本文主要是介绍Mobile Video Object Detection with Temporally-Aware Feature Maps(具有时间感知特征映射的移动视频目标检测),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
英文原文
摘要
本文介绍了一种用于视频中物体检测的在线模型,该模型旨在在低功率移动和嵌入式设备上实时运行。 我们的方法将快速的单图像目标检测模型与卷积长短期记忆(LSTM)层相结合,创造了混合的循环卷积体系结构。 此外,我们提出了一个有效的Bottleneck-LSTM层,与常规LSTM相比,可显着降低计算成本。 我们的网络通过使用Bottleneck-LSTM在帧间精化和传播特征图来实现时间感知。 这种方法比现有视频检测方法快得多,在模型尺寸和计算成本方面优于最快的单帧模型,在Imagenet VID 2015数据集上获得了与更复杂的单帧模型相当的精度。 我们的模型在移动CPU上实现高达15 FPS的实时推断速度。
1. Introduction
卷积神经网络[24,35,36,12]已经在先进的单图像目标检测技术[8,11,32,28,4]上确立了坚实的地位。 然而,大存储开销和这些网络的计算时间慢限制了他们的实际应用。 特别是,效率是首要考虑因素在设计适用于移动和嵌入式平台的模型时。 最近,新的结构 [17,40]允许神经网络低算力运行并且有竞争力的表现在单图像目标检测中。但是,视频领域出现了额外的机会和挑战--利用时间线索,目前还不清楚如何为视频制作一个相对有效的检测框架场景。 本文研究了通过单帧模型通过添加时间感知来构建检测模型的想法同时保持其速度和低资源消耗。
视频包含各种时间线索,可用于获得比单个图像更准确和稳定的物体检测。 由于视频表现出时间连续性,相邻帧中的对象将保持在相似的位置,并且检测不会显着变化。 因此,来自较早帧的检测信息可用于改进当前帧的预测。 例如,自从网络能够跨帧查看不同姿势的对象,它可以更准确地检测对象。 随着时间的推移,网络对预测也会变得更加自信,减少了单图像物体检测中的不稳定问题[37]。
最近的研究表明,这种连续性延伸到了特征空间,从相邻视频帧中提取的中间特征图也是高度相关的[43]。 在我们的工作中,我们感兴趣的是在特征空间中添加时间感知,而不是仅在最终检测中添加,因为中间层中可用的信息量更大。 我们通过循环网络架构调整来自先前帧的相应特征映射上的每个帧的特征映射来利用特征级别的连续性。
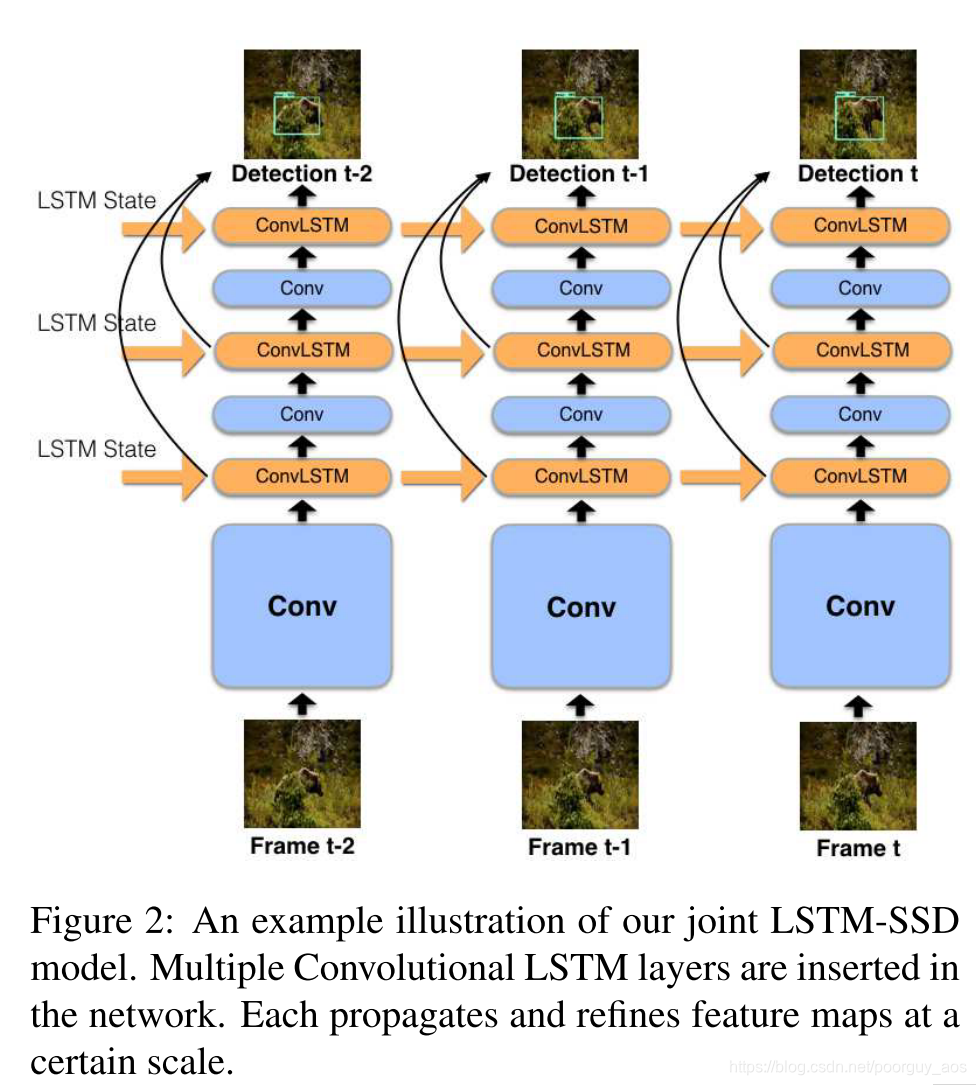
我们的方法通过联合卷积递归单元生成特征图,该联合卷积递归单元通过将标准卷积层与卷积LSTM组合而形成。 目标是卷积层输出特征映射假设,然后将其馈送到LSTM并与来自先前帧的时间上下文融合以输出精确的,时间上感知的特征映射。 图2显示了我们的方法。 这种方法使我们能够从有效静止图像对象检测的进步中受益,因为我们可以使用我们的卷积 - 循环单元简单地扩展这些模型中的一些卷积层。 循环层能够跨帧传播时间线索,允许网络在处理视频时访问越来越多的信息。
为了证明我们模型的有效性,我们评估了Imagenet VID 2015数据集[33]。 我们的方法优于有效的单帧baselines,我们认为这种改进必须归功于时间上下文的成功利用,因为我们没有增加任何额外的判别力。 我们提供的模型变体范围从200M到1100M的乘法增加和1到350万个参数,可以直接在各种移动和嵌入式平台上部署。 据我们所知,我们的模型是第一个用于视频对象检测的移动优先神经网络。
本文的贡献如下:
•我们引入了统一的架构,用于在需要最少计算资源的视频中执行在线对象检测。
•我们提出卷积体系中循环层的新角色作为特征映射的时间细化。
•通过将卷积LSTM修改为高效,我们证明了在以效率为中心的网络中使用循环层的可行性。
•我们提供实验结果来证明我们的设计决策,并将我们的最终架构与各种单图像检测框架进行比较。
2.Related Work
2.1 Object Detection in Images
最近的单图像对象检测方法可以分为两类。 一类包括由R-CNN [8]及其后代[7,32,16]推广的基于区域的两阶段方法。 这些方法通过首先提出对象区域然后对每个区域进行分类来执行推断。 或者,单发方法[28,31,4,26]通过在固定锚位置处产生预测来在单次通过中执行推断。 由于其效率和竞争准确性,我们的工作建立在SSD框架之上[28]。
2.2. Video Object Detection with Tracks
Imagenet VID数据集上的许多现有方法将单帧检测组织为轨道或小管,并使用后处理更新检测。 Seq-NMS [10]将高可信度预测链接到整个视频的序列。 TCNN [22,23]使用光流将检测映射到相邻帧并抑制低置信度预测,同时还结合了跟踪算法。 但是,这些方法都不执行实时推理,也不关注效率。
我们的方法不是在最终检测结果上运行,而是直接在特征级别上结合时间上下文,不需要后处理步骤或在线学习。 由于我们的方法可以通过将任何这些方法应用于我们的检测结果来扩展,因此我们的网络与这些方法使用的基本单帧检测器相比,比只使用这些方法本身更具可比性。
最近的一项工作,D&T [6],通过在帧对上添加RoI跟踪操作和多任务损失来结合跟踪和检测。 然而,他们的实验侧重于昂贵的高精度模型,而我们的方法专为移动环境量身定制。 即使采用积极的时间跨步,由于Resnet-101基础网络的成本,它们的模型无法在移动设备上运行,这需要比我们的大型模型多79倍的计算,比我们的小型计算机高出450倍。
2.3. Video Object Detection with Optical Flow
为2017年Imagenet VID挑战[42]的获胜作品提供动力的另一类想法涉及使用光流来扭曲相邻帧的特征图。 深度特征流(DFF)[43]通过在稀疏关键帧上运行检测器并使用光流生成剩余的特征映射来加速检测。 Flowguided Feature Aggregation [42]通过使用自适应加权对来自附近帧的特征进行变形和平均来提高检测精度。
这些想法更接近我们的方法,因为它们还使用时间线索直接修改网络功能并节省计算。 然而,这些方法需要光流信息,这很难快速准确地获得。 即使是DFF考虑的最小流量网络,其计算成本也比我们的大型模型大两倍,比我们的小型模型贵10倍。 此外,需要同时运行流网络和非常昂贵的关键帧检测器使得这种方法需要比我们更多的存储器和存储消耗,这在移动设备上造成问题。 相比之下,我们的网络包含的参数少于我们already-efficient的baseline基础检测器,并且没有额外的内存开销。
2.4. LSTMs for Video Analysis
LSTMs [15]已成功应用于涉及序列数据的许多任务[27]。 一个特定的变体,卷积LSTM [34,30],使用3D隐藏状态并使用卷积层执行门计算,允许LSTM编码空间和时间信息。 我们的工作将卷积LSTM修改为更高效并使用它来跨帧传播时间信息
其他工作也使用LSTM进行基于视频的任务。 LRCNs [5]使用卷积网络从每个帧中提取特征,并将这些特征作为序列馈入LSTM网络。 ROLO [29]通过首先在每个帧上运行YOLO检测器[31],然后将输出边界框和最终卷积特征馈送到LSTM网络来执行对象跟踪。 虽然这些方法在网络输出之上应用LSTM作为后处理,我们的方法通过直接特征映射细化将LSTM完全集成到基本卷积网络中。
2.5. Efficient Neural Networks
最后,先前已经提出了几种用于创建更有效的神经网络模型的技术,例如量化[39,41],因子分解[20,25]和深度压缩[9]。 另一种选择是创建有效的体系结构,如Squeezenet [19],Mobilenet [17],Xception [3]和Shufflenet [40]。 在视频领域,NoScope [21]使用经过修改的蒸馏形式[14]来训练极轻量级的专业模型,但代价是对其他视频的推广。 我们的工作旨在在视频领域创建一个高效的架构,其中上述方法也适用。
3. Approach
在本节中,我们将介绍我们在视频中进行有效在线对象检测的方法。 在我们工作的核心,我们提出了一种方法,将卷积LSTM合并到单图像检测框架中,作为跨时间传播帧级信息的手段。 但是,LSTM的简单集成会导致大量的计算开销并阻止网络实时运行。 为了解决这个问题,我们引入了具有深度可分离卷积[17,3]的Bottleneck-LSTM和Bottleneck设计原则是以降低计算成本。 我们的最终模型在精度,速度和模型尺寸方面优于模拟单帧检测器。
3.1. Integrating Convolutional LSTMs with SSD
将视频视为一系列图像帧。 我们的目标是恢复帧级检测
,其中每个
是对应于图像
的边界框位置和类预测的列表。 请注意,我们考虑在线设置,其中仅使用
的帧来预测检测
。
我们的预测模型可以看作函数F(It,),其中sk = {
}被定义为描述直到帧k的视频的特征映射的矢量。 我们可以使用具有m个LSTM层的神经网络来近似该函数,其中st-1的每个特征映射用作一个LSTM的状态输入,并且从LSTM的状态输出中检索st的每个特征映射。 为了获得整个视频的检测,我们只需按顺序通过网络运行每个图像
为了构建我们的模型,我们首先采用基于Mobilenet架构的SSD框架,并用深度可分离的卷积替换SSD要素层中的所有卷积层。 我们还通过删除最后一层来修剪Mobilenet基础网络。 我们不是将单独的检测和LSTM网络,而是直接将卷积LSTM层注入我们的单帧检测器。 卷积LSTM允许网络对空间和时间信息进行编码,从而创建用于处理时间图像流的统一模型。
3.2. Feature Refinement with LSTMs
当应用于视频序列时,我们可以将LSTM状态解释为表示时间上下文的特征。 然后,LSTM可以使用时间上下文在每个时间步骤细化其输入,同时还从输入提取额外的时间线索并更新其状态。 这种细化模式通常足以通过在其后面放置LSTM层来应用于任何中间特征图。 特征映射用作LSTM的输入,LSTM的输出在将来的所有计算中替换特征映射。
让我们首先将我们的单帧检测器定义为函数。 此函数将用于构建具有m个LSTM层的复合网络。 我们可以将这些LSTM视为将G层分割为m + 1 子网{
}满足:
(1)
我们还定义了每个LSTM层为函数
,其中M和
是相同维度的特征图。 现在,按顺序计算
"公式"
我们已经形成了代表我们联合LSTM-SSD网络的函数F(It,st-1)=(Dt,st). 图2描绘了处理视频时我们的完整模型的输入和输出。 实际上,我们的LSTM层的输入和输出可以具有不同的维度,但是只要每个子网络F的第一卷积层的输入维度被修改,就可以执行相同的计算。
在我们的架构中,我们通过实验选择G的分区。 请注意,较早放置LSTM会导致较大的输入量,并且计算成本很快就会变得过高。 为了使增加的计算可行,我们仅在具有最小空间维度的特征映射之后考虑LSTM放置,其仅限于Conv13层(参见表1)和SSD特征映射。 在4.2节中,我们凭经验表明在Conv13层之后放置LSTM是最有效的。 在这些约束中,我们考虑了几种放置LSTM层的方法:
1.在Conv13层之后放置一个LSTM。
2.在Conv13层之后堆叠多个LSTM。
3.在每个要素图后放置一个LSTM
3.3. Extended Width Multiplier
由于需要在单个前向通道中计算多个门,LSTM本身就很昂贵,这在以效率为中心的网络中存在问题。为了解决这个问题,我们引入了一系列变化,使LSTM与实时移动对象检测的目标兼容。
首先,我们讨论LSTM的维度。通过扩展[17]中定义的信道宽度乘数α,我们可以更好地控制网络架构。原始宽度乘数是用于缩放每个层的通道尺寸的超参数。我们不是将这个乘数均匀地应用于所有层,而是引入三个新参数,
,
,它们控制网络不同部分的信道维数。
具有N个输出通道的基本Mobilenet网络中的任何给定层被修改为具有N输出通道,而
适用于所有SSD特征图并且
适用于LSTM层。对于我们的网络,我们设置
=α,
=0.5α和
=0.25α。每个的输出LSTM是输入大小的四分之一,大大减少了所需的计算量。
3.4. Efficient Bottleneck-LSTM Layers
我们也有兴趣使LSTM本身更有效率。 设M和N分别为LSTM中输入和输出通道的数量。 由于卷积LSTM的定义因不同的工作而异[34,30],我们将标准卷积LSTM定义为:
"公式"
该LSTM将3D特征映射和
作为输入并以通道方式连接它们。 它输出特征图
和单元状态
。 另外,
表示具有权重W,输入X,j输入通道和k输出通道的深度可分离卷积,φ表示激活函数,
表示Hadamard乘积。
与以前的定义相比,我们使用深度可分离卷积可立即将所需计算量减少8到9倍。 我们还选择稍微不寻常的φ(x)= ReLU(x)。 尽管在LSTM中不常使用ReLU激活,但我们发现重要的是不要改变特征映射的界限,因为我们的LSTM散布在卷积层之间。
我们还希望利用我们的LSTM输出通道比输入通道少得多的事实。 我们首先通过计算具有N个通道的瓶颈特征图来对LSTM方程进行微小修改:
然后,bt替换所有其他门中的输入,如图3所示。我们将这个新配方称为Bottleneck-LSTM。 这种修改的好处是双重的。 使用瓶颈特征图减少了门中的计算,在所有实际场景中都优于标准LSTM。 其次,瓶颈-LSTM比标准LSTM更深,遵循经验证据12,13],更深层次的模型优于宽和浅模型。
设每个特征映射的空间维数为DF×DF,让每个深度卷积核的维数为DK×DK。 然后,标准LSTM的计算成本是:
标准GRU的成本几乎相同,除了领先系数为3而不是4.同时,瓶颈-LSTM的成本是:
现在,设置DK = 3并且设k = M / N.然后,当k> 1时,等式(3)大于等式(4)。 也就是说,只要我们的LSTM输出的通道少于输入的三倍,它就比标准LSTM更有效。 由于这种情况不成立是极不寻常的,我们声称瓶颈-LSTM在所有实际情况下都更有效。 当k> 1时,瓶颈-LSTM也比GRU更有效。在我们的网络中,k = 4,并且瓶颈-LSTM比任何替代方案都更有效。 表1详细介绍了我们的完整架构之一。
4. Experiments
4.1. Experiment Setup
我们在Imagenet VID 2015数据集上进行培训和评估。 对于培训,我们使用Imagenet VID培训集中的所有3,862个视频。 我们将LSTM展开为10步并训练10帧的序列。 我们使用RMSprop [38]和异步梯度下降在Tensorflow [1]中训练我们的模型。 与原始的Mobilenet一样,我们的模型可以定制,以满足特定的计算预算。 我们给出宽度乘数α= 1和α= 0.5的模型的结果。 对于α= 1模型,我们使用320×320的输入分辨率和0.003的学习率。 对于α= 0.5模型,我们使用256×256输入分辨率和0.002的学习率。
我们包括hard negative mining和数据扩增,如[28]中所述。 我们通过允许每个正样本比10个负样本的比率来调整原始的hard negative mining,同时将每个负面损失缩放0.3。 我们通过这种修改获得了明显更好的准确性,可能是因为最初的方法严厉地惩罚了groundtruth标签中的假阴性。
为了应对过度拟合,我们使用两阶段过程训练网络。 首先,我们在没有LSTM的情况下对SSD网络进行微调。 然后,我们冻结基础网络中的权重,直到并包括层Conv13,并为剩余的训练注入LSTM层。
为了评估,我们从Imagenet VID评估集中的每个视频中随机选择20个连续帧的片段,总共11080帧。 我们将这些帧指定为迷你集。 对于所有结果,我们报告标准的Imagenet VID精度度量,平均精度@ 0.5 IOU。 我们还报告了参数数量和乘加(MAC)作为效率的基准。
4.2. Ablation Study
在本节中,我们将展示每个主要设计决策的个体有效性。
Single LSTM Placement. 首先,我们在模型中的各个层之后放置一个LSTM。 表2证实了在特征映射之后放置LSTM可以提供卓越的性能,Conv13层提供了最大的改进,验证了我们声称在特征空间中添加时间感知是有益的。
Recurrent Layer Type. 接下来,我们将我们提出的Bottleneck-LSTM与其他复现层类型(包括平均值,LSTM和GRU [2])进行比较。 对于这个实验,我们在Conv13层之后放置一个循环层,并评估我们的模型的α= 1和α= 0.5。 作为baseline,我们使用连续帧中的特征的加权平均,当前帧的权重为0.75,前一帧的权重为0.25。 Bottleneck-LSTM的输出通道尺寸根据扩展宽度乘数减小,但所有其他循环层类型具有相同的输入和输出尺寸,因为它们不是为Bottleneck而设计的。 结果显示在表3中。我们的Bottleneck-LSTM比其他循环层的效率高一个数量级,同时获得相当的性能。
Bottleneck Dimension. 我们进一步分析了LSTM输出通道尺寸对精度的影响,如图4所示。在每个实验中,在Conv13层之后放置一个Bottleneck-LSTM。 精度保持接近=0.25α,然后下降。 这支持我们使用扩展宽度乘数
Multiple LSTM Placement Strategies. 我们的框架自然地推广到多个LSTM。在SSD中,每个特征图都表示特定比例的要素。我们研究了合并多个LSTM以改进不同尺度的特征图的好处。在表4中,我们评估了合并多个LSTM的不同策略。在此实验中,我们逐步向网络添加更多LSTM图层。由于难以同时训练多个LSTM,我们从先前的检查点进行微调,同时逐步添加层。在不同尺度的特征图之后放置LSTM导致略微的性能改进,并且由于稍后的特征图的小尺寸和LSTM层的效率,计算成本几乎没有变化。但是,在相同的特征图之后堆叠两个LSTM是没有益处的。对于最后两个特征图(FM3,FM4),我们不会进一步阻碍LSTM输出通道,因为通道尺寸已经非常小。我们使用在所有要素图之后放置LSTM的模型作为我们的最终模型。
4.3. Comparison With Other Architectures
在表5中,我们将最终模型与最先进的单图像检测框架进行比较。 所有baseline都使用开源Tensorflow Object Detection API进行训练[18]。 在这些方法中,只有MobilenetSSD变体和我们的方法可以在移动设备上实时运行,我们的方法在所有方面都优于Mobilenet-SSD指标。 定性差异如图5所示。我们还包括以性能为重点的架构,这些架构的计算成本更高。 我们的方法只需很少的成本即可达到Inception-SSD网络的准确性。 此外,我们还包括Resnet Faster-RCNN的参数和MAC,以突出我们的方法和非移动视频对象检测方法之间的巨大计算差异,这些方法通常包括类似的昂贵的基础网络。
4.4. Robustness Evaluation
我们通过在每个视频中创建人工遮挡来测试我们的方法对输入噪声的稳健性。 我们按如下方式生成这些遮挡:对于每个groundtruth边界框,我们分配遮挡边界框的概率p。 对于尺寸为H×W的每个被遮挡的边界框,我们将在该边界框内的和
之间的随机选择的矩形区域中的所有像素归零。 表6中报告了该实验的结果。所有方法都在相同的遮挡上进行评估,并且在测试之前没有训练这些遮挡的方法。 我们的方法在这种噪声数据上优于所有单帧SSD方法,证明我们的网络已经学习了视频的时间连续性,并使用时间线索来实现对噪声的鲁棒性。
4.5. Mobile Runtime
我们使用Qualcomm Snapdragon 835在最新的Pixel 2手机上根据baseline评估我们的模型。运行时间在Snapdragon 835 big和LITTLE核心上进行测量,使用Tensorflow [1]的自定义设备实现进行单线程推断。 表7显示我们的模型优于所有baseline。 值得注意的是,我们的α= 0.5模型在大核心上实现15 FPS的实时速度
5. Conclusion
我们在视频中引入了一种新颖的移动目标检测框架,该框架基于将移动SSD框架和循环网络统一到一个临时性的架构中。 我们提出了一系列修改,使我们的模型比移动专注的单帧模型更快,更轻,尽管具有更复杂的架构。 我们继续单独检查每个设计决策,并凭经验表明我们的修改使我们的网络更有效率,同时性能降低最小。 我们还证明我们的网络足够快,可以在移动设备上实时运行。 最后,我们证明我们的方法优于可比的最先进的单帧模型,以表明我们的网络受益于视频中的时间线索。
Acknowledgements:我们非常感谢同事们在这项工作中给予的帮助和讨论:Yuning Chai,Matthew Tang,Benoit Jacob,LiangChieh Chen,Susanna Ricco和Bryan Seybold。
References
[1] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mane,´ R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan, F. Viegas, O. Vinyals, P. War- ´ den, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org. 5, 7
[2] K. Cho, B. Van Merrienboer, C. Gulcehre, D. Bahdanau, ¨ F. Bougares, H. Schwenk, and Y. Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014. 6
[3] F. Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv preprint arXiv:1610.02357, 2016. 3
[4] J. Dai, Y. Li, K. He, and J. Sun. R-fcn: Object detection via region-based fully convolutional networks. In NIPS, 2016. 1, 2
[5] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell. Long-term recurrent convolutional networks for visual recognition and description. In CVPR, 2015. 3
[6] C. Feichtenhofer, A. Pinz, and A. Zisserman. Detect to track and track to detect. In ICCV, 2017. 2
[7] R. Girshick. Fast r-cnn. In ICCV, 2015. 2
[8] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014. 1, 2
[9] S. Han, H. Mao, and W. J. Dally. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. In ICLR, 2016. 3
[10] W. Han, P. Khorrami, T. L. Paine, P. Ramachandran, M. Babaeizadeh, H. Shi, J. Li, S. Yan, and T. S. Huang. Seq-nms for video object detection. arXiv preprint arXiv:1602.08465, 2016. 2
[11] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014. 1
[12] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. 1, 5
[13] K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In ECCV, 2016. 5
[14] G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015. 3 [15] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997. 3
[16] S. Hong, B. Roh, K.-H. Kim, Y. Cheon, and M. Park. Pvanet: Lightweight deep neural networks for real-time object detection. arXiv preprint arXiv:1611.08588, 2016. 2
[17] A. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017. 1, 3, 4
[18] J. Huang, V. Rathod, D. Chow, C. Sun, and M. Zhu. Tensorflow object detection api, 2017. 7
[19] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. Dally, and K. Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and ¡0.5mb model size. arXiv preprint arXiv:1602.07360, 2016. 3
[20] M. Jaderberg, A. Vedaldi, and A. Zisserman. Speeding up convolutional neural networks with low rank expansions. arXiv preprint arXiv:1405.3866, 2014. 3
[21] D. Kang, J. Emmons, F. Abuzaid, P. Bailis, and M. Zaharia. Noscope: Optimizing neural network queries over video at scale. arXiv preprint arXiv:1703.02529, 2017. 3
[22] K. Kang, H. Li, J. Yan, X. Zeng, B. Yang, T. Xiao, C. Zhang, Z. Wang, R. Wang, X. Wang, and W. Ouyang. T-cnn: Tubelets with convolutional neural networks for object detection from videos. arXiv preprint arXiv:1604.02532, 2016. 2
[23] K. Kang, W. Ouyang, H. Li, and X. Wang. Object detection from video tubelets with convolutional neural networks. In CVPR, 2016. 2
[24] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012. 1
[25] V. Lebedev, Y. Ganin, M. Rakhuba, I. Oseledets, and V. Lempitsky. Speeding-up convolutional neural networks using fine-tuned cp-decomposition. arXiv preprint arXiv:1412.6553, 2014. 3
[26] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar. Focal loss for dense object detection. In ICCV, 2017. 2
[27] Z. Lipton, J. Berkowitz, and C. Elkan. A critical review of recurrent neural networks for sequence learning. arXiv preprint arXiv:1506.00019, 2015. 3
[28] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg. Ssd: Single shot multibox detector. In ECCV, 2016. 1, 2, 5
[29] G. Ning, Z. Zhang, C. Huang, and Z. He. Spatially supervised recurrent convolutional neural networks for visual object tracking. arXiv preprint arXiv:1607.05781, 2016. 3
[30] V. Patraucean, A. Handa, and R. Cipolla. Spatio-temporal video autoencoder with differentiable memory. arXiv preprint arXiv:1511.06309, 2015. 3, 4
[31] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In CVPR, 2016. 2, 3
[32] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NIPS, 2015. 1, 2
[33] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. IJCV, 115(3):211–252, 2015. 2
[34] X. Shi, Z. Chen, H. Wang, D. Yeung, W. Wong, and W. Woo. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In NIPS, 2015. 3, 4
[35] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. 1
[36] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In CVPR, 2015. 1
[37] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013. 1
[38] T. Tieleman and G. Hinton. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 4(2), 2012. 5
[39] J. Wu, C. Leng, Y. Wang, Q. Hu, and J. Cheng. Quantized convolutional neural networks for mobile devices. In CVPR, 2016. 3
[40] X. Zhang, X. Zhou, M. Lin, and J. Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. arXiv preprint arXiv:1707.01083, 2017. 1, 3
[41] A. Zhou, A. Yao, Y. Guo, L. Xu, and Y. Chen. Incremental network quantization: Towards lossless cnns with lowprecision weights. In ICLR, 2017. 3
[42] X. Zhu, Y. Wang, J. Dai, L. Yuan, and Y. Wei. Flow-guided feature aggregation for video object detection. In ICCV, 2017. 2 [43] X. Zhu, Y. Xiong, J. Dai, L. Yuan, and Y. Wei. Deep feature flow for video recognition. In CVPR, 2017. 1, 2
这篇关于Mobile Video Object Detection with Temporally-Aware Feature Maps(具有时间感知特征映射的移动视频目标检测)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




