sequences专题

Learning Temporal Regularity in Video Sequences——视频序列的时间规则性学习
Learning Temporal Regularity in Video Sequences CVPR2016 无监督视频异常事件检测早期工作 摘要 由于对“有意义”的定义不明确以及场景混乱,因此在较长的视频序列中感知有意义的活动是一个具有挑战性的问题。我们通过在非常有限的监督下使用多种来源学习常规运动模式的生成模型(称为规律性)来解决此问题。体来说,我们提出了两种基于自动编码器的方法,以

CodeForces 425C Sereja and Two Sequences
题意: 两组数字a和b 如果a[i]等于b[j] 则可将a[i]和b[j]前所有数字删掉 这种操作花费e体力 得到1元钱 或者一次删掉所有数字 这种操作花费等于曾经删除的所有数字个数 做完后得到所有钱 问 一共s体力 可以得到多少钱 思路: dp+二分 由数据可知最多拿到300元钱 因此可以定义 dp[i][j]表示有i元钱时 b串删除到了j处时 a串删到的位

Codeforces Round #FF (Div. 2/C)/Codeforces446A_DZY Loves Sequences(DP)
DZY Loves Sequences time limit per test 1 second memory limit per test 256 megabytes input standard input output standard output DZY has a sequence a, consisting of n integers. We'
NLP-文本匹配-2016:Compare-Aggregate【A Compare-Aggregate Model for Matching Text Sequences】
NLP-文本匹配-2016:Compare-Aggregate【A Compare-Aggregate Model for Matching Text Sequences】

论文笔记:GEO-BLEU: Similarity Measure for Geospatial Sequences
22 sigspatial 1 intro 提出了一种空间轨迹相似性度量的方法比较了两种传统相似度度量的不足 DTW 基本特征是它完全对齐序列以进行测量,而不考虑它们之间共享的局部特征这适用于完全对齐的序列,但不适用于逐步对齐没有太多意义的序列BLEU 适用于不完全对齐的序列将序列中的地点视为单词,它们的连续组合视为地理空间𝑛-gram,应用这种方法基于局部特征评估地理空间轨迹的相似性然而,

【矩阵快速幂 】Codeforces 450B - Jzzhu and Sequences (公式转化)
【题目链接】click here~~ 【题目大意】 Jzzhu has invented a kind of sequences, they meet the following property: You are given x and y, please calculate fn modulo1000000007(109 + 7). 【解题思路】 solution

codeforces#FF DIV2C题DZY Loves Sequences(DP)
题目地址:http://codeforces.com/contest/447/problem/C C. DZY Loves Sequences time limit per test 1 second memory limit per test 256 megabytes input standard input output standard outpu
Repeated DNA Sequences问题及解法
问题描述: All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: "ACGAATTCCG". When studying DNA, it is sometimes useful to identify repeated sequences within the DNA.
POJ2034 Anti-prime Sequences【素数筛法】【DFS】
题目链接: http://poj.org/problem?id=2034 题目大意: 给你三个整数 N、M、D。使得从 N 到 M 的自然数按要求排列后,相邻且连续的 D 个数内的自然数和为非素数。找到字典序最小的排列并输出,如果找不到则输出 "No anti-prime sequence exists."。 解题思路: 用深搜来做,一步一步的确定第 Cnt 个数,直到

序列化推荐的图模型——Selecting Sequences of Items via Submodular Maximization(更新中)
本文介绍一种基于图模型的序列化推荐方法:OMEGA。文章来自AAAI-17,题目为《Selecting Sequences of Items via Submodular Maximization》,作者是来自苏黎世联邦理工学院的Sebastian Tschiatschek,Adish Singla 以及Andreas Krause。 背景 子集选择问题 首先,介绍一下子集选择问题,该问题的
HDU - 3450 Counting Sequences
题意:求个数大于等于2的序列,要求每相邻的两个的大于d,求满足的个数 思路:同样是树状数组的应用,跟前面两题类似,求每次加入的a[i],先求范围在[a[i]-d,a[i]+d]的个数,再加到a[i]上,加一加的是本身,还有要注意的是,要减去1个的情况,跟前面两题不一样, #include <iostream>#include <cstdio>#include <cstring>#in
Codechef Sam and Sequences(单调队列)
题目链接:http://www.codechef.com/problems/PRYS03/ 这题只要考虑每个数字,最左和最右分别能延伸到的位置,然后就能计算出每个数字需要计算的次数,由于数字可能重复,所以对于左边维护到不大于的第一个数字位置,右边维护到小于的第一个数字位置,然后维护好后,在扫一遍计算总和即可 代码: #include <cstdio>#include <cstring>
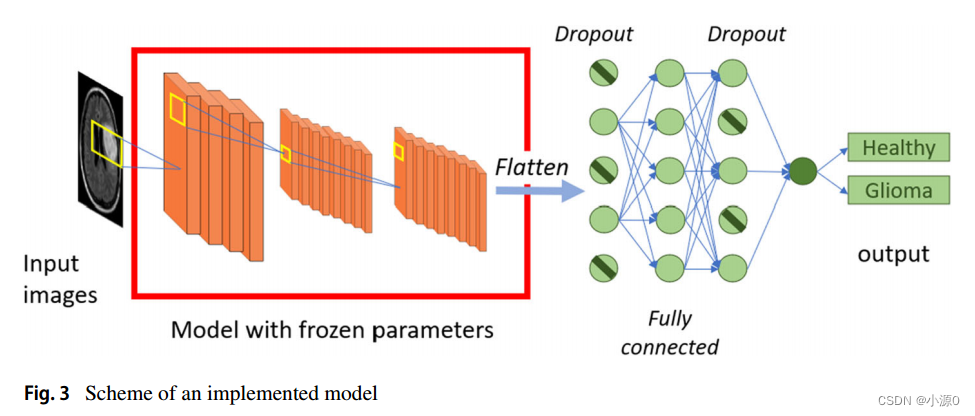
论文阅读:A multi-sequences MRI deep framework study applied to glioma classfication
论文标题: A multi-sequences MRI deep framework study pplied to glioma classfication 翻译: 多序列MRI深度框架研究在胶质瘤分类中的应用 摘要 胶质瘤是最重要的中枢神经系统肿瘤之一,在男性和女性最常见的癌症中排名第15位。磁共振成像(MRI)是医学专家诊断神经胶质瘤的常用工具。根据病理的严重程度,从MRI中选择一组多序

Big Bird: Transformers for Longer Sequences论文详解
文章目录 Big Bird大鸟模型论文要解决问题解决方法随机注意力固定窗口注意力全局注意力复杂度分析 实验三种注意力的消融实验。语言模型对比roberta、longformerQA问题中对比longformer长文本分类任务文章摘要任务基因语言模型实验 如有问题欢迎指出,参考论文https://arxiv.org/abs/2007.14062 Big Bird大鸟模型 论文要解决
C. DZY Loves Sequences
C. DZY Loves Sequences time limit per test 1 second memory limit per test 256 megabytes input standard input output standard output DZY has a sequence a, consisting of n integers.
Codeforces 1272 F Two Bracket Sequences —— bfs+dp
This way 题意: 现在有两个串,让你构造一个母串使得这两个串是这个串的子串,并且这个串要平衡,长度最小。输出这个串 题解: 不太会做,看了题解才发现原来还有这种思考方法,不要将思维固定。 dp[i][j][k]表示第一个串到第i个位置,第二个串到第j个位置时,左括号比右括号多k个的最少长度 那么每次新增一个位置的时候只有两种情况,判断一下是否出现过。用一个pre数组记录每个情况新增
tf.contrib.keras.preprocessing.sequence.pad_sequences 将标量数据 转换成numpy ndarray
keras.preprocessing.sequence.pad_sequences(sequences, maxlen=None, dtype=’int32’, padding=’pre’, truncating=’pre’, value=0.) 函数说明: 将长为nb_samples的序列(标量序列)转化为形如(nb_samples,nb_timesteps)2D numpy array。
2022 CCPC 广州站 个人题解 B. Ayano and sequences
Analysis 传送门:https://codeforces.com/gym/104053/problem/B 首先考虑区间赋值的影响: 如果是离散区间合并为一个区间,那么区间总数减少;如果是大区间包含分割区间,那么每次操作至多产生 2 2 2个新区间。 由于是区间赋值,因此我们考虑用一个类似珂朵莉树的思想来维护每条连续线段,然后发现如果某条线段在一段连续的时间内没有被改变,那么它会在时
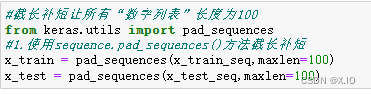
【AI学习笔记】AttributeError: module ‘keras.preprocessing.sequence‘ has no attribute ‘pad_sequences‘
报错: AttributeError: module ‘keras.preprocessing.sequence’ has no attribute ‘pad_sequences’ 看了许多博客,说是版本问题,我的版本都是2.11.0 解决方法 有的人说: 将 from keras.preprocessing import sequence 改为 from keras_preproces
Codeforces 450B - Jzzhu and Sequences
Jzzhu has invented a kind of sequences, they meet the following property: You are given x and y, please calculate fn modulo 1000000007 (109 + 7). Input The first line contains two integers x and
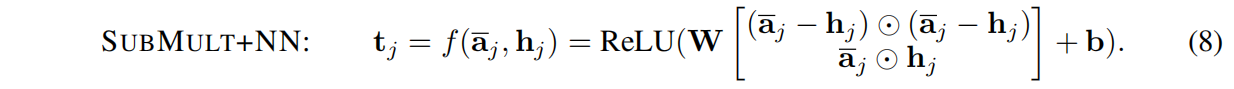
【文献阅读2】A Compare-Aggregate Model For Matching Text Sequences
A Compare-Aggregate Model For Matching Text Sequences(一个用于匹配文本序列的比较聚合模型) 注:转载请标明出处。相关论文链接:https://arxiv.org/pdf/1611.01747.pdf 1 摘要 NLP包括机器理解、答案选择、文本蕴含中的序列之间比较等任务。研究如何在序列之间,匹配重要单元是解决这些问题的关键。在本文中,我们
ViBe算法:ViBe - a powerful technique for background detection and subtraction in video sequences
原文:http://blog.csdn.net/stellar0/article/details/8777283 算法官网:http://www2.ulg.ac.be/telecom/research/vibe/ 描述: ViBe是一种像素级视频背景建模或前景检测的算法,效果优于所熟知的几种算法,对硬件内存占用也少。 Code: 算法执行效率测试程序,windows和l
tf.keras.preprocessing.sequence.pad_sequences
这个玩意是啥子?? pad_sequences(sequences, maxlen=None, dtype='int32', padding='pre', truncating='pre', value=0.0)Pads sequences to the same length. 这个不仅有补零的作用,还有截断的功能。 padding: String, 'pre' or 'p
poj 2034 Anti-prime Sequences
题意要求给定一个范围,然后指定一个区间d,使(2到d)的任意区间之和为合数即可。深搜枚举#include<stdio.h>#include<string.h>#include<iostream>using namespace std;int use[1001],prime[10001],vis[1001];int n,m,d,flag;bool dfs(int d,int th)

【长文阅读】MAMBA作者博士论文<MODELING SEQUENCES WITH STRUCTURED STATE SPACES>-Chapter2
Gu A. Modeling Sequences with Structured State Spaces[D]. Stanford University, 2023. 本文是MAMBA作者的博士毕业论文,为了理清楚MAMBA专门花时间拜读这篇长达330页的博士论文,由于知识水平有限,只能尽自己所能概述记录,并适当补充一些相关数学背景,欢迎探讨与批评指正。内容多,分章节更新以免凌乱。 Chap
《Two Dozen Short Lessons in Haskell》学习(十四)- Truncating Sequences and Lazy Evaluation
《Two Dozen Short Lessons in Haskell》(Copyright © 1995, 1996, 1997 by Rex Page,有人翻译为Haskell二十四学时教程,该书如果不用于赢利,可以任意发布,但需要保留他们的copyright)这本书是学习 Haskell的一套练习册,共有2本,一本是问题,一本是答案,分为24个章节。在这个站点有PDF文件。几年前刚开始学习