本文主要是介绍【论文翻译】Mobile Video Object Detection with Temporally-Aware Feature Maps,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
来源: 谷歌,CVPR 2018
文章链接:https://arxiv.org/abs/1711.06368v2
最新研究 CVPR2019(在此基础上进一步提升速度):https://arxiv.org/abs/1903.10172我的翻译:https://blog.csdn.net/u014386899/article/details/102475750
代码:https://github.com/tensorflow/models/tree/master/research/lstm_object_detection
《Mobile Video Object Detection with Temporally-Aware Feature Maps》
基于时间感知特征图的移动视频目标检测
摘要:
本文介绍了一种在低功耗移动设备和嵌入式设备上实时运行的视频对象在线检测模型。我们的方法结合了快速的单图像目标检测方法。与卷积的长期短期记忆(LSTM)层,以创建一个交织的递归-卷积结构。此外,我们还提出了一种高效的Bottleneck-LSTM层,它与常规lstm相比大大降低了计算成本。我们的网络通过使用Bottleneck-LSTM来细化和传播帧间的特征映射,从而实现了时态感知。这种方法实质上是比现有的视频检测方法更快,在模型大小和计算成本方面优于最快的单帧模型,同时该模型在Imagenet Vid 2015数据集上达到了与昂贵得多的单帧模型相媲美的精度。该模型在移动CPU上的实时推理速度可达15 FPS.
1 介绍
……
2 相关工作
2.1.图像中的目标检测
最近的单图像检测方法可分为两类,一类是R-CNN[8]及其后代[7,32,16]推广的基于区域的两阶段方法。这些方法首先提出对象区域,然后对每个区域进行分类,从而进行推理。或者,single-shot方法[28,31,4,26]通过在固定的锚位置产生预测,在一次传递中执行推理。我们的工作建立在SSD框架[28]之上,因为它的效率和竞争的准确性。
2.2 视频目标检测与跟踪
在Imagenetvid数据集上已有的许多方法将单个帧检测组织为轨道或管状集,并使用后处理更新检测。SEQ-NMS[10]链接高置信度预测整个视频的NTO序列。TCNN[22,23]使用光流将检测映射到相邻帧,并抑制低置信度预测,同时还包含跟踪算法。然而,这些方法既不执行在线推理,也不注重效率。
我们的方法不是基于最终的检测结果来操作,而是直接将时间上下文并入到特征级别上,并且不需要后处理步骤或在线学习。由于我们的方法可以通过将这些方法中的任何一种方法应用于我们的检测结果来扩展,所以我们的网络比这些方法所使用的基本单帧检测器更具有可比性。
在此,我们的方法是为移动环境量身定做的。即使有了积极的时间跨度,他们的模型也不能在移动设备上运行,因为他们的RESNET-101基本网络(Req)的成本很高。计算量比我们的大模型多79倍,比小模型多450倍。
2.3 视频对象检测与光流
另一类不同的想法推动了2017年Imagenet VID挑战的胜利,[42]涉及到使用光流在相邻帧之间扭曲特征映射。深特征流(DFF)[43]通过在稀疏关键帧上运行检测器并使用光流生成剩余的特征映射来加速检测。流引导特征聚合[42]通过自适应加权从邻近帧中扭曲和平均特征来提高检测精度。
这些想法更接近我们的方法,因为他们还使用时间线索来直接修改网络特性并节省计算。然而,这些方法都需要光流信息,难以快速、准确地获得光流信息。即使是DFF所考虑的最小流网络,计算成本也是我们的大模型的两倍,比我们的小模型高出10×。此外,由于需要同时运行流网络和非常昂贵的关键帧检测器,因此这种方法比我们所需要的内存和存储消耗要大得多,这给移动设备带来了问题。相反,我们的网络包含比我们已经高效的基线检测器更少的参数,并且没有额外的内存开销。
2.4. LSTMs for Video Analysis
LSTM[15]已成功应用于涉及顺序数据的许多任务[27]。一个特定变体,卷积LSTM[34,30]使用3D隐藏状态并执行门计算。使用卷积层,允许LSTM对空间和时间信息进行编码。我们的工作改进了卷积LSTM以提高效率,并利用它来传播时间信息。
其他作品也使用LS TM进行基于视频的任务..使用卷积网络从每个帧中提取特征并将这些特征作为序列输入LSTM网络。ROLO[29]通过首先在每个帧上运行Yolo检测器[31]来执行对象跟踪,然后将输出边界框和最终卷积特征馈送到LSTM网络中。然而,这些方法在网络输出的顶部应用LSTMS作为后处理,但我们的方法通过直接特征映射细化将LSTMS完全集成到基本卷积网络中。
2.5. Effificient Neural Networks
最后,已经提出了几种用于创建更有效的神经网络模型的技术,例如量化[39,41]、分解[20,25]和深度压缩[9]。另一个选择创建高效的体系结构,如Squeezenet[19]、Mobilenet[17]、Xception[3]和Shufflenet[40]。在视频领域,nocope[21]使用改进的精馏形式[14]训练极其轻量级的专门模型,而代价是对其他视频的推广。我们的工作目标是在视频领域创建一个高效的架构,而上述方法也适用于该架构。
3.方法
在这一部分,我们描述了我们的方法,有效的在线目标检测视频。在我们工作的核心,我们提出了一种将卷积lstms集成到单幅图像检测中的方法。框架作为跨时间传播帧级信息的手段。然而,LSTMS的简单集成导致显著的计算开销,并阻止网络实时运行。为了解决这个问题,我们介绍了一个 Bottleneck-LSTM 与深度可分卷积[17,3]和瓶颈设计原则,以减少计算费用。我们的最终模型在精度、速度和型号大小上都优于类似的单帧检测器.

3.1.Convolutional LSTM与SSD的集成
将视频看作图像帧的序列V={I0,I1,。....In}我们的目标是恢复帧级检测{d0,d1,。....dn},其中每个DK都是与图像Ik相对应的包围框位置和类预测的列表。请注意,我们考虑的是一个在线设置,其中仅使用Ik的帧来预测检测DK。
我们的预测模型可以看作是一个函数F(it,st 1)=(dt,st),其中SK={s0k,s1k,。....S(m-1)k}定义为描述视频到帧k的特征映射向量。我们可以使用带有m个lstm层的神经网络来逼近这个函数,其中st-1的每个特征映射作为对一个lstm的状态输入,并且st的每个特征映射都从LSTM的状态输出获取。为了获得整个视频的检测结果,我们只需按顺序通过网络运行每一幅图像。
为了构建我们的模型,我们首先采用基于Mobileenet体系结构的SSD框架,并用深度可分离的卷积来替换SSD特征层中的所有卷积层。我们还通过删除最终层对Mobileenet基础网络进行删减。然后,我们不具有单独的检测和LSTM网络,而是直接将卷积LSTM层注入到我们的单帧中探测器。卷积LSTM允许网络对空间和时间信息进行编码,为处理时态图像流创建一个统一的模型。
3.2.基于LSTMs的特征细化
当应用于视频序列时,我们可以将LSTM状态解释为表示时间上下文的特征。然后,LSTM可以使用时间上下文来细化其在每个时间步骤的输入,同时还从输入中提取额外的时态提示并更新其状态。通过在紧接其后放置LSTM层,该细化模式通常足以在任何中间特征映射上应用,而LSTM的输出在以后的所有计算中都取代了特征映射。
让我们首先将我们的单帧检测器定义为函数G(It)=dt。此函数将用于构造具有m 个LSTM层的复合网络。 我们可以将这些LSTM看作是将G的层划分为M1子网络{G0,G1,.....GM)满足:
![]()
我们还定义了每个LSTM层![]() 作为函数
作为函数![]() ,其中M和M+是同维特征映射。现在,通过顺序计算
,其中M和M+是同维特征映射。现在,通过顺序计算

我们形成了函数![]() ,表示我们的LSTM-SSD网络. 图2描述了我们的整个模型在处理视频时的输入和输出。实际上,我们的lstm层的输入和输出可能有不同的维度。但是,只要每个子网络F的第一卷积层修改了其输入维数,就可以执行相同的计算。
,表示我们的LSTM-SSD网络. 图2描述了我们的整个模型在处理视频时的输入和输出。实际上,我们的lstm层的输入和输出可能有不同的维度。但是,只要每个子网络F的第一卷积层修改了其输入维数,就可以执行相同的计算。
在我们的架构中,我们从实验上选择了G的分区。请注意,将LSTM放在较早的位置会导致更大的输入量,而且计算成本很快就会变得难以接受。使增加的计算是可行的,我们只考虑LSTM在空间维数最低的特征映射之后的位置,这仅限于Conv 13层(见表1)和SSD特征映射。在第4.2节中,我们经验性地证明了在Conv 13层之后放置LSTM是最有效的。在这些约束中,我们考虑了放置lstm层的几种方法:
1.在Conv 13层后放置一个LSTM。
2.在Conv 13层后叠加多个LSTM。
3.在每幅特征图后放置一个LSTM。

3.3.扩展宽度乘法器
LSTM本身就很昂贵,因为它需要在一次forward pass 中计算几个门,这就给效率集中的网络带来了一个问题。为了解决这个问题,我们引入了一种使LSTMS与实时移动目标检测的目标兼容的一系列的变化。
首先,我们讨论了LSTM的维数。我们可以通过扩展[17]中定义的信道宽度乘子α来获得对网络体系结构的更好的控制。原始宽度乘数是用于缩放每个层的通道尺寸的超参数。我们没有将该乘法器统一地应用于所有层,而是引入了三个新的参数αbase,即αssd和αlstm,它们控制着网络不同部分的信道尺寸。
对具有N个输出通道的基本Mobilenet网络中的任何给定层进行修改,使其具有N个α基输出通道,而αssd适用于所有α特征映射,而αLSTM适用于LSTM层。对于我们的网络,我们设置αbase=α,αssd=0.5α和αlstm=0.25α。每个lstm的输出是输入的四分之一,这大大减少了所需的计算量。
3.4.高效Bottleneck-LSTM层
我们也有兴趣使LSTM本身更有效率。设M和N分别是LSTM的输入和输出通道数。由于卷积LSTM的定义在不同的工作[34,30]中有所不同,我们将定义一个标准的卷积LSTM:

这个LSTM以3D特征映射![]() 和
和![]() 作为输入,并将它们按通道连接起来。它输出特征映射ht和单元状态ct。另外,
作为输入,并将它们按通道连接起来。它输出特征映射ht和单元状态ct。另外,![]() 表示 加权W,输入X,j输入通道和k输出通道的深度可分卷积,φ表示激活函数,◦表示Hadamard积.
表示 加权W,输入X,j输入通道和k输出通道的深度可分卷积,φ表示激活函数,◦表示Hadamard积.
与以前的定义相比,我们使用深度可分卷积立即将所需的计算量减少了8至9倍。我们还选择了一个稍微不寻常的φ(X)=relu(X)。尽管relu激活在LSTM中并不常见,我们发现不改变特征映射的边界是很重要的,因为我们的LSTM是分布在卷积层之间的。

表1:在我们的LSTM-SSD架构中使用一个256通道状态的单一LSTM的卷积层。“dw”表示深度卷积。最后的包围框是通过应用附加卷积到瓶颈-LSTM和特征映射层。请注意,我们将所有四个LSTM门计算合并成一个卷积,因此LSTM计算1024个门通道,但只输出256个通道。
我们还希望利用这样一个事实,即我们的LSTM的输出通道比输入通道少得多。我们首先通过计算N个通道的瓶颈特征映射,对LSTM方程做了一个小的修改:
![]()
然后,bt替换所有其他门中的输入,如图3所示。我们把这个新的表述称为瓶颈-LSTM。这种修改的好处有两方面。使用瓶颈特征映射减少了门中的计算量,在所有实际场景中都优于标准的LSTM。其次,瓶颈-LSTM比标准的LSTM更深,这与经验证据[12,13]一样,深层次模型优于广义和浅层模型。
设每个特征映射的空间维数为df×df,每个深卷积核的维数为dk×dk。然后,标准LSTM的计算成本是:
![]()
标准GRU的成本几乎相同,除了3而不是4的主导系数。同时,瓶颈-LSTM的代价是:
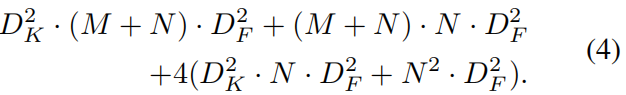
现在,设置![]() ,让
,让![]() 。 然后,当方程(3)大于方程(4)时
。 然后,当方程(3)大于方程(4)时![]() .也就是说,只要我们的LSTM输出的信道少于输入的三倍,它就比标准的LSTM更高效。因为这种情况是非常不寻常的等等,我们认为瓶颈-LSTM在所有实际情况下都是更有效的.当k>1时,瓶颈-LSTM也比GRU更有效。在我们的网络中,k=4,而瓶颈-LSTM比任何替代方案都要有效得多。我们完整的体系结构之一详见表1。
.也就是说,只要我们的LSTM输出的信道少于输入的三倍,它就比标准的LSTM更高效。因为这种情况是非常不寻常的等等,我们认为瓶颈-LSTM在所有实际情况下都是更有效的.当k>1时,瓶颈-LSTM也比GRU更有效。在我们的网络中,k=4,而瓶颈-LSTM比任何替代方案都要有效得多。我们完整的体系结构之一详见表1。
4.实验
4.1 实验设置
我们对Imagenet VID 2015数据集进行培训和评估。对于培训,我们使用ImagenetVid培训集中的所有3,862个视频。我们将LSTM展开到10个步骤,并在10帧的序列上进行训练。我们使用RMSprop[38]和异步梯度下降来训练我们的模型。就像最初的Mobilenet一样,我们的模型可以定制以满足特定的计算预算。给出了具有宽度乘数α=1和α=0.5的模型的结果。对于α=1模型,输入分辨率为320×320,学习速率为0.003。对于α=0.5模型,输入分辨率为2 5 6×2 5 6,学习速率为0.002.
如[28]所述,我们包括硬负挖掘和数据增强。我们调整了原来的硬负挖掘方法,允许在sc时,每个正数对应10个负数。每负损失0.3。通过这一修改,我们获得了更好的准确性,这可能是因为最初的方法严厉地惩罚了地真相标签中的假阴性。
为了处理过度拟合,我们使用两个阶段的过程来训练网络.首先,我们完成了没有LSTMS的SSD网络。我们冻结上到并包含层Conv 13的base网络的权重,并为剩余的训练注入LSTM层。
为了进行评估,我们从ImagenetVid评估集中的每个视频中随机选择了20个连续帧的段,共计11080帧。我们指定这些帧为迷你集。对于所有结果,我们报告了标准的Imagenet VID精度度量,平均精度@0.5 IOU。我们还报告了参数和乘加(MAC)作为效率的基准。

表2:我们的模型(α=1)的性能,在不同的层之后放置一个LS TM。图层名称符合表1。在输出实验中,我们将lstms置于所有五个最终预测层之后。
4.2.消融实验
在本节中,我们将演示每个主要设计决策的个别有效性。
单LSTM布局:
首先,我们在模型的各个层之后放置一个LSTM。表2确认,在特征映射之后放置LSTM会带来更好的性能,Conv 13层提供了最大的性能。改进,验证我们的说法,即在特性空间中添加时态感知是有益的。
递归层类型:
接下来,我们将我们提出的瓶颈-LSTM与其他递归层类型进行了比较,包括平均层、LSTM和Grus[2]。在这个实验中,我们在Conv 13层之后放置了一个单一的递归层。并对α=1和α=0.5的模型进行评估。作为基线,我们使用连续帧中的特征加权平均,当前帧的权重为0.75,前帧的权重为0.25。瓶颈-lstm的输出通道维是根据扩展的宽度乘子来减小的,但是所有其他的递归层类型都有相同的输入和输出维,因为它们不是。设计用来做瓶颈的。结果见表3。我们的瓶颈LSTM是一个数量级的数量级,比其他重复层更有效,同时达到类似的性能。


瓶颈维数:
我们进一步分析了LSTM输出通道尺寸对精度的影响,如图4所示。精度保持在接近c先到αlstm=0.25α,然后下降。这支持我们使用扩展宽度乘法器。
多重LSTM布局策略
我们的框架自然地推广到多个LSTM。在SSD中,每个特征图以一定的比例表示特征。我们研究了合并多个lstm以在不同尺度上细化特征图的好处。在表4中,我们评估了合并多个LS TM的不同策略。在本实验中,我们逐步向网络中添加了更多的LS TM层。由于在同时训练多个LSTM方面的困难,我们在逐步增加层的同时,从以前的检查点中获得了改进。由于后期特征映射的小尺寸和我们的LSTM层的效率,在不同比例的特征映射之后放置LSTM,性能略有提高,计算成本几乎没有变化。然而,堆叠两个LSTM在相同的特征图之后是没有好处的。对于最后两个特征映射(FM3,FM4),由于通道尺寸已经非常小,我们不再进一步限制LSTM输出通道。我们以LSTM作为我们的最终模型,用LSTM放置在所有的特征图的后面作为我们的最终模型。

表4:我们具有多个Bottleneck-LSTMs的体系结构的性能。图层名称匹配表1,其中FM代表特征图。√表示放置在指定层之后的单个LSTM,而√√表示放置的两个LSTM。

4.3.与其他结构的比较
在表5中,我们将我们的最终模型与最先进的单一图像检测框架进行了比较.所有基线都使用开源的TensorFlow对象检测API[18]进行训练。在这些方法中,只有MobienetSSD变体和我们的方法可以在移动设备上实时运行,而且我们的方法在所有指标上都优于Mobilenet-SSD。显示了质量上的差异。如图5所示。我们还包括以性能为中心的体系结构,这些体系结构在计算上更昂贵。我们的方法以一小部分成本接近InceptionSSD网络的准确性。此外,我们还包括RESNET的参数和mac-rcn,以突出我们的方法和非移动视频对象检测方法之间的巨大计算差异。包括同样昂贵的基本网络。
4.4.鲁棒性评价
我们通过在每个视频中创建人工遮挡来测试我们的方法对输入噪声的鲁棒性。我们按照如下方式生成这些封闭性:对于每个地面真相包围框,我们分配了一个封闭包围盒的概率p。对于每个尺寸为H×W的闭塞包围盒,我们在任意选择的矩形区域中的所有像素零点,大小介于![]() 和
和![]() 之间。 实验结果见表6。所有方法都在相同的封堵器上进行评估,在测试前没有任何方法对这些封堵器进行训练。我们的方法比所有的单点都要好。电子帧SSD方法对这些有噪声的数据,表明我们的网络已经学会了视频的时间连续性质,并利用时间线索,以实现对噪声的鲁棒性。
之间。 实验结果见表6。所有方法都在相同的封堵器上进行评估,在测试前没有任何方法对这些封堵器进行训练。我们的方法比所有的单点都要好。电子帧SSD方法对这些有噪声的数据,表明我们的网络已经学会了视频的时间连续性质,并利用时间线索,以实现对噪声的鲁棒性。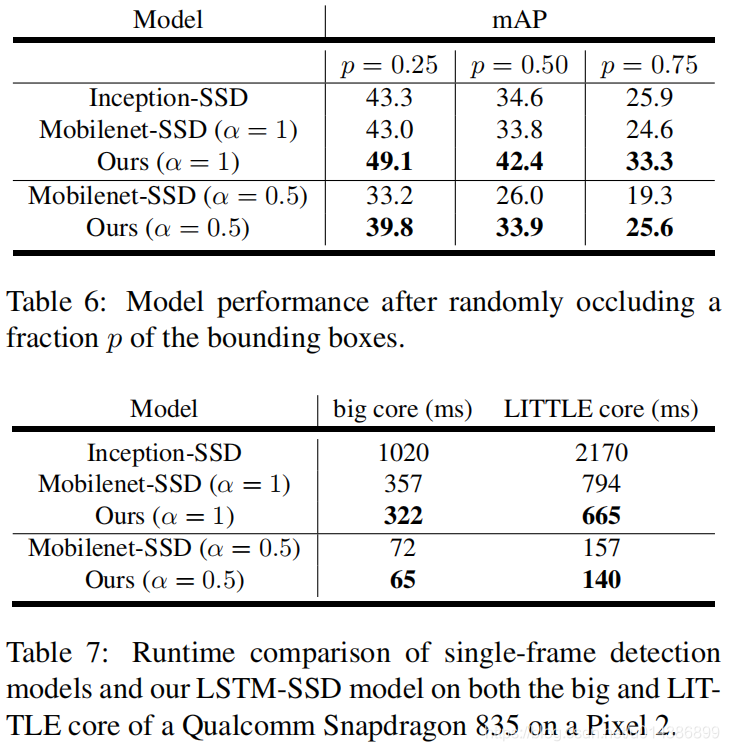
4.5. Mobile Runtime
我们评估我们的模型在最新的Pixel 2手机与高通Snap巨龙835基线。运行时是在Snap巨龙835大内核和小内核上测量的,使用的是单线程推断。

 图5:ImagenetvidMinival集中的示例剪辑,其中我们的模型(α=1)优于类似的单帧Mobilenet-SSD模型(α=1)。我们的网络使用时态上下文来提供重要的更稳定的帧检测。每个序列的上一行对应于我们的模型,下一行对应于Mobilenet-SSD。
图5:ImagenetvidMinival集中的示例剪辑,其中我们的模型(α=1)优于类似的单帧Mobilenet-SSD模型(α=1)。我们的网络使用时态上下文来提供重要的更稳定的帧检测。每个序列的上一行对应于我们的模型,下一行对应于Mobilenet-SSD。
5.结论
提出了一种基于统一移动SSD框架和递归网络的视频移动目标检测框架。我们建议进行一系列修改,使我们的模型比以移动为重点的单帧模型更快、更轻巧,尽管其架构更为复杂。我们继续单独检查我们的每一个设计决策,并且经验性地表明,我们的修改允许我们的网络在性能最小的情况下变得更有效率。我们还证明,我们的网络足够快,可以在移动设备上实时运行.最后,我们证明了我们的方法优于INDIC的最先进的单帧模型。我们的网络从视频中的时态线索中获益。
这篇关于【论文翻译】Mobile Video Object Detection with Temporally-Aware Feature Maps的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







