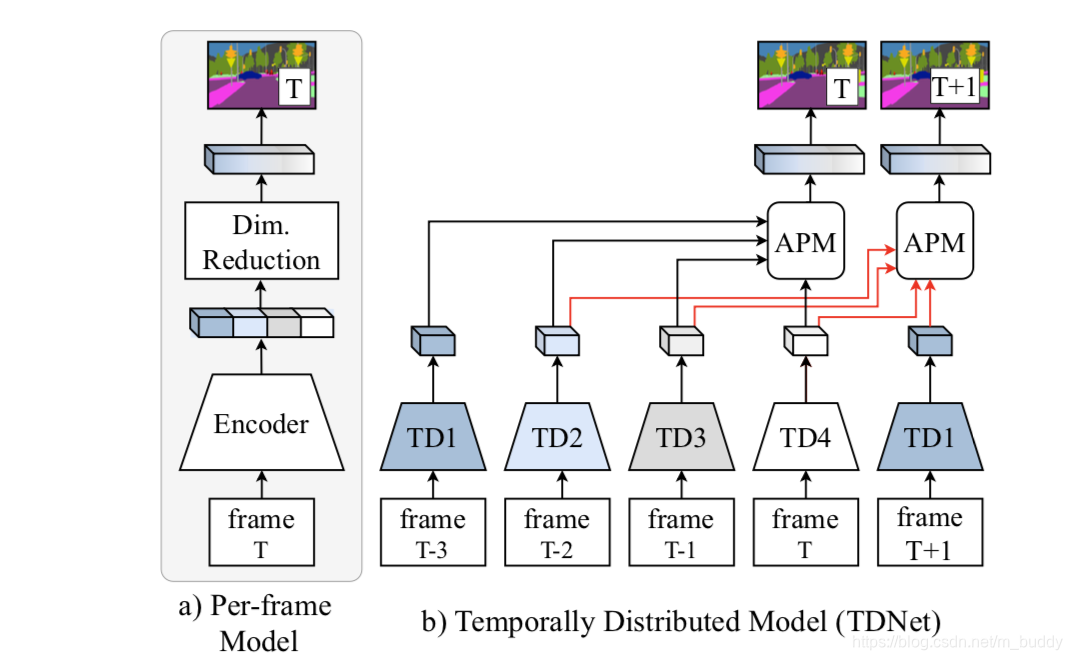
2.1 原始网络拆分
现有的一些文献表明基于分组的卷积能在减少计算量的同时获取较好的性能,而传统分割网络中为了更好的性能会采用较深的特征抽取网络结构,这部分是相当耗时的。并且有相应的文章指出使用特征组合也能使用小网络获得大网络性能匹配的特征,因而文章将之前的大网络进行拆分,之后使用文章的APM模块进行融合,从而进一步减少计算量,则传统的特征抽取网络与文章提出的特征抽取网络其结构对比见下图所示:
2.2 子网络组成特征的融合
由于视频时序中存在目标的移动情况,这就会导致子网络处理的图片其中的目标像素是不能对齐的。虽然像光流这样的方式可以进行弥补,但是其计算开销较大/结果存在误差/具有限制等。文章对此是提出了一个基于non-local注意力机制的APM模块去解决对齐的问题,将APM集成到文章的网络中其结构见下图所示:
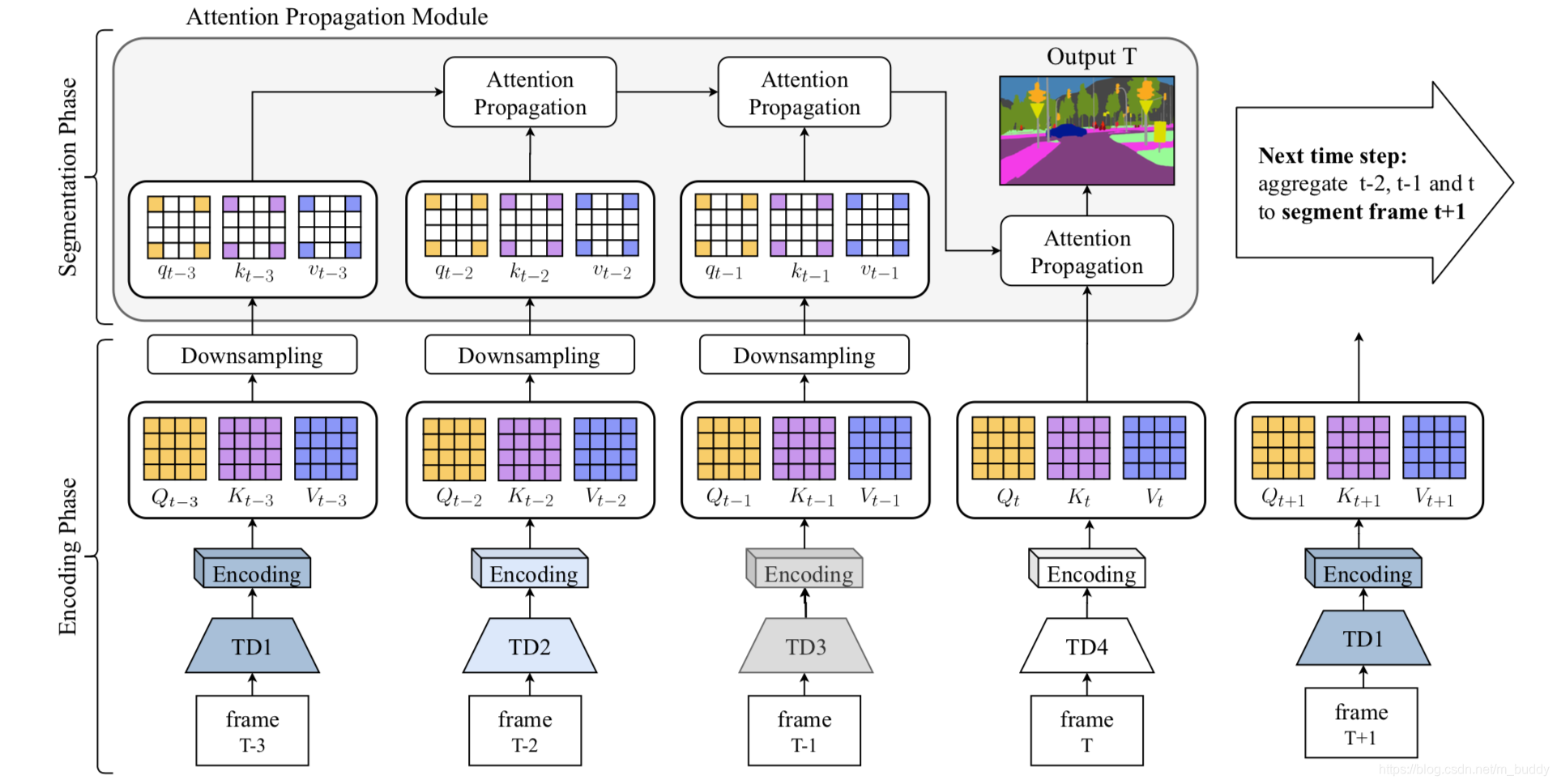
从上图中可以看出文章将网络划分为了两个阶段:编码阶段和分割阶段。
- 1)编码阶段:这里使用子网络进行特征抽取,得到特征图 X i ∈ R C ∗ H ∗ W X_i\in R^{C*H*W} Xi∈RC∗H∗W,之后使用一个编码单元(使用 1 ∗ 1 1*1 1∗1的卷积层)将这个特征图转换得到3个特征图: V i ∈ R C ∗ H ∗ W , Q i ∈ R C 8 ∗ H ∗ W , K i ∈ C 8 ∗ H ∗ W V_i\in R^{C*H*W},Q_i\in R^{\frac{C}{8}*H*W},K_i\in^{\frac{C}{8}*H*W} Vi∈RC∗H∗W,Qi∈R8C∗H∗W,Ki∈8C∗H∗W,前一个特征用于提供丰富的分割语义信息,后面的两个特征图用于时序对齐和注意力机制使用。
- 2)分割阶段:这里前 m − 1 m-1 m−1个子网络的特征进行attention操作,通过相邻帧之间attention传导的形式优化特征图,之后在当前帧使用分割层分割得到最后的结果。
在文章中所使用的子网络数目为 m = 4 m=4 m=4,因而这里使用空间时序注意力机制将当前帧与前面的 m − 1 m-1 m−1帧数据建立空间关系,因而当前帧与之前帧之间的相关性可以描述为:
这篇关于《TDNet:Temporally Distributed Networks for Fast Video Semantic Segmentation》论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






