本文主要是介绍StarRocks must be an aggregate expression or appear in GROUP BY clause,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
StarRocks在SQL查询时报错must be an aggregate expression or appear in GROUP BY clause
这个报错信息主要就是select查询的列没有使用聚合函数或者没有包含在GROUP BY中
例如
select c1, c2 from table group by c1;
c2这一列没有使用聚合函数,也不在group by子句中
解决方案
改写SQL语句。如改成select c1 from table group by c1; 或者select c1,max(c2) as c2 from table group by c1;
升级starrock版本至2.3及以上。官方在starrock2.3版本开始支持通过设置sql_mode参数来关闭查询列必须是聚合列的限制(和mysql的设置方式一致)官方issue:https://github.com/StarRocks/starrocks/issues/5578
亲测在starrock2.4版本可以正常关闭;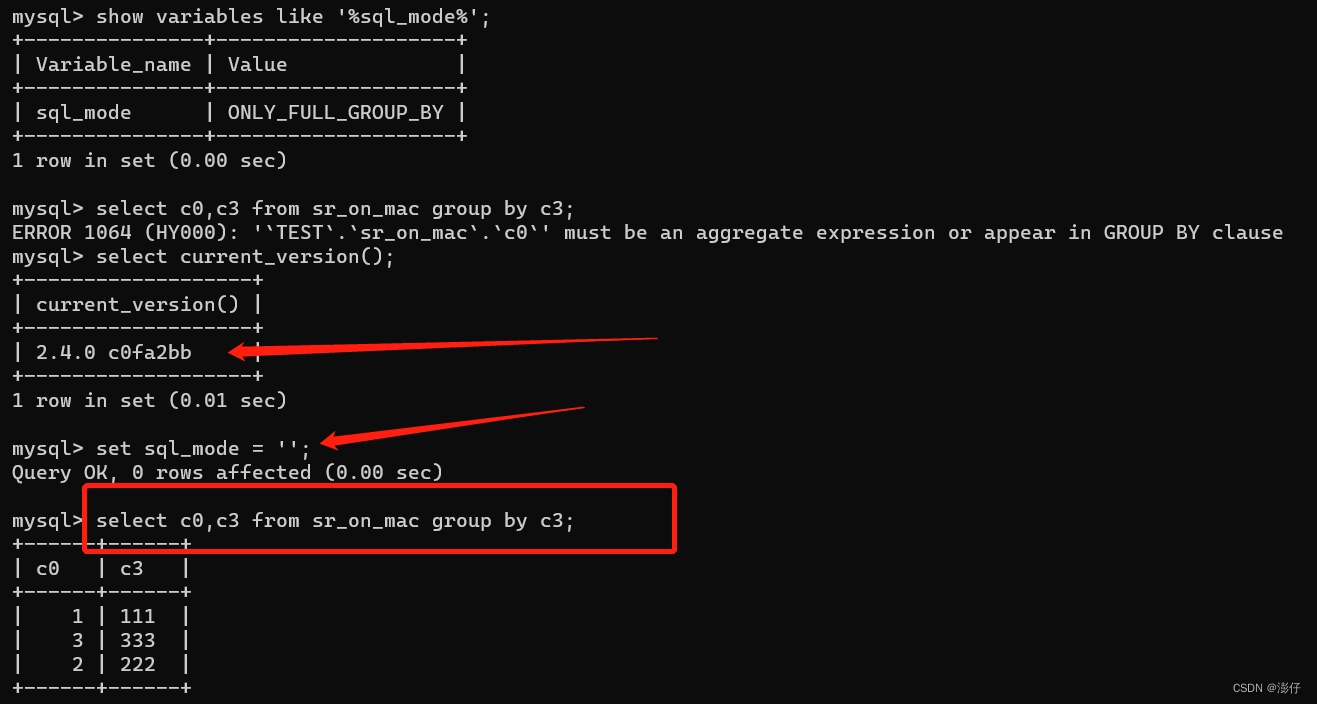
这篇关于StarRocks must be an aggregate expression or appear in GROUP BY clause的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!