本文主要是介绍StarRocks实战——华米科技埋点分析平台建设,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
一、原有方案及其痛点
二、引入StarRocks
三、方案改造
3.1 架构设计
3.2 数据流程
3.3 性能指标
3.4 改造收益
前言
华米科技是一家基于云的健康服务提供商,每天都会有海量的埋点数据,以往基于HBase建设的埋点计算分析项目往往效率上会相对比较低,查询方式不够灵活 。
在埋点分析中,用户往往是基于单维度或者多维度组合去观测某个指标,这里的维度可以是时间,事件名称,城市或者设备属性等,指标可以是用户量、某个埋点的次数等。在此海量埋点数据背景下,如何比较灵活,高效的完成维度+指标的计算,满足用户快速查询分析的需求,是一个值得探索的问题。基于高效的OLAP引擎建设埋点分析平台就成为了业务发展中的重要一环。
一、原有方案及其痛点
在之前的架构中,华米科技的埋点数据统计相关信息,需要根据统计的指标,优先将需要计算的指标(例如PV、UV)通过Spark /Hive进行预计算操作,然后写入到HBase中,对下游相关用户提供点查的能力。

对于该方案,以下三点是较为不便的:
- 在HBase中,数据以KV形式存储,只能提供点查能力,不具备复杂的统计分析能力;
- 无法使用Bitmap 相关技术,将需要的指标事先计算出来,方式不够灵活,不能做集合操作;
- 流程链路较长,维护复杂度高,不具备模型抽象能力,业务升级有所不便。
二、引入StarRocks
针对数据存储层的问题,着力于寻找一款高性能、简单易维护的数据库产品来替换已有的 Spark + HBase 架构,同时也希望在业务层上能突破HBase点查的限制,通过实时多表关联的方式拓展业务层的需求。
目前市面上的 OLAP 数据库产品很多,诸如 Impala、Druid、ClickHouse 及 StarRocks。在经过一系列的对比之后,选择了 StarRocks 来作为 华米的 OLAP 引擎,替换原有的HBase成为存储层的新选择。
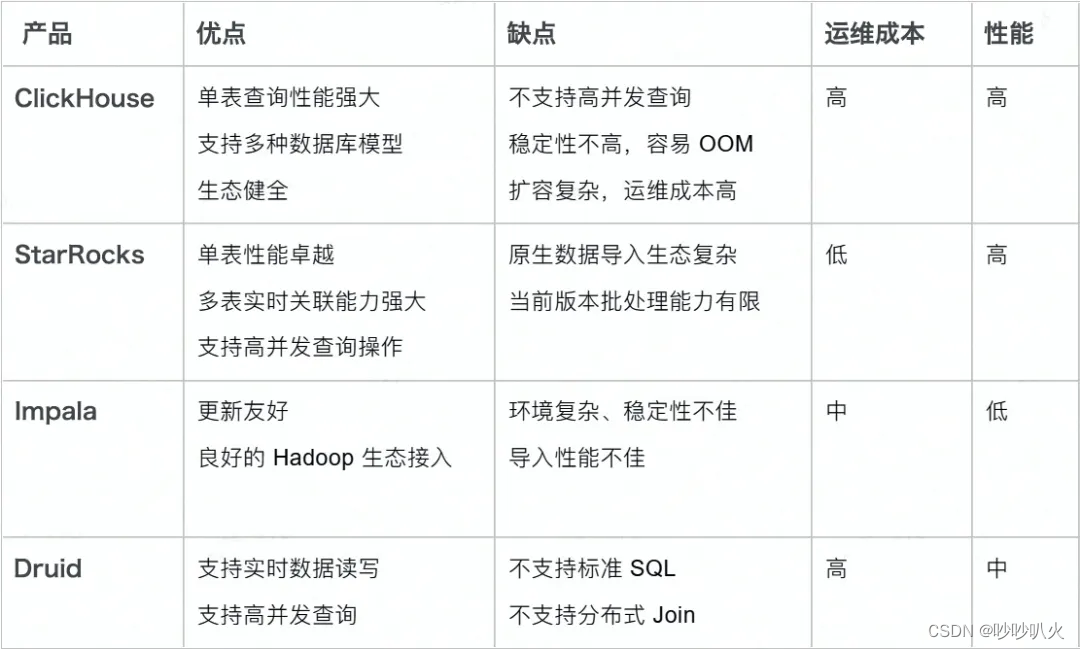
从上面的对比可以看出,StarRocks是一款极速全场景 MPP企业级数据库产品,具备水平在线扩缩容,兼容Mysql协议和Mysql生态,提供全面向量化引擎与多种数据源联邦查询等重要特性,在全场景OLAP业务上提供统一的解决方案,适用于对性能,实时性,并发能力和灵活性有较高要求的各类应用场景。
三、方案改造
3.1 架构设计
当前埋点数据经由网关转入kafka,采用Hudi on Flink 的模式进行数据清洗,过滤,转换,基于流式数据湖构建OLAP的预处理层。根据数据特性和写入的性能要求以及成本的权衡,分别基于Hudi 的 Upsert 和 Append 模式构建 DWD 层(借助 Hudi 的去重、追加能力),定时离线处理数据转入DWS,考虑数仓的整体架构以及成本优化,将DWS数据定时离线导入到StarRocks中,最后经由统一的查询分析平台查询StarRocks数据。

3.2 数据流程
详细流程如下:
(1)对原始数据进行数据转换处理,然后根据数据特性,分别以Upsert 模式和Append模式接入Hudi(对数据重复不敏感的业务数据直接以Append 模式高效写入Hudi)
(2)将产出的数据经由 Broker Load 写入带有Btimap字段的聚合模型,生成业务Btimap数据;
(3)根据业务需求,自定义对Btimap进行集合操作(当前的应用场景为生成PV,UV等数据);
(4)用户根据查询分析平台进行自助业务指标查询;

3.3 性能指标
通过StarRocks的监控平台可以看到查询的平均耗时在100ms左右,P99延迟大概在250ms 左右,能够很好地满足埋点数据分析平台业务上的需求。

3.4 改造收益
- 高效:能够快速响应用户的查询分析需求,很多大查询效率从分钟级别降低至秒级。
- 灵活:满足多维度、多时间段自由组合的指标统计分析,不需要提前计算冗余统计指标。
- 节约空间:StarRocks 自身的高效存储结构,同等业务量的数据存储成本较以往下降20%;
- 简单:相较于 ClickHouse,维护管理所需的人力成本有所降低。
- 便捷:用户自助查询便捷,取数体验有所提升,部分指标点查速度从之前的分钟级降低到秒级,部分指标可以达到毫秒级。
参考文章:
https://mp.weixin.qq.com/s/ci9iRMz4FvqcXs5FtBSxKg
这篇关于StarRocks实战——华米科技埋点分析平台建设的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




