本文主要是介绍MongoDB 中的关联查询MongoDB : aggregate/lookup 对比 Mongoose : ref / populate,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘自 :
MongoDB 中的关联查询
mongoosejs : Populate 官方文档
mongodb : lookup 官方文档
一、前言
数据库设计中数据之间的关联关系是极其常见的:一对一、一对多、多对多,作为
NoSQL领头羊的MongoDB中常用做法无非「内嵌」和「引用」两种,
因为 Document 有 16MB 的大小限制[1]且「内嵌」不适合复杂的多对多关系,「引用」是用得更广泛的关联方式,
所以 MongoDB 官方称其为“Normalized Data Models”——标准化数据模型。

引用式的关联其实很简单,指文档与文档之间通过_id字段的引用来进行关联。
在需要 user 集合中“123xyz”的所有信息时只需要再多查两个表就可以得到。
而本文要阐述的重点就在于如何去多查这两个表——aggregate 与 populate。
二、剖析
1、aggregate + lookup
先来说说 aggregate 吧,为什么要先说它呢?
因为人家是 MongoDB 提供的功能——正儿八经血统纯正官方推荐啊🌚,
而且不得不提的是 aggregate 也是我刚开始接触 Node.js + MongoDB 就误打误撞使用到的业务核心技术,
使用其编写了不少现在正在和公司大佬一起重构的接口🤪……这个问题下文会讲到。
aggregate 聚合其实是 MongoDB 提供的比较大的功能模块了,
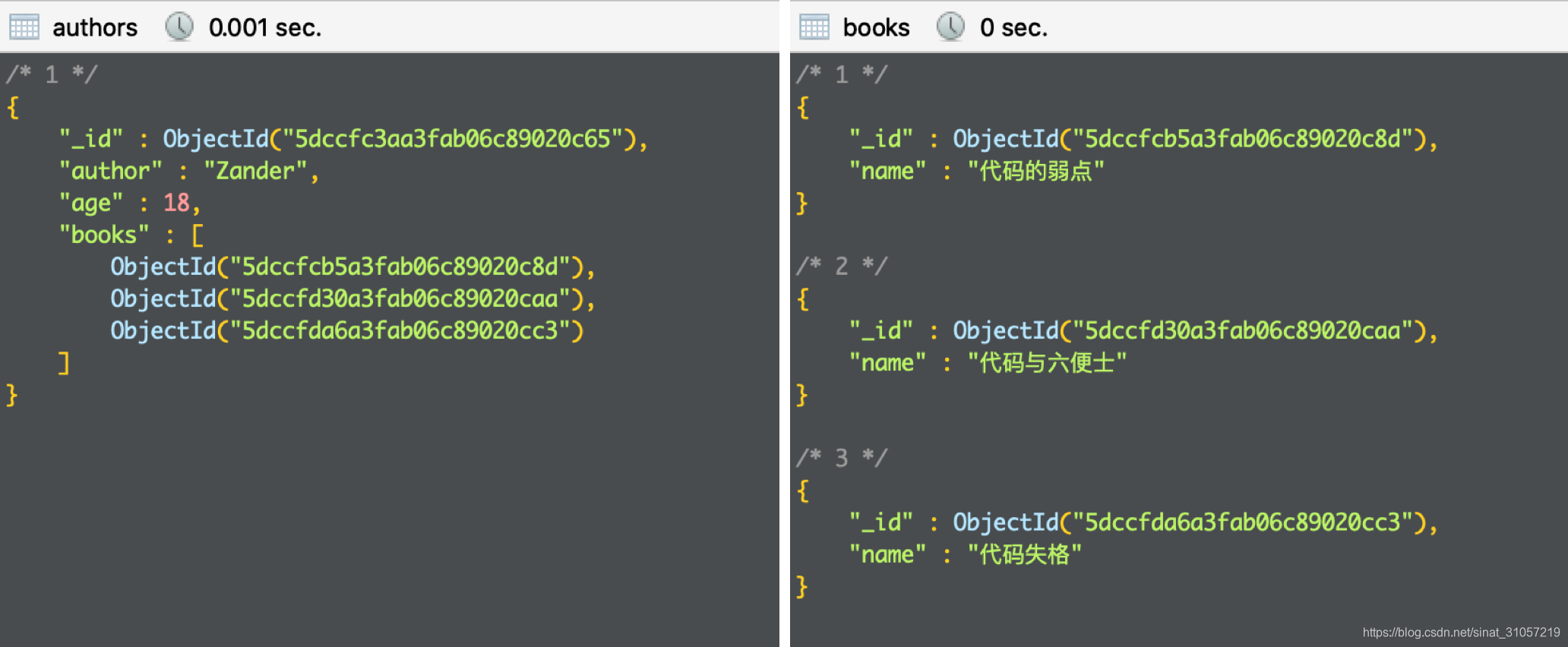
而关联多个集合需要用到的是$lookup,比如有作者集合 authors 和著作集合 books,作者与著作即为「一对多」的关联关系,使用引用式关联:
因为技术栈是 Node.js + Express + Mongoose,以下代码示例也以此为基础,使用 express-generator 生成 demo 目录结构。
使用 aggregate 实现聚合查询作者 Zander 的基本信息及其所有著作信息:
router.get('/getAuthorInfo_a', async (req, res) => {let result = await Author.aggregate([{ // 操作的Model为Author$lookup: {from: "books", // 数据库中关联的集合名localField: "books", // author文档中关联的字段foreignField: "_id", // book文档中关联的字段as: "bookList" // 返回数据的字段名}}, {$match: { // 筛选条件"author": "Zander"}}]);res.json({status: 200,result: result})
});返回数据:
{"status": 200,"result": [{"_id": "5dccfc3aa3fab06c89020c65","author": "Zander","age": 18,"bookList": [{"_id": "5dccfcb5a3fab06c89020c8d","name": "代码的弱点"},{"_id": "5dccfd30a3fab06c89020caa","name": "代码与六便士"},{"_id": "5dccfda6a3fab06c89020cc3","name": "代码失格"}]}]
}aggregate 使用方法并不难,抛开结果先不谈,来看看 populate 的实现方式。
2、populate + ref
populate 是 Mongoose 中提供的方法,且 Mongoose单方言之populate()比 MongoDB 的$lookup更为强大🧐。那就拉出来溜溜呗🐎
首先,Mongoose 的一切始于 Schema[3],使用 populate 的重点也在于 Schema 中的设置:
const mongoose = require('mongoose');
const Schema = mongoose.Schema;
const authorSchema = new Schema({"author": String,"age": Number,"books": [{type: Schema.Types.ObjectId,ref: 'Book' // 关联的Model}]
});
module.exports = mongoose.model("Author", authorSchema, "authors");
// 分别为Model名、Schema、数据库中集合名在接口中使用populate():
router.get('/getAuthorInfo_p', async (req, res) => {let result = await Author.find({"author": "Zander"}).populate("books");res.json({status: 200,result: result})
})返回数据:
{"status": 200,"result": [{"books": [{"_id": "5dccfcb5a3fab06c89020c8d","name": "代码的弱点"},{"_id": "5dccfd30a3fab06c89020caa","name": "代码与六便士"},{"_id": "5dccfda6a3fab06c89020cc3","name": "代码失格"}],"_id": "5dccfc3aa3fab06c89020c65","author": "Zander","age": 18}]
}三、对比
- 灵活性
现在可以观察到的就是 aggregate 灵活的点在于可以更改关联查询后返回数据的 key(返回数据中的bookList),而 populate 返回数据的 key 只能是原来的字段名(返回数据中的books)。
值得一提的是 aggregate 更擅长在聚合管道中对数据进行二次处理,比如$unwind拆分、$group分组等等。
- 功能性
正向关联的话两者都能用,反向关联的话只能用lookup(但个人觉得正向的话还都是用populate,因为lookup写法较麻烦)
此外,还有一种情况:依旧是上面的数据,如果要根据著作 name 找到著作信息和作者信息,使用 aggregate 的$lookup只需要这样就做到了😏:
$lookup: {from: "authors",localField: "_id",foreignField: "books",as: "author"
}然而 populate:“我太难了!”
是的,它做不到这种使用_id实现的反向关联查询,通俗点讲,Mongoose 不允许你这样写:
const bookSchma = new Schema({"_id": { // 不能这样写🙅♂️type: Schema.Types.ObjectId,ref: 'Author'},"name": String
});如果你执意要尝试,那么这是你的下场🙃:
{"status": 200,"result": [{"_id": null,"name": "代码的弱点"}]
}populate 是将一个集合的_id和另一个集合的非_id字段进行关联的,但是 Mongoose 4.5.0版本以后提供了与 aggregate 功能写法都非常类似的virtual()方法,这里不做详述了,有这个需求我用 aggregate 它不香么?🤨
- 代码简洁度
大概知道了它们的使用方法和适用场景后再来看看其它方面,比如为什么要重构之前完成的 aggregate 接口🥶。刚入职经验不足拿来别人的代码就依葫芦画瓢,画出来的「瓢」是这样的:

一方面是大量的回调函数,一方面是 aggregate 繁杂的写法,导致代码大量冗余,可读性也极差,现在重构后优雅的「葫芦」:

- 性能方面
看完了外表再说说内在——查询性能,populate 实际是DBRef[4]的引用方式,相当于多构造了一层查询。比如有10条数据,在find()查询到了主集合内的10条数据后会再进行populate()引用的额外10条数据的查询,性能也相对的大打折扣了。这里有位大佬对aggregate()和find()进行了性能上的对比,结论也显而易见——比 find 查询速度都快的 aggregate 比关联查询的 find + populate 定是有过之而无不及了。
四、总结

综合来看,aggregate 在多集合关联查询和对查询数据的二次处理方面更优,而 populate 更适合简单的正向关联关系且其形成的代码样式较优雅,可读性高而易于维护,性能方面的考究对日常开发中的普通应用来说则大可忽略不计。
技术的使用无不建立在需求和场景之上,不抱令守律,不因噎废食,知变通,知择优,毕竟技术只是工具,目的才是关键。
这篇关于MongoDB 中的关联查询MongoDB : aggregate/lookup 对比 Mongoose : ref / populate的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






