starrocks专题

StarRocks数据库详解(什么是StarRocks)
《StarRocks数据库详解(什么是StarRocks)》StarRocks是一个高性能的全场景MPP数据库,支持多种数据导入导出方式,包括Spark、Flink、Hadoop等,它采用分布式架构,... 目录StarRocks介绍什么是StarRocks?StarRocks适合什么场景?StarRock

StarRocks索引详解(最新整理)
《StarRocks索引详解(最新整理)》StarRocks支持多种索引类型,包括主键索引、前缀索引、Bitmap索引和Bloomfilter索引,这些索引类型适用于不同场景,如唯一性约束、减少索引空... 目录1. 主键索引(Primary Key Index)2. 前缀索引(Prefix Index /
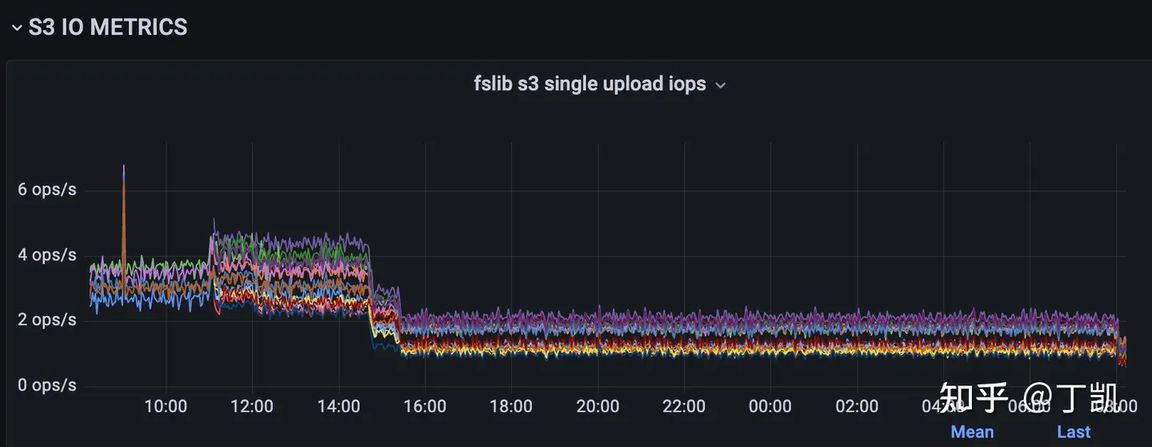
StarRocks 存算分离成本优化最佳实践
序言 StarRocks 存算分离借助对象存储来实现计算和存储能力分离,而存算分离版本 StarRocks 一般来说有以下三方面成本: 计算成本,也即机器使用成本,尤其是运行在公有云上时存储成本,该部分与对象存储上存储的数据量相关API 访问成本,这部分与访问对象存储各种 API 的频率相关 优化数据导入模式 在存算分离中,我们推荐积攒更大批量的数据,使用低频大批量写入来代替高频微批写

StarRocks 巧用 Storage Volume,强大又便捷
前言 StarRocks 存算分离支持使用各种外部独立存储系统来存储业务数据。在早期 3.0 版本中,用户需要在 fe.conf 中配置存储相关信息(如 endpoint 等),这种静态配置模式也给用户使用带来了很多的不便性。 为此,StarRocks 存算分离从 3.1.0 版本后推出了 Storage Volume 能力,支持用户动态地为集群创建存储资源。需要说明的是,Storage Vo
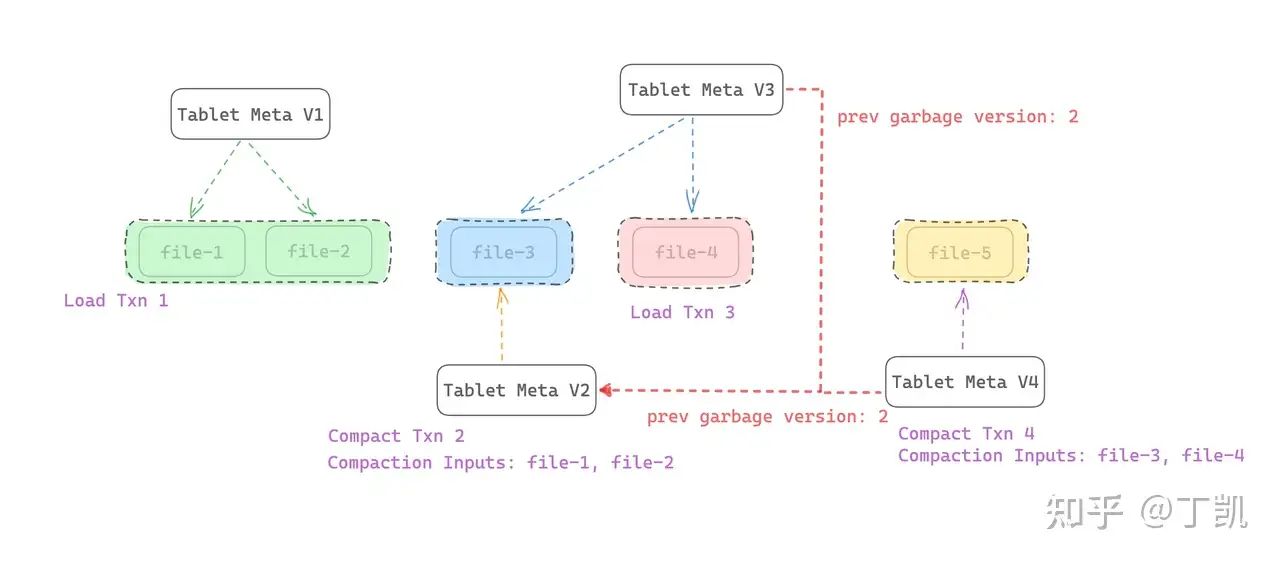
StarRocks 存算分离数据回收原理
前言 StarRocks存算分离表中,垃圾回收是为了删除那些无用的历史版本数据,从而节约存储空间。考虑到对象存储按照存储容量收费,因此,节约存储空间对于降本增效尤为必要。 在系统运行过程中,有以下几种情况可能会需要删除对象存储上的数据: 用户手动执行了删除库、表、分区等命令,如执行了 drop table、drop database 以及 drop partition 等命令随着系统内 Co
StarRocks分区表历史数据删除与管理
一、背景介绍 在使用 StarRocks 时,可能会遇到需要删除大批量数据的情况。然而,StarRocks 对 DELETE 操作的支持并不理想,主要存在以下问题: 不建议执行高频的 DELETE 操作:删除的数据会标记为“Deleted”,暂时保留在 Segment 中,不会立即进行物理删除。Compaction(数据版本合并)完成之后会被回收。查询效率可能降低:执行 DELETE 语句后,
数据仓库之StarRocks
官方文档 简介 Palo,中国的互联网公司百度开发并开源的,后更名为doris。StarRocks是一款由doris的一个分支演化而来的、开源分布式列式存储数据库。旨在提供高性能、高可靠性和低延迟的大数据分析和查询服务。 特点 列式存储 StarRocks使用列式存储引擎,将数据按列存储在磁盘上,以提供更高的查询性能和压缩比。列式存储使得只需要读取和处理查询所需的列数据,从而减少了磁盘和
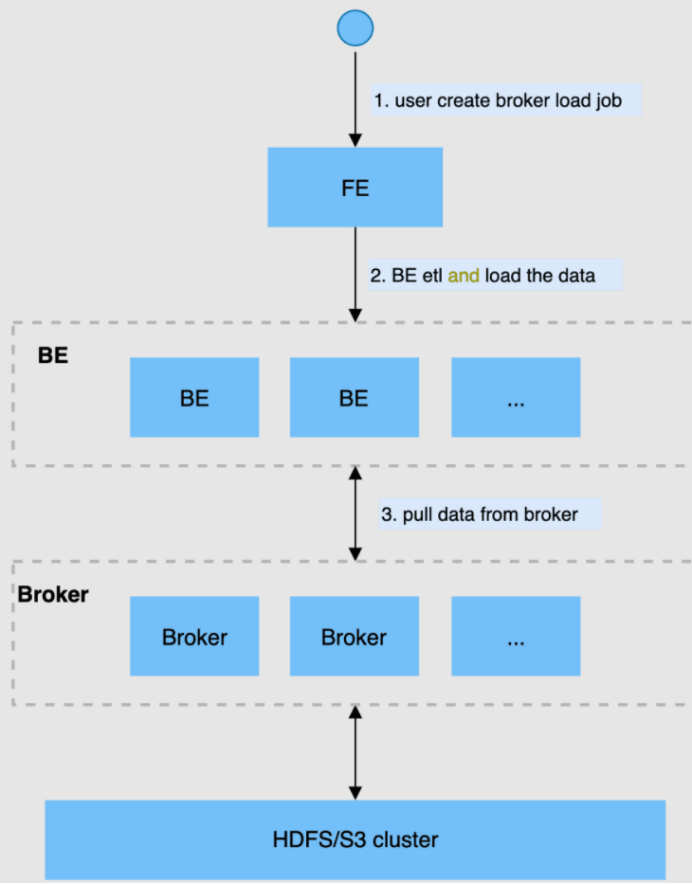
StarRocks 【新一代MPP数据库】
1、StarRocks 1.1、StarRocks 简介 StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing,MPP数据库是一种基于大规模并行处理技术的数据库系统,旨在高效处理大量数据。) 数据库。StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。用户无需经过复杂的预处理,就可以用 StarRocks
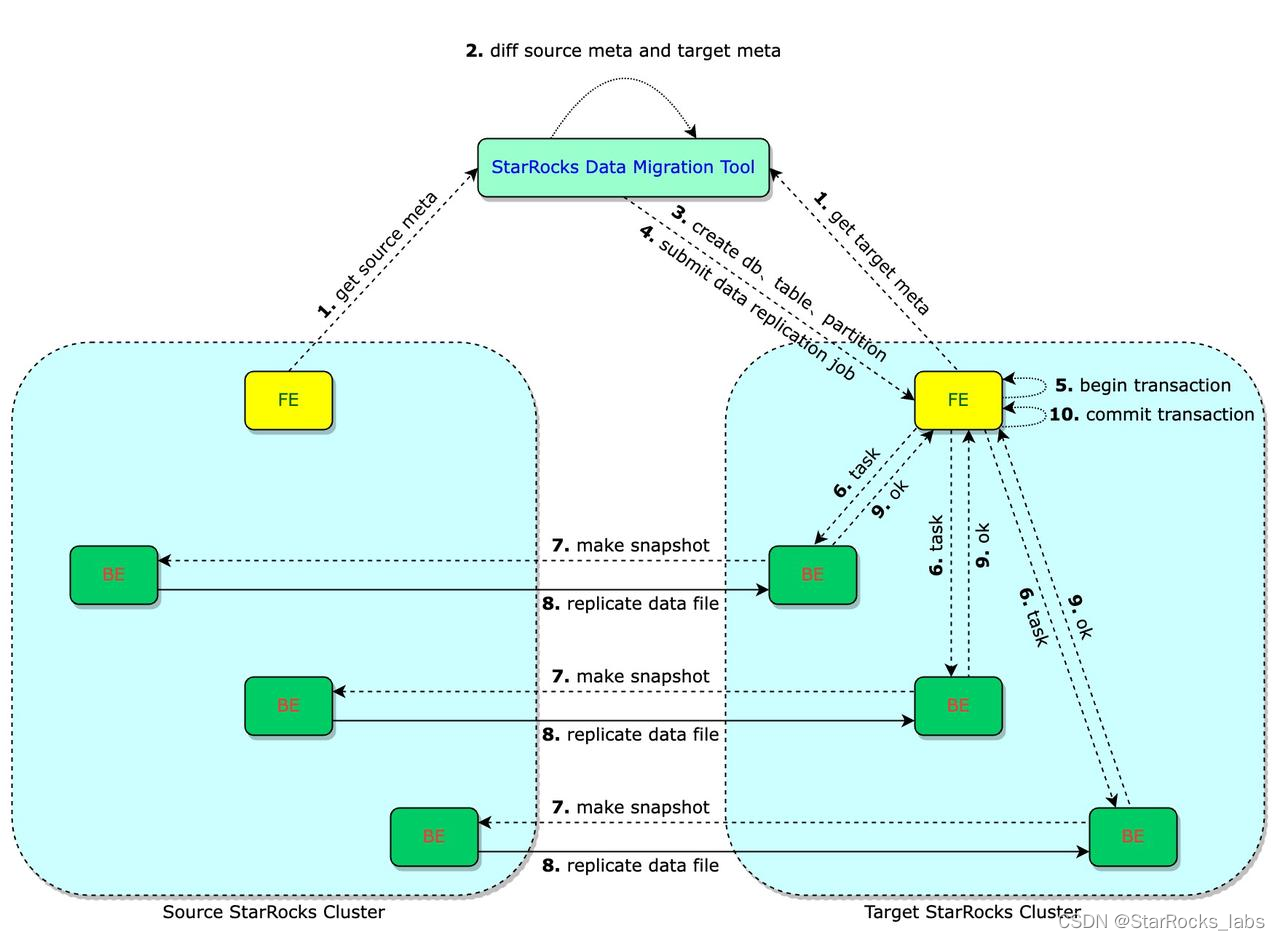
StarRocks 跨集群数据迁移,SDM 帮你一键搞定!
作者:严祥光,StarRocks Active Contributor,StarRocks 存算分离核心研发,在社区中主要负责数据导入、跨集群同步、数据迁移和容灾等工作。 有时候,你可能会为以下需求而苦恼,苦苦搜索更好的解决方案: 情景一: 想象一下,你急需 验证新版本 , 但又不能影响线上已有集群的运行。你需要在不影响现有集群的基础上将数据迁移到新集群以进行验证。 情景二: 听说 S

一篇Starrocks查询加速特性的测试报告
本文的所有测试数据集均采用Starrocks所提供的标准TPC-H数据集测试 测试环境如下: 机器类型:性能保障型X6 机器规格:16C64G (FE 三台 ,CN 三台) 云盘类型:ESSD_PL1 Starrocks配置:存算分离 数据集:TPC-H 100G 数据集 「pipeline_dop和Pipeline_engine 并发度测试」 Pipeline是指的实例查
【StarRocks系列】 Trino 方言支持
我们在之前的文章中,介绍了 Doris 官方提供的两种方言转换工具,分别是 sql convertor 和方言 plugin。StarRocks 目前同样也提供了类似的方言转换功能。本文我们就一起来看一下这个功能的实现与 Doris 相比有何不同。 一、Trino 方言验证 我们可以通过如下 SQL 来验证 Trino 的方言转换在 SR 中的效果: set enable_profile =
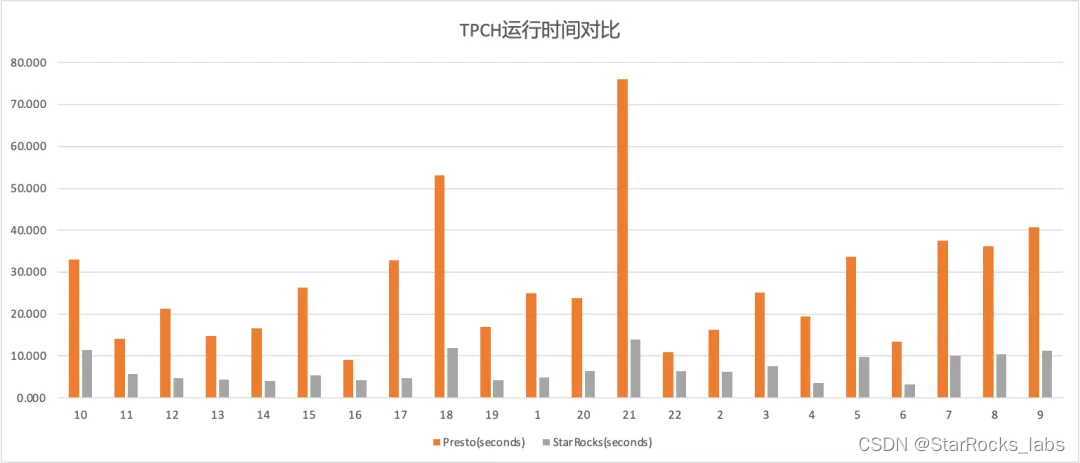
StarRocks x Paimon 构建极速实时湖仓分析架构实践
Paimon 介绍 Apache Paimon 是新一代的湖格式,可以使用 Flink 和 Spark 构建实时 Lakehouse 架构,以进行流式处理和批处理操作。Paimon 创新性地使用 LSM(日志结构合并树)结构,将实时流式更新引入 Lakehouse 架构中。 Paimon 提供以下核心功能: 高效实时更新:高吞吐和低延迟的数据摄入和更新 统一的批处理和流处理:同时支持批量读写
StarRocks 实战指南:100+ 大型企业背后的最佳实践经验
编者荐语: 本文由镜舟科技的 DBA 团队负责人景丹撰写。在过去三年中,他服务了上百家 StarRocks 大型企业用户,并总结了最佳使用方法。文章涵盖了部署、建模、导入、查询和监控五个模块。 PART 01 部署 容量规划 【建议】参考 StarRocks 集群配置推荐 做容量规划 基础环境配置 【必须】参考检查环境配置 | StarRocks,尤其关注 swap 关闭、over
StarRocks用户权限管理
集群安装完毕后,需要设置一下数据用户权限。 StarRocks | StarRocks 设置ROOT用户密码 1. 通过 MySQL 客户端连接到 StarRocks 您需要使用初始用户 root 登录,密码默认为空。 将 <fe_address> 替换为 Leader FE 节点的 IP 地址(priority_networks), 并将 <query_port>(默认:9030)替

StarRocks三节点集群部署
系统:Centos7 X86-64 3台服务器部署3个BE服务和3个FE服务,生产环境建议FE节点部署在单独服务器 服务器 服务 192.168.0.221 BE、FE、jdk、Nginx 192.168.0.222 BE、FE、jdk 192.168.0.223 BE、FE、jdk 1. 配置系统参数 a. 编辑/etc/security/limits.conf 在最
starrocks的fe节点启动不起来的解决办法
fe节点启动报错:Do not specify the helper node to FE itself. Please specify it to the existing running Leader or Follower FE at com.starrocks.StarRocksFE.main(StarRocksFE.java:68) [starrocks-fe.jar:?]Cause

StarRocks实战——华米科技埋点分析平台建设
目录 前言 一、原有方案及其痛点 二、引入StarRocks 三、方案改造 3.1 架构设计 3.2 数据流程 3.3 性能指标 3.4 改造收益 前言 华米科技是一家基于云的健康服务提供商,每天都会有海量的埋点数据,以往基于HBase建设的埋点计算分析项目往往效率上会相对比较低,查询方式不够灵活 。 在埋点分析中,用户往往是基于单维度或者多维度组合
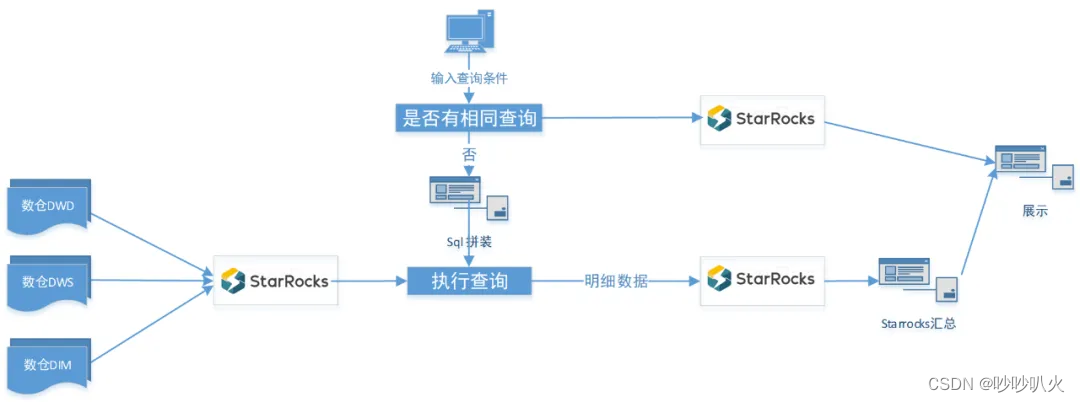
StarRocks实战——携程火车票指标平台建设
目录 前言 一、早期OLAP架构与痛点 二、指标平台重构整体设计 2.1 指标查询过程 2.1.1 明细类子查询 2.1.2 汇总类子查询 2.1.3 “缓存” 2.2 数据同步 三、Starrocks使用经验分享 3.1 建表经验 3.2 数据查询 3.3 函数问题 四、查询性能大幅提升 五、 后续优化方向 原文大佬介绍的这篇火车票指标平台建设有借鉴意义,

StarRocks 面试题及参考答案详解(万字详解)
1. StarRocks 的架构设计是怎样的? 参考答案: StarRocks 的架构设计遵循了现代分布式系统的多个核心原则,以确保高性能和高可靠性。它主要由以下几个组件构成: FE(Frontend):作为前端服务,负责SQL的解析、编译和优化,以及执行计划的生成。BE(Backend):后端服务,负责数据的存储和查询执行。BE节点之间通过Raft协议进行数据同步和容错。Storage:负责
StarRocks部署
介绍 tarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库。StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。用户无需经过复杂的预处理,就可以用 StarRocks 来支持多种数据分析场景的极速分析。 官网 ## 部署https://docs.starrocks.io/zh/docs/deployment
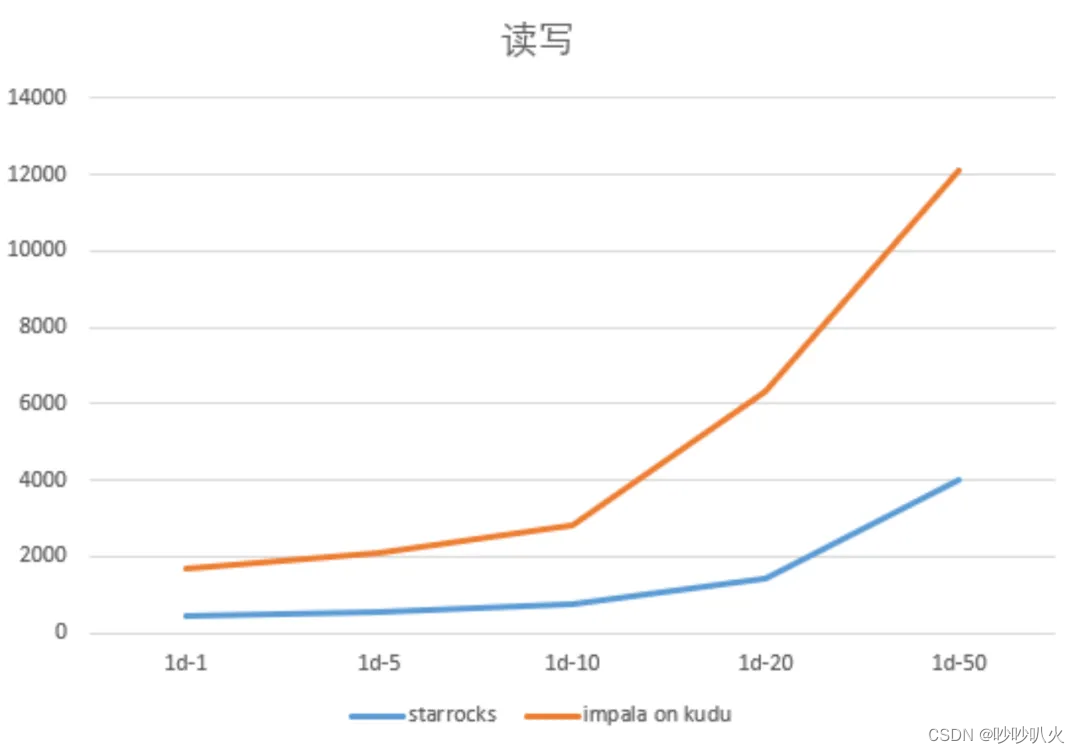
StarRocks实战——多点大数据数仓构建
目录 前言 一、背景介绍 二、原有架构的痛点 2.1 技术成本 2.2 开发成本 2.2.1 离线 T+1 更新的分析场景 2.2.2 实时更新分析场景 2.2.3 固定维度分析场景 2.2.4 运维成本 三、选择StarRocks的原因 3.1 引擎收敛 3.2 “大宽表”模型替换 3.3 简化Lambda架构 3.4 模型持续迭代 3.5 明细、汇总一体化 3.
StarRocks使用过程中遇到的一些问题记录
1,{"status":"FAILED","msg":"There is no 100-continue header"} 增加 Expect:100-continue 参数 curl --location-trusted -u dxt:'******' -T /app/bigdata_app/data/20220517.txt -H "column_separator:^" -H "E
【运维】StarRocks数据迁移到新集群(针对于集群互通、不互通的情况)
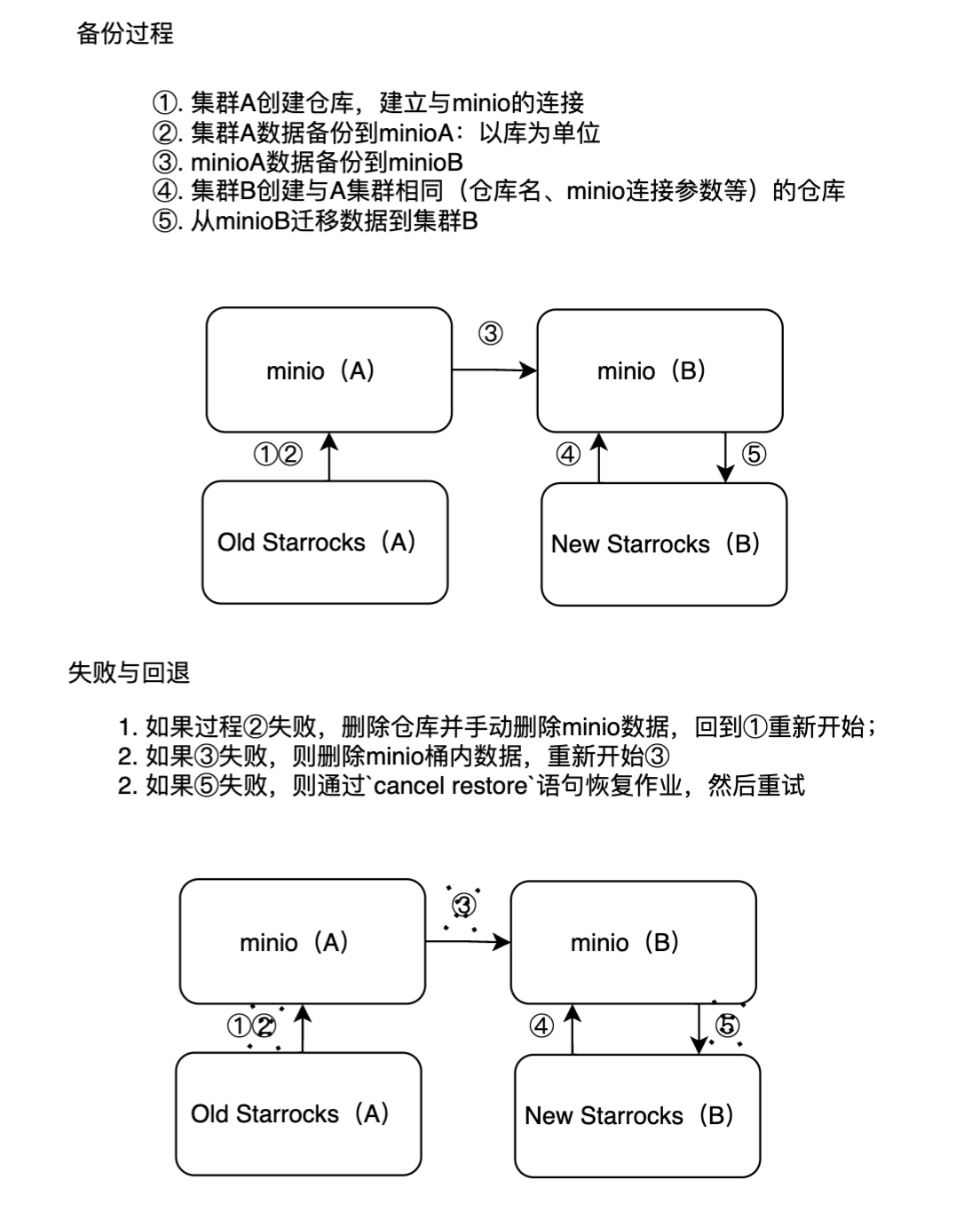
文章目录 一. 迁移整体思路1. 对于新旧集群互通的情况2. 对于新旧集群不互通的情况 二、迁移过程(两个集群互通的情况)1. 备份过程1.1. 通过mysqlclient与starrocks进行关联1.2. 创建仓库与minio建立联系1.3. 备份数据到minio 2. 迁移过程2.1. 通过mysqlclient与starrocks进行关联2.2. 在新集群中创建仓库2.3. 恢复数据
StarRocks面试题及答案整理,最新面试题
StarRocks 的 MV(物化视图)机制是如何工作的? StarRocks 的物化视图(MV)机制通过预先计算和存储数据的聚合结果或者转换结果来提高查询性能。其工作原理如下: 1、数据预处理: 在创建物化视图时,StarRocks 会对指定的表进行数据聚合或转换操作,然后将结果存储在物化视图中。这个过程类似于创建一个索引,但它是针对数据的聚合结果而非原始数据。 2、查询改写: 当用户查询
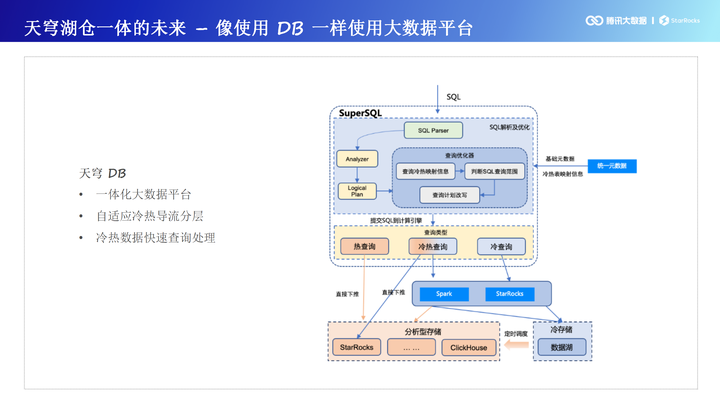
腾讯天穹 StarRocks 一站式湖仓融合平台架构揭秘
作者:腾讯大数据 高级工程师 陈九天 小编导读: 腾讯天穹是协同腾讯内各 BG 大数据能力而生的 Oteam,作为腾讯大数据领域的代名词,旨在拉通大数据各个技术组件,打造一个具有统一技术栈的公司级大数据平台体系。从底层数据接入、数据存储、资源管理、计算引擎、作业调度,到上层数据治理及数据应用等多个环节,支持腾讯内部近 EB 级数据的存储和计算,为业务提供海量、高效、稳定的大数据平台支撑和
StarRocks——滴滴的极速多维分析实践
背景 滴滴集团作为生活服务领域的头部企业,其中橙心优选经过一年多的数据体系建设,逐渐将一部分需要实时交互查询,即席查询的多维数据分析需求由ClickHouse迁移到了StarRocks中,接下来以StarRocks实现的漏斗分析为例介绍StarRocks在橙心优选运营数据分析应用中的实践。 一、需求介绍 当前数据门户上的漏斗分析看板分散,每个看板通常只能支持一个场景的漏斗分析,