group专题

mysql中的group by高级用法详解
《mysql中的groupby高级用法详解》MySQL中的GROUPBY是数据聚合分析的核心功能,主要用于将结果集按指定列分组,并结合聚合函数进行统计计算,本文给大家介绍mysql中的groupby... 目录一、基本语法与核心功能二、基础用法示例1. 单列分组统计2. 多列组合分组3. 与WHERE结合使

mysql中的group by高级用法
《mysql中的groupby高级用法》MySQL中的GROUPBY是数据聚合分析的核心功能,主要用于将结果集按指定列分组,并结合聚合函数进行统计计算,下面给大家介绍mysql中的groupby用法... 目录一、基本语法与核心功能二、基础用法示例1. 单列分组统计2. 多列组合分组3. 与WHERE结合使

MySQL报错sql_mode=only_full_group_by的问题解决
《MySQL报错sql_mode=only_full_group_by的问题解决》本文主要介绍了MySQL报错sql_mode=only_full_group_by的问题解决,文中通过示例代码介绍的非... 目录报错信息DataGrip 报错还原Navicat 报错还原报错原因解决方案查看当前 sql mo

matlab读取NC文件(含group)
matlab读取NC文件(含group): NC文件数据结构: 代码: % 打开 NetCDF 文件filename = 'your_file.nc'; % 替换为你的文件名% 使用 netcdf.open 函数打开文件ncid = netcdf.open(filename, 'NC_NOWRITE');% 查看文件中的组% 假设我们想读取名为 "group1" 的组groupName
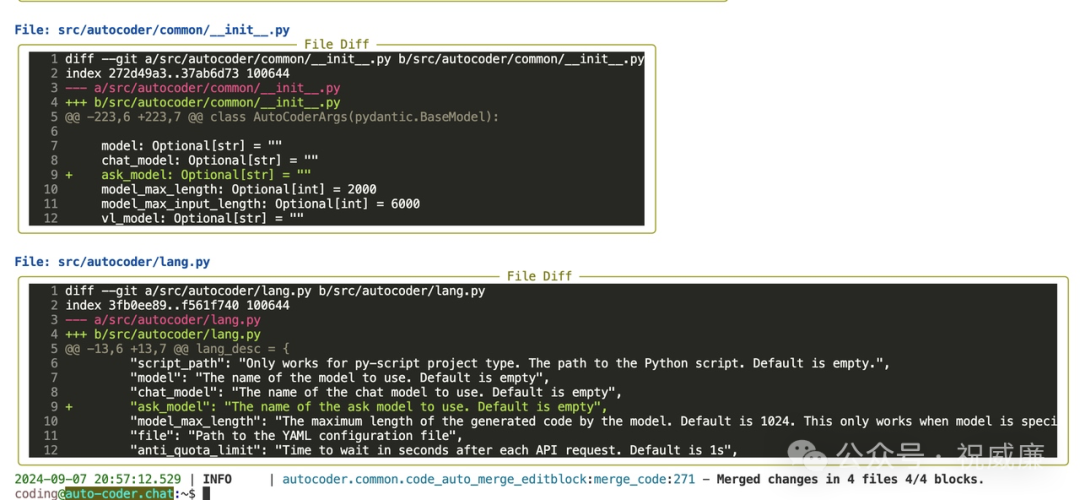
AI辅助编程里的 Atom Group 的概念和使用
背景 在我们实际的开发当中,一个需求往往会涉及到多个文件修改,而需求也往往有相似性。 举个例子,我经常需要在 auto-coder中需要添加命令行参数,通常是这样的: /coding 添加一个新的命令行参数 --chat_model 默认值为空 实际上这个需求涉及到以下文件列表: /Users/allwefantasy/projects/auto-coder/src/autocoder/auto

group by 新体会
group by 分组语句中的 select 后面查询的东西,只能是 group by 中的字段或聚合函数,如果含有group by 中的没有的字段,sql 会报错。 表users 例子: 1.select count(1),sex from users group by sex; sql执行正确 2.select count(id),sex from users gr

【Mysql】系统服务启动访问报错问题处理:this is incompatible with sql_mode=only_full_group_by
一、背景: 本来已经正常运行的平台,突然有一天由于对服务器进行部分操作迁移,发现jar可以正常启动,但是访问功能一直报错,监控后台日志后,发现了问题: 报错的具体信息如下: Caused by: java.sql.SQLSyntaxErrorException: Expression #1 of SELECT list is not in GROUP BY clause and conta
group by和order by
order by 是按字段排序 (排序查询asc升序desc降序) group by 是按字段分类 (分组查询having只能用于group by子句,作用于组内,having条件子句可以直接跟函数表达式) order by 从英文里理解就是行的排序方式,默认的为升序。 order by 后面必须列出排序的字段名,可以是多个字段名。

docker 启动 wurstmeister/zookeeper出错:be owned by root and not group or world-writable docker zookeep
总有一些意想不到的问题,别的环境都好好的,这个环境就是不行,启动脚本 docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper 发现 zookeeper启动后直接退出。查看日志 >> docker logs zookeeper>> /var/run/sshd must be owned by root and
SQL 支持使用 GROUP BY多个列
SQL 语言支持使用 GROUP BY 子句对多个列进行分组。当你对多个列进行分组时,SQL 会根据这些列的组合值来分组数据。这意味着只有当所有指定的列在多行中具有相同的值时,这些行才会被分组在一起。 语法 SELECT column1, column2, AGGREGATE_FUNCTION(column3) FROM table_name GROUP BY column1, column2
谈谈分组:sql的group by+聚集函数 和 python的groupby+agg
直接举例子+分析例子+总结来说,我先给几个表: 学生表:student(学号,姓名,年龄,院系); 课程表:course(课程号,课程名,学分); 学生选课表:sc(学号,课程号,分数); 啥时候用分组呢? 我由简至深来谈。 1、比如让我们查询各个课程号及相应的选课人数。 首先定位到sc表上,“各个”很明显就是要按课程分组,group by出场了,分组后对每组去统计选课人数,聚集函数出场了。

OceanBase 关于 place_group_by HINT的使用
PLACE_GROUP_BY Hint 表示在多表关联时,如果满足单表查询后直接进行group by 的情形下,在跟其它表进行关联统计,减少表内部联接。 NO_PLACE_GROUP_BY Hint 表示在多表关联时,在关联后才对结果进行group by。 使用place_group_by 的耗时少于no_place_group_by的耗时,原因可以查看执行计划的COST区别。 直接上图 #不
group by having
Group by与having理解 注意:select 后的字段,必须要么包含在group by中,要么包含在having 后的聚合函数里。 1. GROUP BY 是分组查询, 一般 GROUP BY 是和聚合函数配合使用 group by 有一个原则,就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面(重要) 例如,有如下数据库表: A

Linux创建sysfs属性节点 - DEVICE_ATTR宏、device_create_file()、sysfs_create_group()
目录 简介: 一、DEVICE_ATTR介绍 1、DEVICE_ATTR宏 1.1 参数说明 1.2 调用方法 二、sysfs创建属性文件 1、创建一个sysfs属性文件 1.1 device_create_file()函数 1.2 device_create_file()实例 2、创建多个sysfs属性文件 2.1 sysfs_create_group()函数 2

海康二次开发学习笔记12-从Group外部输入图像
从Group外部输入图像 用OpenCV从本地读图 当Group内部无图像源模块时,可以通过代码的方式将图片传入Group内部.实现方式有多种,可以使用OpenCV从本地读图,可在程序集搜索引用OpenCvSharp,同时将其复制本地的属性改为False. 1. 界面设计 增加加载图像按钮 2. 处理加载图像点击事件 private void button5_Click(o
MYSQL5.7版本sql_mode=only_full_group_by问题,重启有效的方法
1./etc/mysql/mysql.conf.d/mysqld.cnf 或者my.cnf 总之就是mysql的配置文件 2.查看当前的sql模式 select @@sql_mode; 3.添加语句 sql_mode ='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CR

【Pytorch】Linear 层,举例:相机参数和Instance Feaure通过Linear层生成Group Weights
背景 看论文看到这个pipeline,对于相机参数和Instance Fature 的融合有点兴趣,研究如下: Linear 层 Linear 层是最基本的神经网络层之一,也称为全连接层。它将输入与每个输出神经元完全连接。每个连接都有一个权重和一个偏置。 示例代码 import torchimport torch.nn as nn# 定义一个简单的全连接网络,包含两个Linear层
MySQL 学习 之 ONLY_FULL_GROUP_BY 解决方案
目录 1. 缘由2. 解决 1. 缘由 当 MySQL 的版本为 5.7+ 时,在执行 group by 时,如果 select 的字段不在 group by 中, 并且 select 的字段未使用聚合函数(SUM、AVG、MAX、MIN 等)的话,就会报错。 mysql> SELECT name, address, MAX(age) FROM t GROUP BY name;
SQL中的DISTINCT和GROUP BY异同
在SQL中,DISTINCT和GROUP BY都是非常重要的关键字,它们各自有着独特的用途和应用场景。尽管两者在一定程度上都可以帮助我们处理重复的数据,但它们的目的、用法以及适用场景都有所不同。下面我们将深入探讨这两个关键字的异同点。 1. 概念理解 1.1 DISTINCT DISTINCT关键字用于从查询结果中去除重复的行,只保留唯一的记录。它通常用于SELECT语句中,紧接在SELEC
Akka-路由模式Group/Pool
为了文章好理解,我们先统一一下概念,在Akka中,Actor是一个高度抽象的概念,Akka的路由器也是一个Actor,所以我们把路由器,叫做路由Actor,接收消息(消费消息)的Actor,在本文中我们叫做消息Actor Akka中有两种路由模式,分别是Group模式和Pool模式,如果我要将消息X通过路由Actor发送到多台机器,那么: Pool: 在多台机器上,每台机器上的消息Actor都是
Linux C/C++ 库链接选项 --whole-archive,--no-whole-archive和--start-group, --end-group
库链接选项 一、介绍whole-archive编译选项Bstatic编译选项start-group 编译选项 示例参考链接 一、介绍 这四个都是链接器的选项,所以在编译的时候要用-Wl,[options]来传递给链接器,不然编译器会不认得这个选项。 在大型工程开发中,工程目录会分的非常细,在modules下会创建很多模块,每个modules都会编译成.a静态库文件供主
mysql中group by语句使用
mysql中group by语句使用 一、工作原理二、举一个例子 一、工作原理 在MySQL中,GROUP BY语句的工作原理可以分为以下几个步骤: 全表扫描:MySQL首先会扫描整个表,读取所有的行。分组:MySQL会根据GROUP BY语句中指定的列的值,将读取到的行进行分组。如果GROUP BY语句中指定了多个列,那么MySQL会根据这些列的值的组合进行分组。聚合计算:对

【Pytorch】的函数中的group参数的作用
官方的api介绍:https://pytorch.org/docs/stable/nn.html?highlight=nn conv2d#torch.nn.Conv2d Pytorch中nn.Conv2d的用法 nn.Conv2d是二维卷积方法,相对应的还有一维卷积方法nn.Conv1d,常用于文本数据的处理,而nn.Conv2d一般用于二维图像。 先看一下接口定义: class torch.
mongodb聚合中$group的联合主键写法
环境 mongodb 2.6 window7 RoboMongodb 需求 今天写联合主键了时,发现有两种写法,特此记录下: 写法一、用数组 db.gg_report_down_read.aggregate([{$match:{ "status" : 1 , "account_name" : "F00015170" , "org_name" : { "$regex" :

JMeter之插件jp@gc - Stepping Thread Group
文章目录 业务场景核心功能安装教程常规使用 业务场景 在性能测试中,希望jemter能动态设置线程数,并且线程数量能从低到高依次压测接口,比如线程数量从10增加到50,通过设定一定的并发线程数,给定加压规则,遵循“缓起步,快结束”的原则,不断地增加并发用户来找到系统的性能瓶颈,进而有针对性的进行各方面的系统优化。 核心功能 不但递增还可以递减可以设置递增次数递增启动
F - Close Group
子集切割型 递推的dp 链接 有别于旅行商那种子集dp f[s][i]这种。。 子集切割型。。他研究的一般是子集和子集的拼凑。。 有点像 区间dp的递推类似。。把当前子集 分割成小子集+小子集。 #include <bits/stdc++.h>using namespace std;#define int long long#define ll __int128_t#define ar