本文主要是介绍【文献阅读2】A Compare-Aggregate Model For Matching Text Sequences,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
A Compare-Aggregate Model For Matching Text Sequences(一个用于匹配文本序列的比较聚合模型)
注:转载请标明出处。相关论文链接:https://arxiv.org/pdf/1611.01747.pdf
1 摘要
NLP包括机器理解、答案选择、文本蕴含中的序列之间比较等任务。研究如何在序列之间,匹配重要单元是解决这些问题的关键。在本文中,我们提出了一个通用的“比较聚合”框架,该框架执行单词级别的匹配,使用卷积神经网络进行聚合。本文主要研究可用于匹配两个向量的不同比较函数。我们使用四个不同的数据集来评估模型。 我们发现一些简单的基于逐元素运算的比较函数要比标准神经网络和神经张量网络表现更好。
2 绪论
文本序列(句子)匹配的应用情景,通俗点讲比如我们高中英语做的阅读理解,给定问题,匹配相关段落,找出正确答案。
在本文中,我们认为通用的“比较-聚合”框架可有效解决各种序列匹配问题。我们提出了一个遵循该通用框架的模型,并在四个不同的数据集(即MovieQA,InsuranceQA,WikiQA和SNLI)上对其进行了测试。前三个数据集用于Question Answering,但任务的设置完全不同。最后一个数据集用于文本蕴涵textual entailment。更重要的是,我们系统地展示和测试了六个不同的比较函数。总体而言,我们发现基于逐元素减法和乘法(element-wise subtraction and multiplication)的比较函数在四个数据集上表现最佳。
本文的贡献有二:
1)在四个不同的数据集上,我们证明了提出的遵循“比较-聚合”框架的模型,与这些数据集的state-of-the-art性能相比更加有效;
2)我们对不同的比较函数进行了系统评估。结果表明,基于元素操作的比较函数在不同的数据集上效果更佳,该比较函数目前未广泛应用于词级匹配。我们认为,这些发现将对将来的序列匹配问题研究提供帮助。我们还提供了github代码。
3 模型
在本节中,我们根据“比较-聚合”框架提出了一个通用模型,用于匹配两个序列。该通用模型可以应用于不同的任务。我们将讨论的重点放在可以插入到通用“比较-聚合”模型中的六个不同的比较函数上。特别是介绍了我们假设的基于逐元素运算的两个比较函数(SUB和MULT),这两个比较函数介于使用标准神经网络模型的函数和基于余弦相似度或欧氏距离的函数之间。正如我们将在实验部分中展示的那样,这些基于元素操作的比较函数确实可以在许多序列匹配问题上表现出色。
3.1 问题定义和模型概述
(注:为方便输入,我们将使用“ ’ ”来代替paper中的字母上方的“—”符号。如使用 Q’ 代表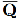 )
)
我们考虑的序列匹配问题问题定义如下。
我们假设有两个序列要匹配。我们使用两个矩阵Q∈Rd×Q和A∈Rd×A来表示两个序列的词嵌入(word embedding),其中 Q 和 A 分别是两个序列所含单词的长度,d 是词嵌入的维数,换句话说,Q和A的每个列向量都是表示单个单词的嵌入向量。
给定一对Q和A,目标是预测标签y。
例如,在文本蕴涵问题中,Q可以表示前提(premise),而A可以表示一个假设(hypothesis),而 y 表示蕴涵(entailment)或冲突(contradiction)。在回答问题过程中,Q可能是一个问题,而A可能是一个候选答案,y表示A是否是Q的正确答案。
文本蕴涵(textual entailment):
文本蕴含关系描述的是两个文本之间的推理关系。
一个文本作为前提(premise);另一个文本作为假设(hypothesis)。
如果根据 前提P 能够推理得出 假设H ,那么就说 P 蕴含 H 。
例:前提P:“一只狗在雪地里玩飞盘。”假设1:“一个动物正在寒冷室外玩玩具。”假设2:“一只猫蹲在角落里。”此时,假设1 和 前提 是蕴涵(entailment)关系,假设2 和 前提 是冲突(contradiction)关系。分别对应标签 y 为:蕴涵、冲突。
我们将问题视为监督学习任务。我们假设以(Q,A,y)的形式给出了一组训练示例,并且我们旨在学习一种可以将任意一对(Q,A)映射到 y 的模型。
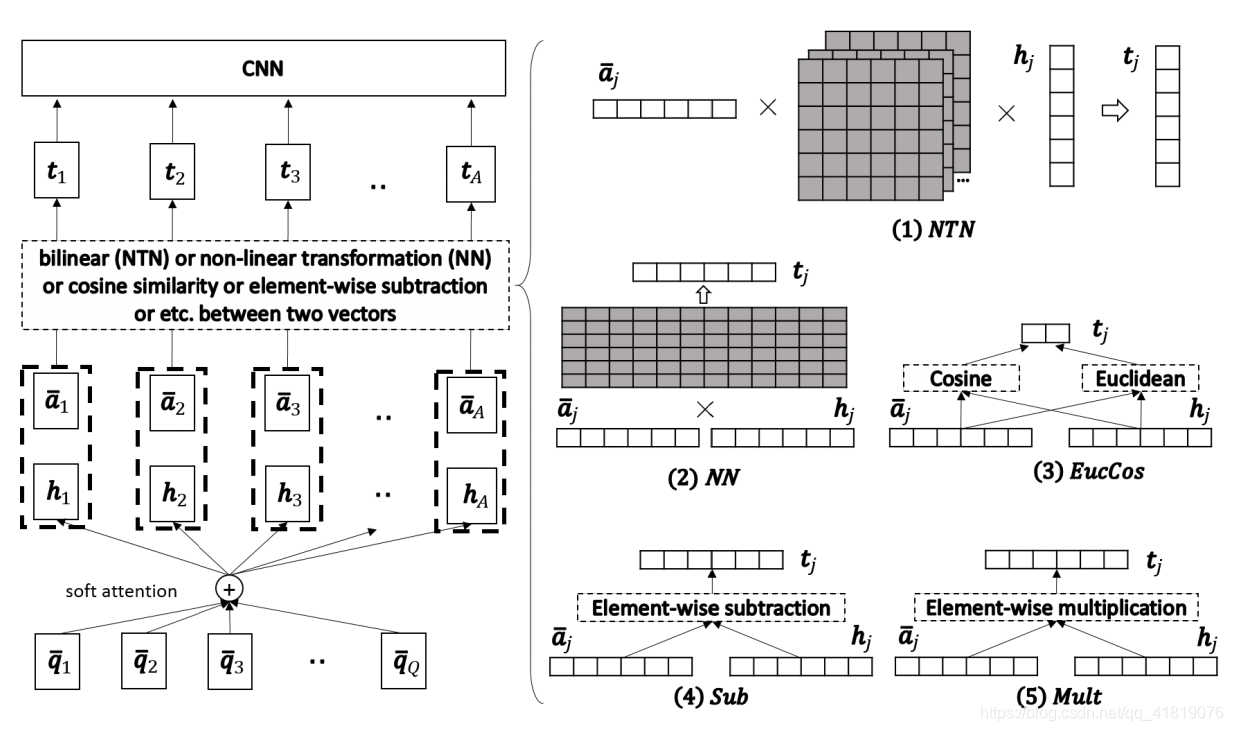
图1:左侧是模型概述。右侧显示了有关不同比较函数的详细信息。深色矩形代表要学习的参数。‘×’代表矩阵相乘。
我们的模型概述如图1所示。该模型可以分为以下四个层:
1.预处理层(图1中未显示):
我们使用预处理层来处理Q∈Rd×Q和A∈Rd×A,以获得两个新矩阵Q’∈Rl×Q和A’∈Rl×A。目的是使得每个序列中的每个单词,可以获取到一个含有该序列上下文信息的新嵌入矢量(诸如使用RNN、LSTM、GRU等)。 如,假设 q’i∈Rl 是 Q’ 的第i列向量,则 q’i 表示的是 Q 中的第i个单词和上下文的组合编码。
2.注意力机制:
我们对 Q’ 和 A’ 应用标准的注意力机制,以获得 A’ 中每个列向量对 Q’ 中列向量的注意力权重。有了这些注意力权重,对于 A’ 中的每个列向量 a’j ,我们获得了对应的向量 hj ,它是 Q’ 列向量的注意力加权总和。
(意思是利用 Q’ 矩阵求出对应 A’ 中每个列向量 a’j 的权重 αj ,其中 j∈1,2,…,A 。再将获得的 α 与 Q’ 矩阵相乘,得到向量h。)
3.比较层:
我们使用比较函数 f ,组合每一对a’j 和hj,得到向量tj。
4.聚合层:
我们使用CNN层来聚合向量tj,来进行最终分类。
在本节的其余部分中,我们将详细介绍该模型,并主要关注我们提出的比较函数。
3.2 预处理层和注意力机制
我们的预处理层使用的是递归神经网络,来处理这两个序列。我们使用LSTM / GRU的修改版,仅保留了用于记住单词的输入门:
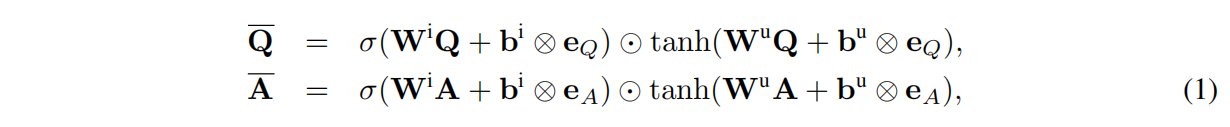
其中⊙为逐元素相乘, W 和 b 是要学习的参数,Wi、Wu ∈ Rl×d , bi、bu∈ Rl。“⊗eX”表示将偏置向量b重复X次。
注意力机制是在生成的 Q’ 和 A’ 之上构建的,如下所示:
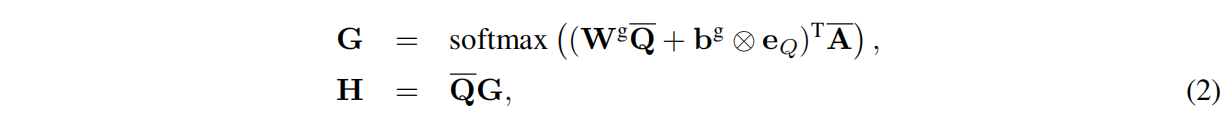
其中 Wg∈Rl×l 和 bg∈Rl 是要学习的参数,G∈RQ×A 是注意力权重矩阵,H∈Rl×A 是注意力加权向量。 具体地说,hj是H的第j个列向量,是Q’ 的列向量的加权和,表示 Q’ 和 A’ 中第j个词的最匹配部分。接下来,我们将使用比较函数将a’j 和 hj 组合。
3.3 比较层
比较层的目标是将每个a’j (代表A’ 中的第j个单词及其上下文)和 hj (代表最匹配a’j 的 Q’ 的加权版本)匹配。令 f 表示比较函数,该函数将a’j 和 hj 转换为向量 tj 以表示比较结果。
方案1
f的自然选择是标准神经网络层,该层由线性变换和非线性激活函数组成。
例如,我们可以考虑以下选择: 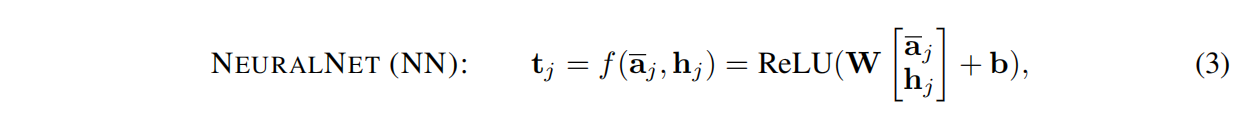
其中矩阵W∈Rl×2l和向量b∈Rl是要学习的参数。
方案2
另一个自然选择是神经张量网络,如下所示:
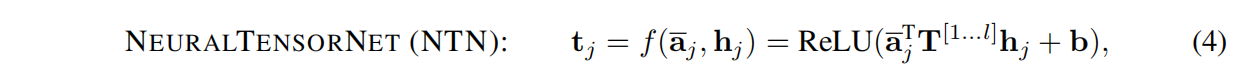
其中张量 T[1…l]∈Rl×l×l和向量b∈Rl是要学习的参数。
方案3
我们注意到,对于许多序列匹配问题,我们打算测量两个序列的语义相似性或相关性。因此,在先前的工作中使用的更自然的选择是a’j 和 hj 之间的欧式距离或余弦相似度。 因此,我们考虑f的以下定义:
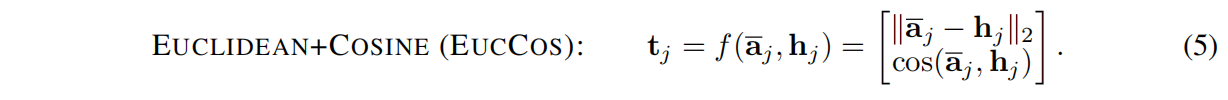
请注意使用EUCCOS,结果向量tj 仅为二维向量。
方案4、5、6
尽管EUCCOS是一个合理的比较函数,但我们怀疑它可能会从原始向量a’j 和 hj 中丢失一些有用的信息。 另一方面,NN和NTN太笼统了,因此没有得到我们最关心a’j 和 hj 之间相似性。为了找到在以上两种极端情况间的折衷方案,我们考虑以下两个新的比较函数,它们对两个向量进行逐元素运算。
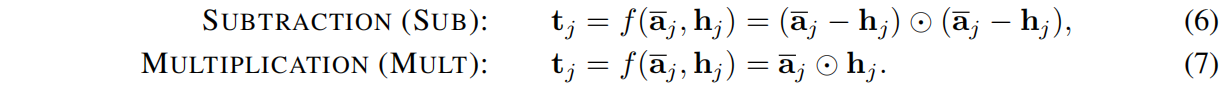
注意,⊙为逐元素相乘。 对于这两个比较函数,所得向量 tj 都具有与a’j 和 hj 相同的维数。
我们可以看到SUB与欧式距离密切相关,欧式距离可以看做是SUB产生的所有 tj 项的总和。 但由于SUB不再对这些项进行求和运算,所以保留了一些有关原始两向量的不同维度信息。 同样,MULT与余弦相似度密切相关,也保留了有关原始两向量的一些信息。
最后,我们考虑结合SUB和MULT,然后再加上NN层,如下所示:
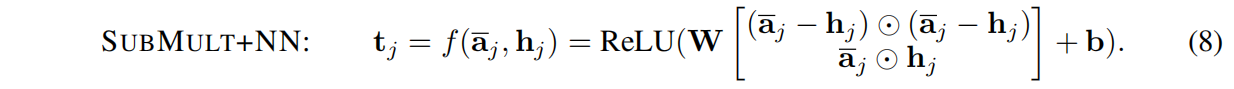
上述,我们考虑了六个不同的比较函数:NN,NTN,EUCCOS,SUB,MULT和 SUBMULT+NN。 在这些函数中,后三个函数(SUB,MULT和SUBMULT+NN)尚未在以前的工作中广泛应用于单词级匹配。
3.4 聚合层
最后我们使用一层CNN聚合 tj 向量。
这篇关于【文献阅读2】A Compare-Aggregate Model For Matching Text Sequences的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!