aggregate专题

NLP-文本匹配-2016:Compare-Aggregate【A Compare-Aggregate Model for Matching Text Sequences】
NLP-文本匹配-2016:Compare-Aggregate【A Compare-Aggregate Model for Matching Text Sequences】

Spark算子:RDD行动Action操作(3)–aggregate、fold、lookup
aggregate def aggregate[U](zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)(implicit arg0: ClassTag[U]): U aggregate用户聚合RDD中的元素,先使用seqOp将RDD中每个分区中的T类型元素聚合成U类型,再使用combOp将之前每个分区聚合后的U类型聚合成U类型,特别注意se

hadoop学习;Streaming,aggregate;combiner
文章来源:http://www.itnose.net/detail/6044147.html 更多文章:http://www.itnose.net/type/119.html hadoop streaming允许我们使用任何可执行脚本来处理按行组织的数据流,数据取自UNIX的标准输入STDIN,并输出到STDOUT 通过设定mapper为‘RandomSample.py 10’,我们按十分之一
reducer里aggregate函数的使用
1.streaming的作用 Haoop支持用其他语言来编程,需要用到名为Streaming的通用API。 Streaming主要用于编写简单,短小的MapReduce程序,可以通过脚本语言编程,开发更快捷,并充分利用非Java库。 HadoopStreaming使用Unix中的流与程序交互,从stdin输入数据,从stdout输出数据。实际上可以用任何命令作为mapper和reducer。
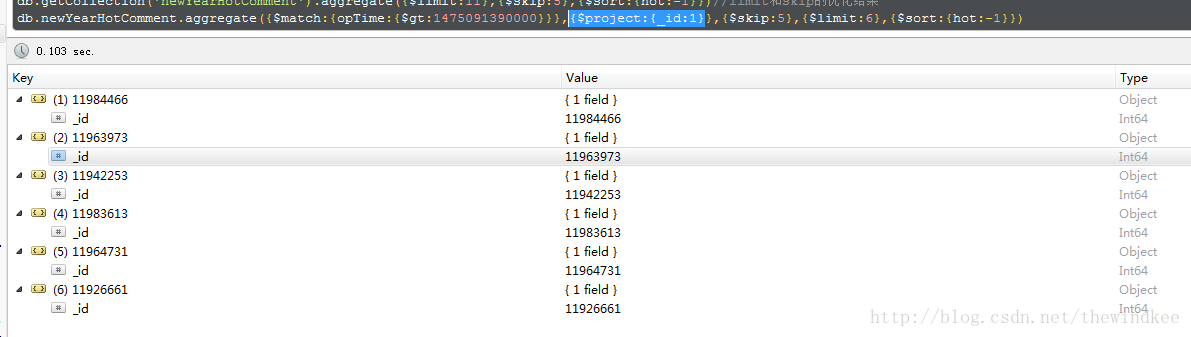
【Mongodb】aggregate限制返回字段
使用$project即可 db.xx.aggregate({$project:{_id:1}}) db.xx.aggregate({$match:{opTime:{$gt:1475091390000}}},{$project:{_id:1}},{$skip:5},{$limit:6},{$sort:{hot:-1}}) 基本的操作包括: •$project - 可

python使用pivot_table长表转宽表报错:No numeric types to aggregate 解决办法
python使用pivot_table长表转宽表报错:No numeric types to aggregate 解决办法 首先查看数据的类型 再将数据类型强制转换 赋值给原数据 长表与宽表的相互转换
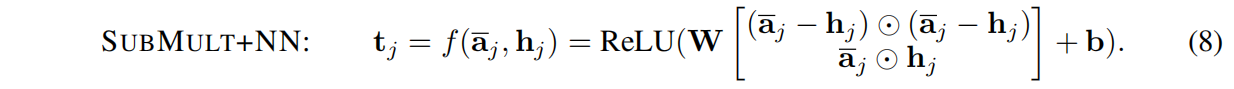
【文献阅读2】A Compare-Aggregate Model For Matching Text Sequences
A Compare-Aggregate Model For Matching Text Sequences(一个用于匹配文本序列的比较聚合模型) 注:转载请标明出处。相关论文链接:https://arxiv.org/pdf/1611.01747.pdf 1 摘要 NLP包括机器理解、答案选择、文本蕴含中的序列之间比较等任务。研究如何在序列之间,匹配重要单元是解决这些问题的关键。在本文中,我们
SQL Error:An aggregate may not appear in the set list of an UPDATE statement.
原来sql语句: update [dbo].[TableA] set ColumnA=Count(*) from [dbo].[TableB]改后: update [dbo].[TableA] set ColumnA=tmpTable.ColumnB from( select Count(*) as ColumnB from [dbo].[TableB] )tmpTable
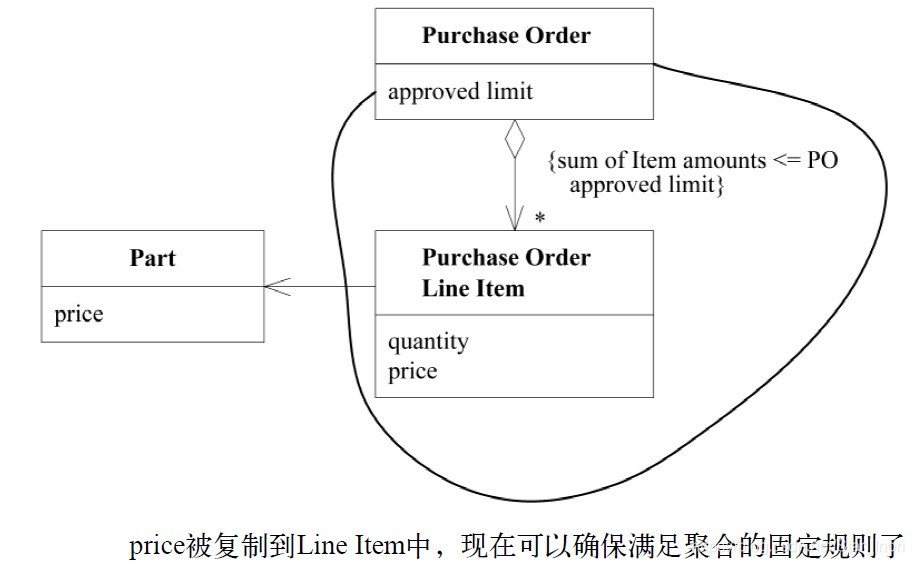
模式:AGGREGATE
目录 模式:AGGREGATE 所有事务应用一组规则(重要) 采购订单的完整性(例子) 模式:AGGREGATE 减少设计中的关联有助于简化对象之间的遍历,并在某种程度上限制关系的急剧增多。但大多数业务领域中的对象都具有十分复杂的联系,以至于最终会形成很长、很深的对象引用路径,我们不得不在这个路径上追踪对象。在某种程度上,这种混乱状态反映了现实世界,因为现实世界中就很少有清晰的
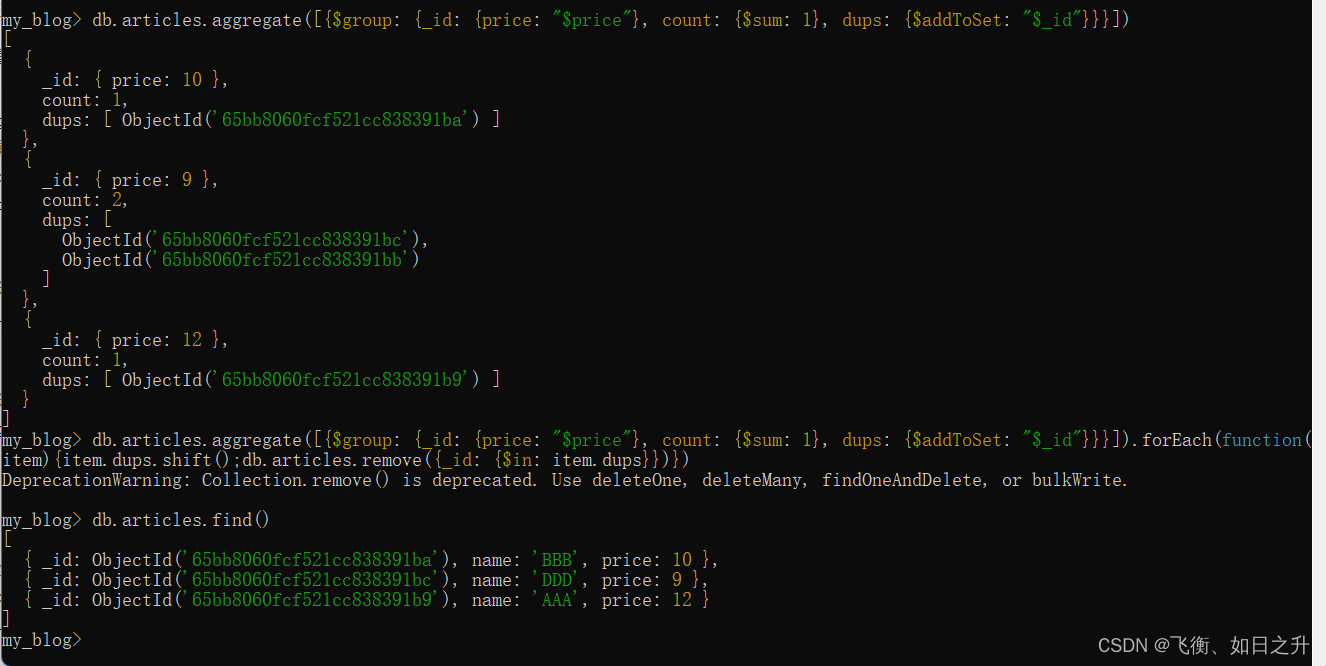
node 第二十四天 mongoDB shell 命令 高级方法 $where aggregate聚合
$where 数据库数据如下 使用where语法如下 等价于 2.aggregate 聚合 使用聚合管道执行聚合操作。该管道允许用户通过一系列基于阶段的操作来处理来自集合或其他源的数据。 过滤数据, 分组数据 (排除name为 AAA 的数据 按price进行分组 每匹配一组计数+1) 下面我们用aggregate删除重复文档

mongodb在aggregate lookup 进行分页查询,获得记录总数
直接上代码: const ones = await InspectTaskUser.aggregate([{$facet: {paginatedResult: [{ $match: { user_id: ObjectId(_id) } },{ $skip: (page - 1) * size },{ $limit: size },{$lookup: {from: 'inspecttask

Aggregate Signatures with Versatile Randomization and Issuer-Hiding Multi-Authority Anonymous Creden
目录 笔记后续的研究方向摘要引言去中心化身份去中心化环境中的隐私分散环境中的AC聚合签名贡献具有随机化功能的聚合签名颁发者隐藏多机构匿名凭据 Aggregate Signatures with Versatile Randomization and Issuer-Hiding Multi-Authority Anonymous Credentials. CCS 2023
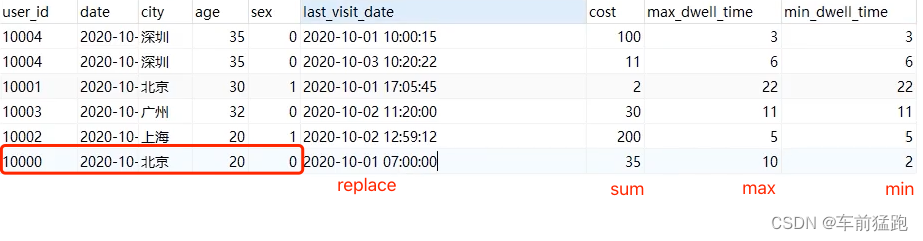
doris数据模型,06-Aggregate(聚合模型)
聚合模型的特点 将表中的列分为Key和Value。 Key是数据的维度列,比如时间,地区等等。key相同时会发生聚合。 Value是数据的指标列,比如点击量,花费等等。 每个指标列还会有自己的聚合函数,如:sum,min,max,bitmap_union等。数据会根据维度列进行分组,并对指标列进行聚合。 在3中机制下会发生聚合: 导入数据(insert, load等)BE内部Compacti

MongoDB 中的关联查询MongoDB : aggregate/lookup 对比 Mongoose : ref / populate
摘自 : MongoDB 中的关联查询 mongoosejs : Populate 官方文档 mongodb : lookup 官方文档 一、前言 数据库设计中数据之间的关联关系是极其常见的:一对一、一对多、多对多,作为 NoSQL 领头羊的 MongoDB 中常用做法无非「内嵌」和「引用」两种, 因为 Document 有 16MB 的大小限制[1]且「内嵌」不适合复杂的多
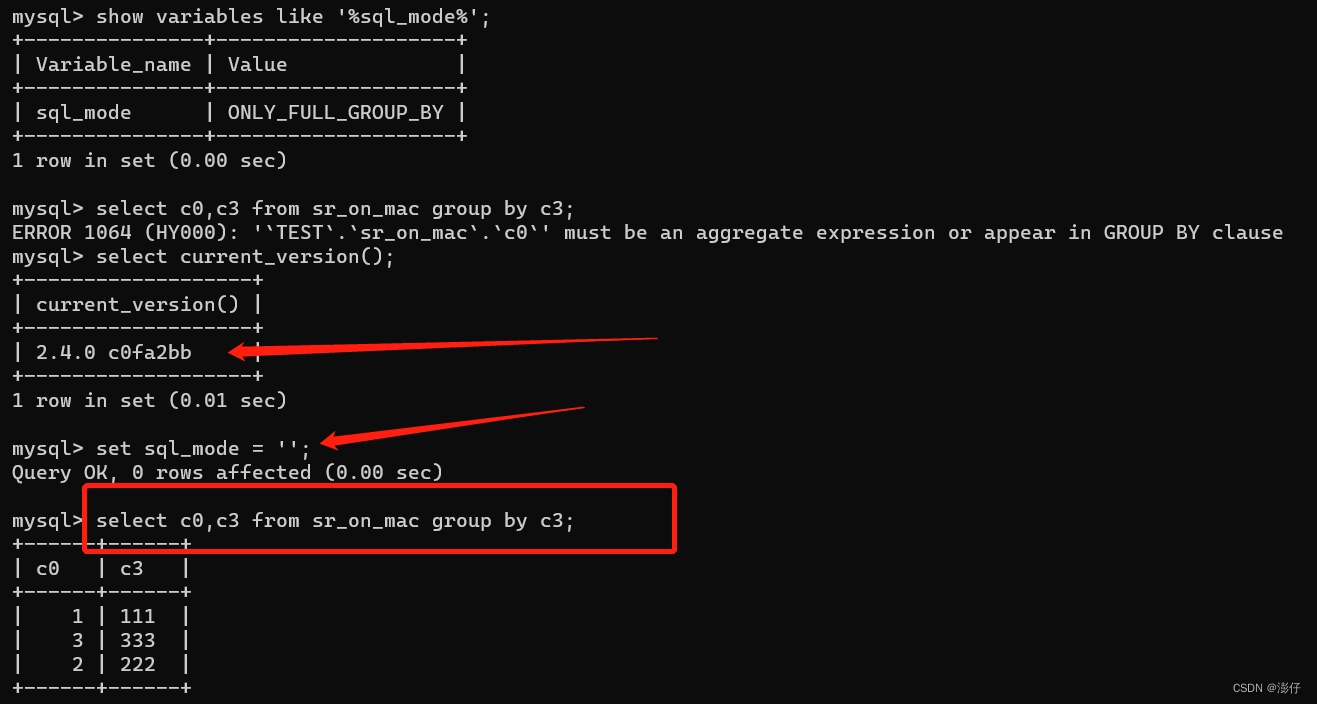
StarRocks must be an aggregate expression or appear in GROUP BY clause
StarRocks在SQL查询时报错must be an aggregate expression or appear in GROUP BY clause 这个报错信息主要就是select查询的列没有使用聚合函数或者没有包含在GROUP BY中 例如 select c1, c2 from table group by c1; c2这一列没有使用聚合函数,也不在group by子句中 解

mysql聚合函数和group_aggregate 例子
MySQL中的聚合函数是一组特殊的函数,用于处理一组值并返回单个值。它们通常与GROUP BY子句一起使用,用于对结果集进行分组,并对每个分组应用计算。 以下是MySQL中常见的聚合函数: COUNT(): 计算结果集中的行数。 SUM(): 计算指定列的总和。 AVG(): 计算指定列的平均值。 MAX(): 返回指定列的最大值。 MIN(): 返回指定列的最小值。 GROUP_CONCAT
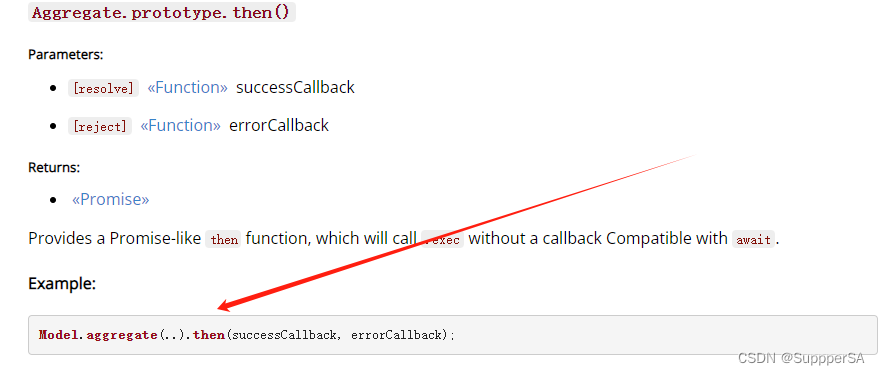
node.js mongoose Aggregate介绍
目录 简述 Aggregate的原型方法 aggregate进行操作 简述 在 Mongoose 中,Aggregate 是用于执行 MongoDB 聚合操作的类。MongoDB 聚合操作是一种强大的数据处理工具,可以用于对集合中的文档进行变换和计算 通过Model.aggregate创建一个aggregate(Aggregate类的实例) const aggrega


Mongodb——Aggregate
聚合概念: 聚合是处理数据记录并且返回计算结果的操作。mongodb提供了一组强大针对数据集合进行检查和计算的聚合操作。在mongod实例中运行数据聚合可以简化应用程序代码,约束资源需求;和查询一样,在mongodb中聚合操作把文档的集合作为输入参数,以一个或者多个文档的形式返回结果。 在mongodb中使用聚合框架可以对集合中的文档进行变换和组合。基本上用多个构建创建一个管道(pipelin
error: aggregate value used where an integer was expected
问题描述: 把struct结构体类型数据,强制转换成unsigned long 不能进行转换的原因是因为结构类型(包括 union)不是数量类型(Scalar Type);只有在数量类型之间才能进行转换。数量类型包括算术类型和指针类型,算术类型由包括整数类型和浮点类型。 哪怕是 struct in_addr 类型: struct in_addr{

Java设计模式 七大原则(七) 组合/聚合复用原则(Composite/Aggregate Reuse Principle CARP)
尽量使用合成/聚合达到复用,尽量少用继承。原则: 一个类中有另一个类的对象。 1.概念: 合成/聚合复用原则(Composite/Aggregate Reuse Principle,CARP)经常又叫做合成复用原则。合成/聚合复用原则就是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分;新的对象通过向这些对象的委派达到复用已有功能的目的。它的设计原则是:要尽量使用合成/聚合,尽量
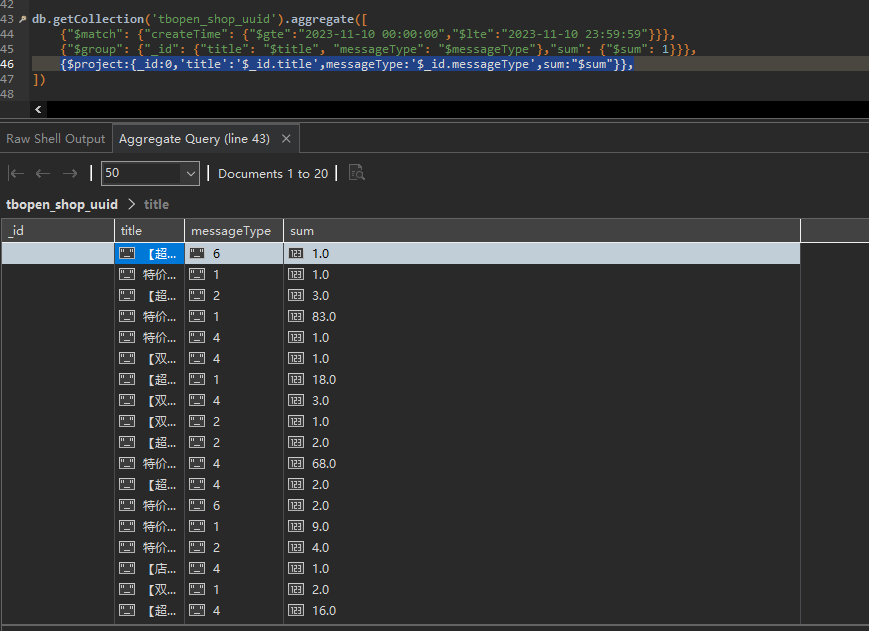
mongo DB -- aggregate分组查询后字段展示
一、分组查询 在mongoDB中可以使用aggregate中的$group操作对集合中的文档进行分组,但是查询后的数据不显示其他字段,只显示分组字段 aggregate进行分组示例 db.collection.aggregate([{$group: {_id: "$field"}},]) 查询后显示 展开只显示两个字段 二、显示所有字段 2.1 $firs
【SparkAPI JAVA版】JavaPairRDD——aggregate(一)
JavaPairRDD的aggregate方法讲解 官方文档说明 /*** Aggregate the elements of each partition, and then the results for all the partitions, using* given combine functions and a neutral "zero value". This function

大数据Flink(一百零三):SQL 表值聚合函数(Table Aggregate Function)
文章目录 SQL 表值聚合函数(Table Aggregate Function) SQL 表值聚合函数(Table Aggregate Function) Python UDTAF,即 Python TableAggregateFunction。Python UDTAF 用来针对一组数据进行聚合运算,比如同一个 window 下的多条数据、或者同一个 key 下的多条数据等,与
大数据Flink(一百零三):SQL 表值聚合函数(Table Aggregate Function)
文章目录 SQL 表值聚合函数(Table Aggregate Function) SQL 表值聚合函数(Table Aggregate Function) Python UDTAF,即 Python TableAggregateFunction。Python UDTAF 用来针对一组数据进行聚合运算,比如同一个 window 下的多条数据、或者同一个 key 下的多条数据等,与