本文主要是介绍Conditional Generation of Temporally-ordered Event Sequences翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
叙事结构知识模型已被证明可用于一系列与事件相关的任务,但它们通常无法捕捉事件之间的时间关系。我们提出了一个单一模型,既可以解决时间排序问题,即将给定的事件按照它们发生的顺序进行排序,也可以解决事件填充问题,即预测适合现有时间顺序序列的新事件。我们使用基于 BART 的条件生成模型,该模型可以同时捕获时间性和常见事件,这意味着它可以灵活地应用于该空间中的不同任务。我们的模型被训练为去噪自编码器:我们采用时间顺序的事件序列,将它们打乱,删除一些事件,然后尝试恢复原始事件序列。此任务教会模型在对基础场景中事件不完整的情况下进行推理。在时间排序任务中,我们表明我们的模型能够从现有数据集中解读事件序列,而无需访问明确标注过的时间训练数据,这要优于基于 BERT 的成对模型和基于 BERT 的指针网络。在事件填充方面,人工评估表明,与 GPT-2 故事完成模型相比,我们的模型能够生成在时间上更适合输入事件的新事件。
1.介绍

本文提出了一个单一的事件模型来支持两个看似不同的任务中的推理:(1) 时间事件排序和 (2) 事件填充,或推断一个已经发生的大事件中未看到或未提及的部分。图 1 显示了说明这两个目标的示例。与之前的方法不同,我们的目标是使用相同的模型架构来解决这两个问题,而不必为每个任务分别标注数据和构建临时模型;我们的目标是开发能够广泛捕获时间事件知识并支持广泛推理的模型。因此,我们需要一个合适的通用建模框架来捕获有关事件的时间知识,在我们的案例中,这是基于 BART的模型,我们称之为 TemporalBART。请注意,经典的时间关系提取模型,主要是在特定文档的上下文中对时间序列进行建模,这主要是学习如何使用局部话语线索而不是可概括的事件知识。
这项工作的目标与过去学习叙事模式的工作有关。我们的方法特别遵循最近使用分布式模式表示的工作,它支持对事件的推断,而无需明确具体化离散模式库。这项工作中的目标任务直接由模式学习的下游应用驱动。诸如故事完成之类的文本生成任务依赖于理解是什么使叙述可信,以及在其他事件之前、之后和之间可能发生哪些事件,从而激发我们的事件填充任务。回答有关场景中原因、结果或接下来可能发生什么的问题需要了解事件序列的典型时间顺序,从而激发我们的时间排序任务。先前的工作并没有像我们那样将传统的事件填充与时间事件排序结合起来。
我们提出了一个条件生成模型来处理时间事件排序和事件填充,并将其训练为脱离上下文的针对时间事件序列的去噪自编码器。如图 1 所示,我们的 TemporalBART 模型的编码器读取输入事件子集的一个时间混乱序列,该序列是通过破坏语料中按时间排序的事件序列获得的。解码器可以被视为条件事件语言模型,然后重建完整的、按时间排序的事件序列。这种去噪训练已在许多应用中得到成功利用,之前已经探索过使用 seq2seq 模型重新排序和平滑输入,但据我们所知,我们是第一个将其应用于这种时间建模设置的人。我们模型的条件生成架构足够灵活,可以通过从模型中采样或使用它来对序列进行评分来处理各种任务,包括我们的时间排序和事件填充任务。由于最近预训练的编码器 - 解码器Transformer的成功,我们的模型本身也基于 BART。
收集具有时间注释的大规模高质量标注数据通常很昂贵,并且需要专门设计的标注方案。在这里,我们转而使用叙述性文档语料库 EventsNarratives,并设计一种自动方法来提取我们需要的训练数据。在这些文档中,话语顺序被松散地假设为反映时间顺序,因此从本文中提取的事件可以直接为我们的模型提供训练数据。这种自动注释的使用使我们能够使用广泛领域数据,从而为我们提供了强大的域独立时间模型。
2.背景及相关工作
学习时间知识以对事件进行排序并生成新事件作为模式或故事的一部分是两个受到广泛关注的问题,但与我们的工作相比,以前的工作通常孤立地关注每个问题。
2.1 Temporal Event Ordering
与本文的时间排序方面密切相关的工作是时间关系提取,它对文档上下文中文本的事件对进行排序。此问题已作为成对分类或作为结构化学习问题来解决,以对输出施加约束。然而,即使在后面的这些工作中,模型也专注于成对关系。相比之下,我们在这里的工作将时间事件排序视为一个序列生成问题,它为模型提供了更强的归纳偏差来捕捉事件之间的全局时间关系。最近的一项工作 (Madaan and Yang, 2020) 将此任务视为图生成问题,因此能够预测更复杂的结构,但它仅关注排序,不适合我们的事件填充目标。
2.2 Schema Induction
模式学习系统通常根据其预测未知事件的能力进行评估。最初的工作试图使用统计方法来导出原理图信息库。另一个线则利用事件语言建模来学习事件的分布,或者专注于学习事件表示而不是writing down离散模式。然而,大部分工作仅对事件之间的共现进行建模,而不是直接考虑时间信息,并且仅将事件表示为 S-V-O 词条的元组。
另一项工作则直接侧重于从“story salads” 中提取连贯的叙事,或更广泛地生成给定预定义场景的叙事。然而,在不考虑时间排序的情况下,这些系统倾向于学习事件的话语排序,而不是时间知识的强表示。
3.方法
3.1 Task Formulation and Model
我们的框架涉及在时间事件序列 y = { e 1 , ⋅ ⋅ ⋅ , e l } \textbf y=\{e_1,···,e_l\} y={e1,⋅⋅⋅,el}上对条件分布 P ( y ∣ x ) P(\textbf y|\textbf x) P(y∣x)进行建模,这些事件序列是脱离上下文的事件序列(即,并未表示为文档中的一个跨度), 是同一场景的一部分,涉及共享的参与者,并且按时间顺序排列。该模型的输入是一个(不一定是时间的)事件序列 x = { e 1 , ⋅ ⋅ ⋅ , e m } \textbf x=\{e_1,···,e_m\} x={e1,⋅⋅⋅,em},表示与场景 y \textbf y y相关的不完整信息,即无序事件的部分集合。鉴于这种不完整的信息,我们的模型应该学习事件的真实潜在顺序的分布,这个顺序在事件序列中没有明显的标识。通过将事件脱离上下文而不是文档上下文,我们鼓励模型对事件之间的时间知识进行编码,而不是编码像表面文本顺序或可能决定其顺序的话语连接词等表面线索。
对于事件的定义,我们遵循 Chambers and Jurafsky (2008) ,其中事件 e e e由一个谓词 v e v_e ve及其论述组成。
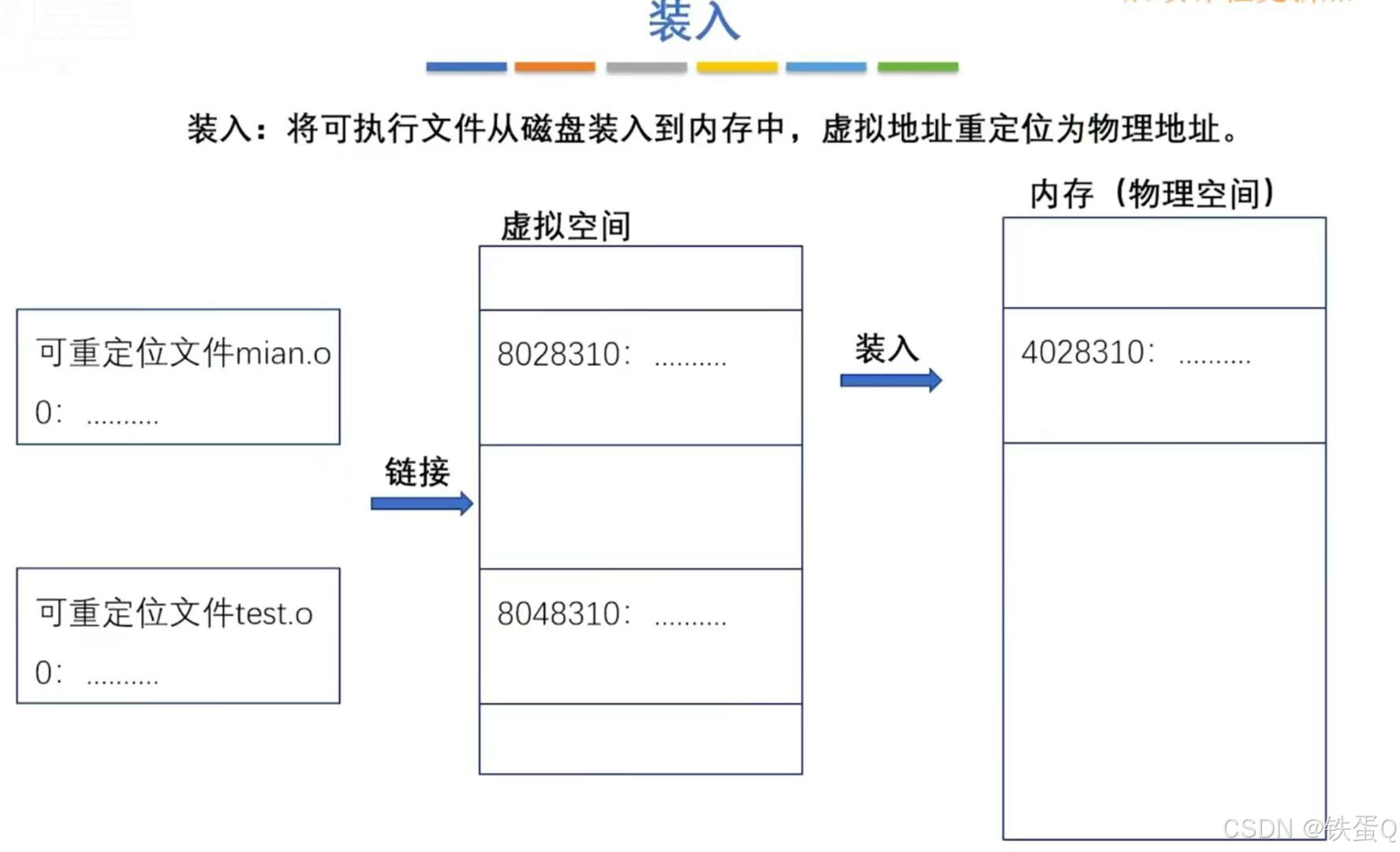
如果 x \textbf x x被创建为 y \textbf y y的噪声版本,我们的模型可以被表述为去噪自编码器。具体来说,给定一个如上定义的时间事件序列 y \textbf y y,我们首先通过连续执行下面的两个转换函数来破坏它以获得所需的输入 x \textbf x x(见图 2):
(1)Event Shuffling。我们首先对 y \textbf y y中的事件进行随机打乱以产生 x \textbf x x。为了完美地重建原始序列 y \textbf y y,模型必须捕捉事件之间的时间关系。
(2)Event Deletion。我们以概率 p p p随机删除 y \textbf y y中的每个事件以产生 x \textbf x x。这种去噪方案类似于 Lewis et al. (2020) 的token deletion操作。为了完美地重构原始事件序列,模型需要对类模式事件知识进行编码,以生成不包含在输入 x \textbf x x中的事件并将它们插入到正确的位置。因此,这种去噪可以帮助模型学习事件填充。
我们训练我们的模型以在这个自动构建的数据上最大化 l o g P ( y ∣ x ) log~P(\textbf y|\textbf x) log P(y∣x)。
3.2 Model Architecture
为了利用预训练transformers的强大功能,我们采用 BART 作为我们模型的底层架构,并使用其预训练权重初始化我们的模型。
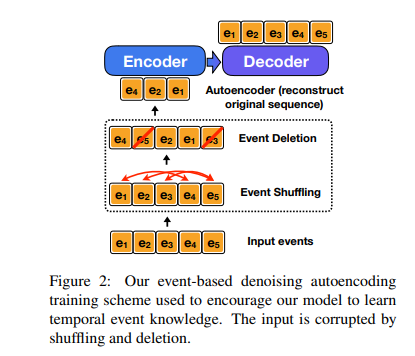
整个模型如图 3 所示,将损坏的事件序列 x = { e i } \textbf x=\{e_i\} x={ei} 作为输入,并输出真实的事件序列 y = { e j } y=\{e_j\} y={ej}。要将基于事件的输入和输出提供给 BART,我们需要以文本格式 R e p r ( e ) Repr(e) Repr(e) 表示每个事件 e e e。 我们用它的谓词和所有论述的串联来表示 e e e。与之前仅使用谓词和某些论述的句法头的工作不同,我们的方法保留了复杂的名词短语论述,并显示模型需要的论述,如时间修饰符。我们在使用足够的信息来表示有意义的事件和不使用整个文档之间取得平衡,这会使得模型过度依赖于话语线索。接下来,我们考虑输入和输出的两种变体:
(1)TemporalBART。该模型首先将 x x x中的每个事件 e i e_i ei编码为 R e p r ( e i ) Repr(e_i) Repr(ei),并将它们与每个事件前面的特殊标记 [ E ] [E] [E]连接起来。这个特殊的标记可以帮助模型识别输入事件之间的边界.此类占位符已用于相关任务,例如文本中的实体跟踪。对于输出,我们改为在每个 R e p r ( e j ) Repr(e_j) Repr(ej)前面加上 [ E ] v e j [ A ] [E]~v_{e_j}~[A] [E] vej [A]。这种设置不仅提供了一个额外的监督信号,鼓励模型根据谓词预测排序,而且还允许我们通过检查生成的谓词部分来事后恢复事件序列。
(2)TemporalBART-indexed。该模型(如图 3 所示)使用与 TemporalBART 相同的输入和输出格式,只是在每个事件 e i e_i ei之前添加了特殊字符 [ E ] [E] [E] 以代替 [ E i ] [Ei] [Ei]。对于输出,如果 e j e_j ej是输入事件之一并且 e j = e i e_j=e_i ej=ei,那么我们还将前置字符 e j e_j ej 更改为 [ E i ] v e j [ A ] [Ei]~v_{e_j}~[A] [Ei] vej [A]。否则,我们仍然使用 [ E ] [E] [E]作为特殊事件字符。请注意,该模型无法“欺骗”使用 [Ei] 令牌进行预测,因为输入事件是由 §3.1 中描述的混洗去噪训练方案打乱的。与 TemporalBART 相比,这里使用 [Ei] 为模型提供了额外的线索,将输入事件与输出事件相关联,这有利于事件排序。它还提供了一种潜在的方法,可以只关注对目标序列的排序进行建模,而不是混合生成决策,其中许多是复制事件参数并经常影响预测。
这些基于 BART 的模型的训练细节在附录中进行了描述。
3.3 Training Data Collection
对于我们的框架,我们需要的训练数据是temporal order的事件序列。请注意,大多数文本数据发生在 discourse order中,这是不一样的,例如像TimeBank等标注的时间关系数据集会显示文本中早期提到的事件后面将会出现。现有的时间关系数据集是小规模的,并且标注更多数据是代价昂贵的。为了解决这个问题,我们试图自动收集我们需要的训练数据。
Corpus。我们使用英语EventsNarratives语料库,其中包含来自三个不同源域的200,000个叙事结构文件,包括新闻文章,小说书籍和博客。Yao and Huang (2018) 使用弱监督方法来识别描述了一系列事件的叙述文本,以便 discourse order非常可能反映temporal order。这为我们提供了从每个文档中自动收集时间事件序列的方法。在这里,我们将专注于小说领域中的文档作为临时事件序列的源。
Extracting Temporal Event Sequences。要获取训练的事件序列,我们首先使用来自Hallennlp的SRL模型提取谓词(事件)及其论述。然后,通过仅连接不同句子中的事件来构建时间事件序列,因为在叙述文档中同一句子内的事件之间的关系是不明确的。 这里,为了确保序列中的所有事件彼此具有很强的关系,我们仅包括与常用实体相关联的事件链,如通过检查两个事件的论述是否具有一些共享的非停用字符来确定的。通过此过程,我们能够收集近200万的时间事件序列来训练,近70%的序列由三个或更多事件组成。
4.Target Task Formulation
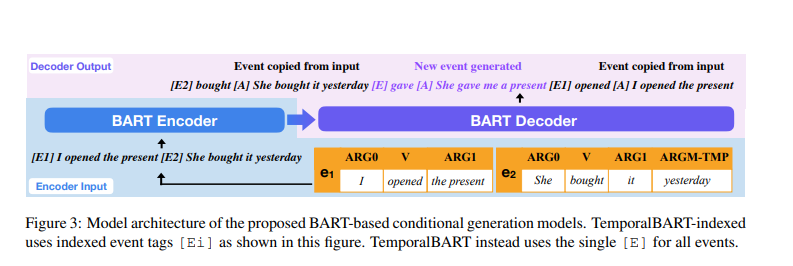
在这里,我们描述了模型的两个目标任务以及如何处理基于事件的条件生成问题。任务的目标定义如图4所示。
Temporal Event Ordering。给定无序的事件 { e i } \{e_i\} {ei},此任务的目标是生成 { e i } \{e_i\} {ei}的时间顺序,如图4(a)所示。给定集合 { e i } \{e_i\} {ei},我们要求模型生成顺序排列的事件序列 { e f ( i ) } \{e_{f(i)}\} {ef(i)},其中 f ( ⋅ ) f(·) f(⋅)是确定事件 i i i正确放置位置的映射函数。这是我们所提出的模型直接解决的条件生成问题。
Event Infilling。事件填充的目标是在原始事件序列中的某些预先选择的位置处生成事件。为了简化评估,这里我们假设给定事件序列 x = { e i } \textbf x=\{e_i\} x={ei},模型被要求在一个插入位置 i ∗ i^* i∗处生成一个插入的事件,如图4(b)所示。我们首先将 e i {e_i} ei作为模型的输入,然后使用 x p r e f i x = { e i ∣ i < i ∗ } \textbf x_{prefix}=\{e_i|i<i^*\} xprefix={ei∣i<i∗} 作为解码前缀来生成一个事件 e ∗ e^* e∗。为了强制模型生成的事件 e ∗ ∉ x e^*\notin \textbf x e∗∈/x,我们会在解码过程中防止我们的模型生成 { v e i } \{v_{e_i}\} {vei}。
4.1 Baselines: Temporal Event Ordering
我们的模型与两条基线进行比较:用于上下文时间排序任务的一个成对模型和直接模拟事件排列的指针网络模型。
BERT-based Pairwise Model + SSVM。我们使用 Han et al. (2019a) 中的深度SSVM模型结构作为我们的第一个基线,将事件排序作为成对分类问题解决。该网络首先利用基于BERT的模型来计算输出 y \textbf y y中 e j e_j ej的 e i e_i ei的成对分数。然后通过在所有成对分数上求解ILP来获得最终输出。整体网络的训练使用结构化SVM loss,以便可以学习通过传递限制进行联合预测。为了使这个基线更媲美我们的模型,我们将 R e p r ( e i ) Repr(e_i) Repr(ei)前添加 [ E ] [E] [E]作为事件表示,而不是使用包含 v e i v_{e_i} vei的句子。详细的公式在附录B中。在实验中,我们将该基线表示为“Pairwise+SSVM”。
BERT-based Pointer Network。该网络首先使用 BERT-based Pairwise Model + SSVM 以提取每个 e i e_i ei的矢量化表示 U p i \textbf U_{p_i} Upi,其中 U \textbf U U是最终BERT编码矩阵,并且 p i p_i pi是输入序列中 e i e_i ei的第一字符的位置。然后,将这些事件表示带入基于LSTM的指针网络以通过以顺序方式分解它来模拟排序概率:
P s e q ( y ∣ x ) = ∏ j P ( j ∣ h 1 , . . . , U p 1 ) (1) P^{seq}(\textbf y|\textbf x)=\prod_{j}P(j|\textbf h_1,...,\textbf U_{p_1})\tag{1} Pseq(y∣x)=j∏P(j∣h1,...,Up1)(1)
其中, h t \textbf h_t ht是指针网络中的解码器隐藏状态。与上述成对基线相比,该模型具有更强的归纳偏差,善于利用全局事件关系。我们用teahcer forcing训练模型,以最大限度地提高golden顺序的概率。在实验中,我们将该基线表示为“BERT-based PN”。
4.2 Baselines: Event Infilling
HAQAE。HAQAE是一个矢量量化变分自编码器,其编码具有分层潜在变量的模式知识。由于HAQAE也是一个事件级seq2seq自编码器,我们可以轻松将其应用于我们的实验。在训练期间,我们与 Weber et al. (2018b) 配置相同,除了我们使用我们的事件序列数据进行训练,并以§3.2中描述的数据格式表示每个事件,因此它与基于BART的模型更可比。
GPT-2。GPT-2是一种基于transformer的预训练语言模型,它已被利用在各种生成任务中,如故事生成。但是,GPT-2模型的一个问题是它只能执行单向生成。为了将GPT-2应用到生成插入的事件 e ∗ e^* e∗,我们首先连接 { R e p r ( e i ) ∣ e i ∈ x p r e f i x } \{Repr(e_i)|e_i∈\textbf x_{prefix}\} {Repr(ei)∣ei∈xprefix}之间的事件,并仅将其视为解码前缀。然后我们解码直到生成另一个事件,并将模型的输出作为 e ∗ e^* e∗的文本内容。除非另有说明,我们使用来自HuggingFace的transformer的GPT2-medium预训练模型,其模型大小与BART-large相当。
Infilling GPT-2。为了构建不仅以前缀事件为条件的更强大的GPT-2基线,我们遵循 Qin et al. (2020) 的基线使GPT-2适应填充任务。Infilling GPT-2通过同时引入插入事件前后的事件来生成填充事件。也就是说,馈送到infilling GPT-2的解码前缀成为 { R e p r ( e i ) ∣ i > = i ∗ } \{Repr(e_i)|i>=i^∗\} {Repr(ei)∣i>=i∗}, < s e p > <sep> <sep>和 { R e p r ( e i ) ∣ i < i ∗ } \{Repr(e_i) | i < i^∗\} {Repr(ei)∣i<i∗}的串联。特殊字符 < S E P > <SEP> <SEP>用于帮助模型区分插入位置之前和之后事件。
这篇关于Conditional Generation of Temporally-ordered Event Sequences翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!