本文主要是介绍【运维】StarRocks数据迁移到新集群(针对于集群互通、不互通的情况),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一. 迁移整体思路
- 1. 对于新旧集群互通的情况
- 2. 对于新旧集群不互通的情况
- 二、迁移过程(两个集群互通的情况)
- 1. 备份过程
- 1.1. 通过mysqlclient与starrocks进行关联
- 1.2. 创建仓库与minio建立联系
- 1.3. 备份数据到minio
- 2. 迁移过程
- 2.1. 通过mysqlclient与starrocks进行关联
- 2.2. 在新集群中创建仓库
- 2.3. 恢复数据到新集群
- 二、迁移过程(两个集群不互通的情况)
- 1. 集群A数据迁移到minioA
- 1.1. 通过mysqlclient与starrocks进行关联
- 1.2. 创建仓库与minioA建立联系
- 1.3. 备份数据到minioA
- 2. minioA数据迁移到minioB
- 2.1. 下载minioA中的文件到本地
- 2.2. 将文件上传到minioB
- 3.minioB数据迁移到集群B
- 3.1. 通过mysqlclient与starrocks进行关联
- 3.2. 在新集群中创建仓库
- 3.3. 恢复数据到新集群
一. 迁移整体思路
SR官网提供了分区、表和数据库级别的数据迁移策略,此方案通过数据库级别将数据迁移到新集群。
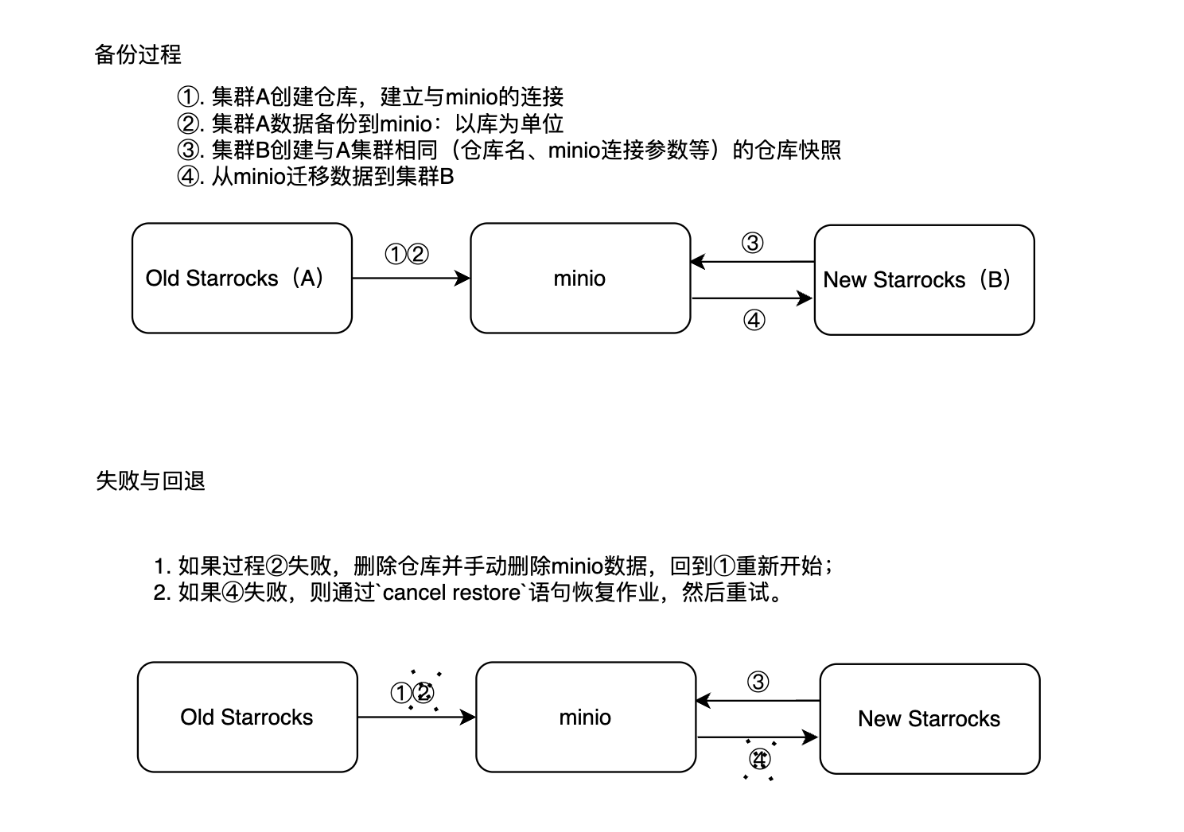
1. 对于新旧集群互通的情况
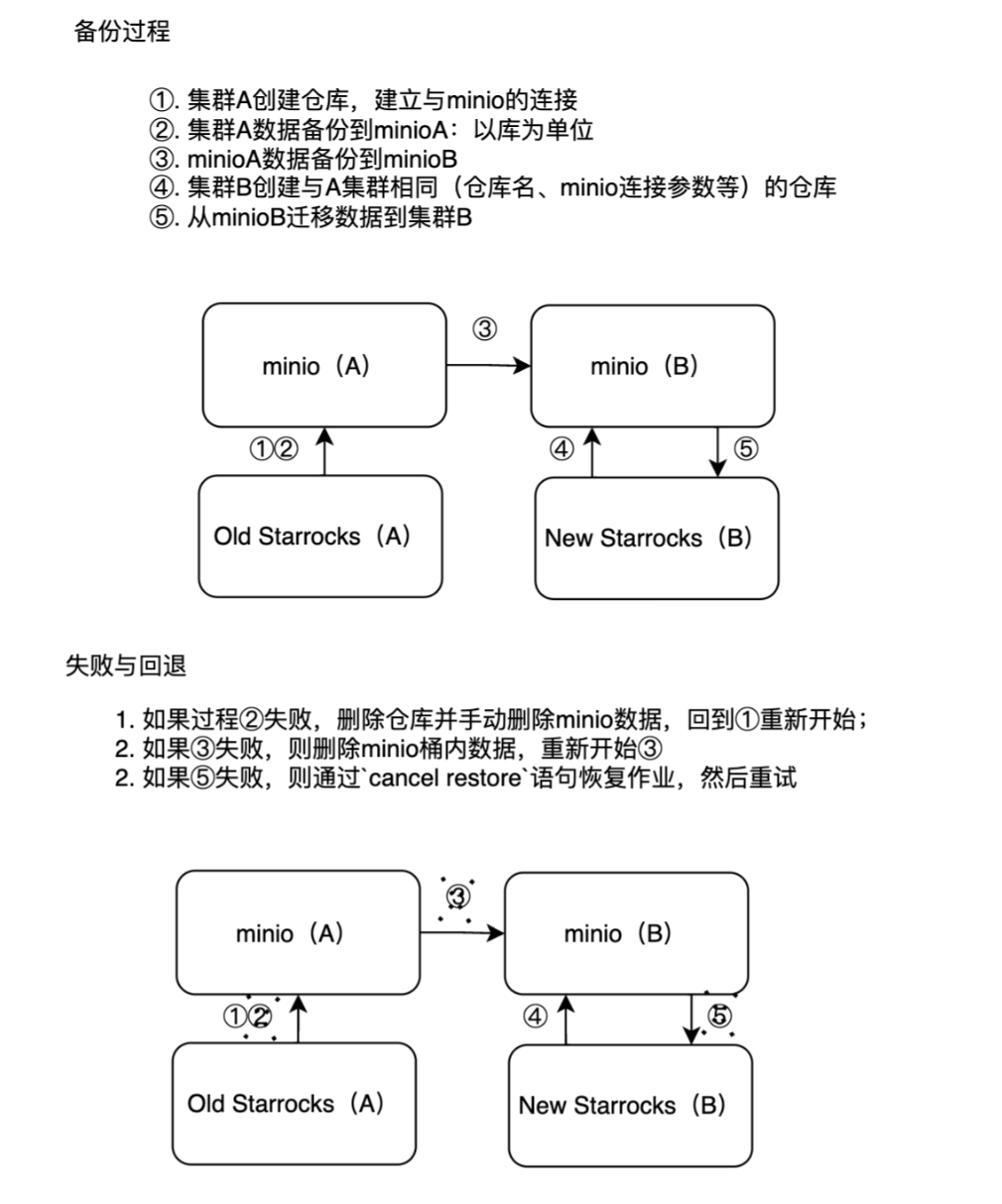
2. 对于新旧集群不互通的情况
二、迁移过程(两个集群互通的情况)
准备
规划
| 序号 | 组件 | 说明 |
|---|---|---|
| 1 | minio | 用于创建桶,将库备份放到minio的桶中 |
| 2 | 集群A | 旧集群,用于将库迁移到minio中 |
| 3 | 集群B | 新集群,从minio迁移数据到集群B |
minio操作
# 1. 创建minio集群别名:用于后续操作;在任意minio节点
语法
/usr/local/minio/mc alias set ${minio_alias} ${minio_server} ${minio_user} ${minio_password}
实例
/usr/local/minio/mc alias set minio_data_starrocks http://server_minio:9019 admin Administrator123# 2. minio集群创建桶star11:用于存储数据备份
语法:
/usr/local/minio/mc mb ${minio_alias}/${bucket_name}
实例:
/usr/local/minio/mc mb minio_data_starrocks/star11
1. 备份过程
集群A(旧集群)数据迁移到minio:3个FE( poc1、2、3), 3个BE(poc4、5、6)的 StarRocks。
1.1. 通过mysqlclient与starrocks进行关联
mysql -h${starrocks_leader_host} -P9030 -uroot -pstar_rocks;
1.2. 创建仓库与minio建立联系
-- 1. 创建仓库
语法:
CREATE REPOSITORY `${repo_name}`
WITH BROKER
ON LOCATION "s3a://${bucket_name}/backup"
PROPERTIES
(
"aws.s3.enable_ssl" = "false",
"aws.s3.access_key" = "${minio_username}",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.secret_key" = "${minio_password}",
"aws.s3.endpoint" = "${minio_server}"
);实例:
CREATE REPOSITORY `test_repo`
WITH BROKER
ON LOCATION "s3a://star11/backup"
PROPERTIES
(
"aws.s3.enable_ssl" = "false",
"aws.s3.access_key" = "admin",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.secret_key" = "Administrator123",
"aws.s3.endpoint" = "minio_server:9009"
);-- 2. 展示仓库
show REPOSITORY `test_repo`;如果仓库创建失败,或重新创建同名仓库,则删除仓库命令如下
DROP REPOSITORY `test_repo`;删除仓库时后记得手动在minio上的文件。
1.3. 备份数据到minio
备份语法:https://docs.starrocks.io/zh/docs/2.5/sql-reference/sql-statements/data-definition/BACKUP/
-- 1.备份命令
-- 以下示例在数据库 radar_test 中创建数据快照 sr_member_backup(命名随意) 并备份至仓库 test_repo 中。BACKUP SNAPSHOT radar_test.radar_test_backup
TO test_repo
PROPERTIES ("type" = "full");-- 2. 查看数据库radar_test备份过程:
show backup from radar_test \G;*************************** 1. row ***************************JobId: 129388SnapshotName: radar_test_backupDbName: radar_testState: FINISHEDBackupObjs: [radar_test.20230815_baseurl], [radar_test.20230815_baseurl.csv], [radar_test.dim_report_pro_detail], [radar_test.dim_report_pro_logs], [radar_test.dwd_qdas_monitor_donelog_test], [radar_test.dwd_thjl_d_xky], [radar_test.dwd_thjl_d_xky2], [radar_test.dwd_thjl_d_xky_20240125], [radar_test.ftp_baseurl], [radar_test.ods_pc_user_portrait_detail], [radar_test.ods_pc_user_portrait_detail2], [radar_test.ods_thjl_d], [radar_test.t], [radar_test.test2_100m_pc_user_portrait_detail], [radar_test.test2_10m_pc_user_portrait_detail], [radar_test.test2_1m_pc_user_portrait_detail], [radar_test.test2_join_id], [radar_test.test_100m_pc_user_portrait_detail], [radar_test.test_10m_pc_user_portrait_detail], [radar_test.test_1m_pc_user_portrait_detail]CreateTime: 2024-03-14 15:05:03
SnapshotFinishedTime: 2024-03-14 15:05:09UploadFinishedTime: 2024-03-14 15:16:36FinishedTime: 2024-03-14 15:16:45UnfinishedTasks:Progress:TaskErrMsg: [129534: S3: Fail to complete multipart upload for object starrocks-1/backup/__starrocks_repository_test_repo/__ss_radar_test_backup/__ss_content/__db_10228/__tbl_18770/__part_19744/__idx_18771/__19845/02000000006a04786743e0da3614f6285f61e260bcdfc887_0.dat.part, msg: The specified multipart upload does not exist. The upload ID may be invalid, or the upload may have been aborted or completed.]Status: [OK]Timeout: 86400看到State为FINISHED,Status为OK说明备份完成TaskErrMsg和Status:会显示任务过程中Task的一些错误信息,但只要State列不为CANCELLED,
就说明作业依然在继续,这些Task有可能会重试成功。当然,有些Task错误,也会直接导致作业失败。
当一次备份作业涉及到的表和数据都很多时,我们需要不时关注作业状态,若发现任务长时间没有进度或有其他问题,也可以将任务手动取消,取消语法为:
mysql> CANCEL BACKUP FROM db_name;
2. 迁移过程
迁移到集群B(新集群):
2.1. 通过mysqlclient与starrocks进行关联
mysql -h ${clusterB_server} -P9031 -uroot -pstar_rocks
2.2. 在新集群中创建仓库
注意在新集群中使用相同仓库名和地址创建仓库,否则将无法查看先前备份的数据快照。
-- 1. 创建数据库 新集群中需要建库,迁移的表不需要创建。
create database radar_test;-- 2. 创建与A集群相同的仓库CREATE REPOSITORY `test_repo`
WITH BROKER
ON LOCATION "s3a://star11/backup"
PROPERTIES
(
"aws.s3.enable_ssl" = "false",
"aws.s3.access_key" = "admin",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.secret_key" = "Administrator123",
"aws.s3.endpoint" = "${minio_server}:9019"
);-- 3. 查看仓库SHOW REPOSITORIES;-- 如果创建仓库失败,或想重新创建。使用如下命令删除仓库
DROP REPOSITORY test_repo;
2.3. 恢复数据到新集群
-- 在(旧集群)A集群中执行
-- 1. 连接A集群
mysql -h${star_rocks_cluster_fe_leader} -P9030 -uroot -pstar_rocks;-- 查看备份快照信息,用于恢复使用
mysql> SHOW SNAPSHOT ON test_repo;
+-------------------+-------------------------+--------+
| Snapshot | Timestamp | Status |
+-------------------+-------------------------+--------+
| radar_test_backup | 2024-03-14-15-05-03-957 | OK |
+-------------------+-------------------------+--------+-- 在(新集群)B集群中执行
-- 2. 将仓库 test_repo 中的数据快照 radar_test_backup恢复到数据库中radar_test,恢复三个数据副本。
-- 语法
RESTORE SNAPSHOT ${clusterB_database}.${clusterA_Snapshot_name}
FROM test_repo
PROPERTIES ("backup_timestamp"="${clusterA_Snapshot_Timestamp}","replication_num" = "3"
);-- 执行实例
RESTORE SNAPSHOT radar_test_1.radar_test_backup
FROM test_repo
PROPERTIES ("backup_timestamp"="2024-03-14-15-05-03-957","replication_num" = "3"
);Query OK, 0 rows affected (1.77 sec)-- 3. 查看备份进度SHOW RESTORE from radar_test \G;*************************** 1. row ***************************JobId: 10078Label: radar_test_backupTimestamp: 2024-03-14-15-05-03-957DbName: radar_testState: FINISHEDAllowLoad: falseReplicationNum: 1RestoreObjs: ... 会展示所有表和分区CreateTime: 2024-03-15 11:28:04MetaPreparedTime: 2024-03-15 11:28:07
SnapshotFinishedTime: 2024-03-15 11:28:10
DownloadFinishedTime: 2024-03-15 11:28:43FinishedTime: 2024-03-15 11:30:03UnfinishedTasks:Progress:TaskErrMsg:Status: [OK]Timeout: 86400如果State为FINISHED、Status为[OK],则迁移数据到新集群完成。
二、迁移过程(两个集群不互通的情况)
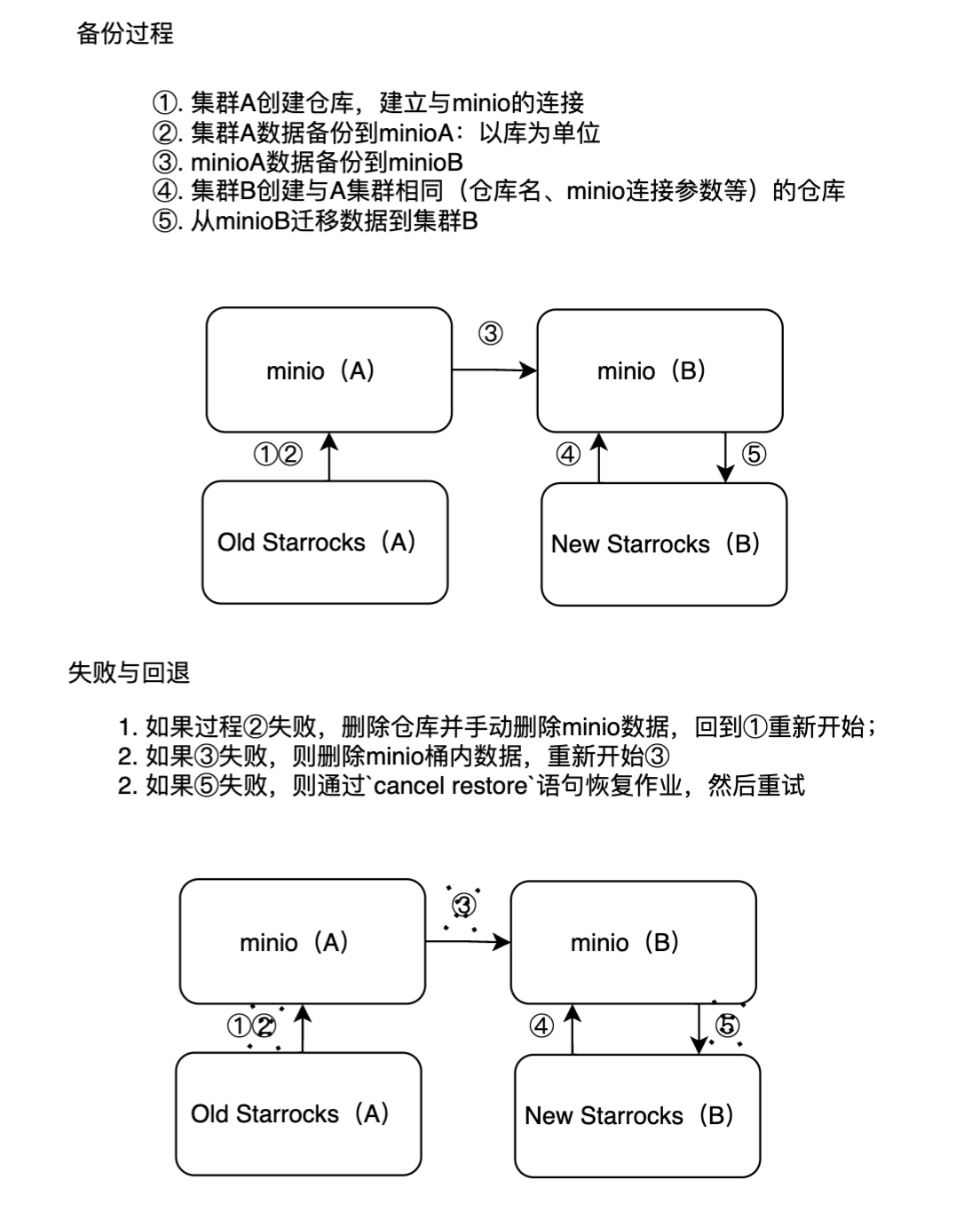
规划
| 序号 | 组件 | 说明 |
|---|---|---|
| 1 | minioA | 用于创建桶,将库备份放到minioA的桶中 |
| 2 | 集群A | 旧集群,用于将库迁移到minioA中 |
| 3 | minioB | minioA的数据迁移到minioB中 |
| 4 | 集群B | 新集群,从minioB迁移数据到集群B |
minioA操作
一. minioA操作
# 1. 创建minioA集群别名:用于后续操作;在任意minio节点
语法
/usr/local/minio/mc alias set ${minio_alias} ${minio_server} ${minio_user} ${minio_password}# 2. minioA集群创建桶star11:用于存储数据备份
语法:
/usr/local/minio/mc mb ${minio_alias}/${bucket_name}
实例:
/usr/local/minio/mc mb minio_data_starrocks/star11
1. 集群A数据迁移到minioA
集群A(旧集群)数据迁移到minio:3个FE( poc1、2、3), 3个BE(poc4、5、6)的 StarRocks。
1.1. 通过mysqlclient与starrocks进行关联
1.2. 创建仓库与minioA建立联系
1.3. 备份数据到minioA
如上过程参考:集群互通时的操作
2. minioA数据迁移到minioB
现在我们将minioA的文件下载到本地,然后从本地上传到minioB
2.1. 下载minioA中的文件到本地
# 将minioA中的桶star11的数据备份到/home/taiyi/minio-data目录
# 创建目录
mkdir -p /home/taiyi/minio-data/
# 备份到本地
语法
# /usr/local/minio/mc cp --recursive ${minioA_alias}/${bucket_name}/ ${local_dir}
实例
/usr/local/minio/mc cp --recursive minio_data_starrocks/star11/ /home/taiyi/minio-data/
2.2. 将文件上传到minioB
因为网络不互通,需要将文件从上述位置拷贝到minioB的客户端机器中,具体方法不再描述,用户自行操作。
现在
# 1. 设用户已将数据上传到minioB的客户机目录/home/taiyi/minio-data/下# 2. 创建minioB集群别名:用于后续操作;在任意minioB的客户端节点
语法
/usr/local/minio/mc alias set ${minioB_alias} ${minioB_server} ${minioB_user} ${minioB_password}# 3. minioB集群创建桶star11:用于上传数据备份
语法:
/usr/local/minio/mc mb ${minioB_alias}/${bucket_name}
实例:
/usr/local/minio/mc mb minio_data_starrocks_restore/star11# 4. 将文件夹下/home/taiyi/minio-data/所有数据上传到minioB中star11的桶中/usr/local/minio/mc cp --recursive /home/taiyi/minio-data/ minio_data_starrocks_restore/star11/
3.minioB数据迁移到集群B
迁移到集群B(新集群):
3.1. 通过mysqlclient与starrocks进行关联
3.2. 在新集群中创建仓库
3.3. 恢复数据到新集群
如上过程参考:集群互通时的操作
参考:
https://blog.csdn.net/ult_me/article/details/123235041
https://blog.csdn.net/gongxiucheng/article/details/132675927
这篇关于【运维】StarRocks数据迁移到新集群(针对于集群互通、不互通的情况)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








