集群专题

Redis中哨兵机制和集群的区别及说明
《Redis中哨兵机制和集群的区别及说明》Redis哨兵通过主从复制实现高可用,适用于中小规模数据;集群采用分布式分片,支持动态扩展,适合大规模数据,哨兵管理简单但扩展性弱,集群性能更强但架构复杂,根... 目录一、架构设计与节点角色1. 哨兵机制(Sentinel)2. 集群(Cluster)二、数据分片

Jenkins分布式集群配置方式
《Jenkins分布式集群配置方式》:本文主要介绍Jenkins分布式集群配置方式,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教... 目录1.安装jenkins2.配置集群总结Jenkins是一个开源项目,它提供了一个容易使用的持续集成系统,并且提供了大量的plugin满

Redis分片集群、数据读写规则问题小结
《Redis分片集群、数据读写规则问题小结》本文介绍了Redis分片集群的原理,通过数据分片和哈希槽机制解决单机内存限制与写瓶颈问题,实现分布式存储和高并发处理,但存在通信开销大、维护复杂及对事务支持... 目录一、分片集群解android决的问题二、分片集群图解 分片集群特征如何解决的上述问题?(与哨兵模

SpringBoot连接Redis集群教程
《SpringBoot连接Redis集群教程》:本文主要介绍SpringBoot连接Redis集群教程,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教... 目录1. 依赖2. 修改配置文件3. 创建RedisClusterConfig4. 测试总结1. 依赖 <de

Nginx使用Keepalived部署web集群(高可用高性能负载均衡)实战案例
《Nginx使用Keepalived部署web集群(高可用高性能负载均衡)实战案例》本文介绍Nginx+Keepalived实现Web集群高可用负载均衡的部署与测试,涵盖架构设计、环境配置、健康检查、... 目录前言一、架构设计二、环境准备三、案例部署配置 前端 Keepalived配置 前端 Nginx

Redis高可用-主从复制、哨兵模式与集群模式详解
《Redis高可用-主从复制、哨兵模式与集群模式详解》:本文主要介绍Redis高可用-主从复制、哨兵模式与集群模式的使用,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝... 目录Redis高可用-主从复制、哨兵模式与集群模式概要一、主从复制(Master-Slave Repli
Redis分片集群的实现
《Redis分片集群的实现》Redis分片集群是一种将Redis数据库分散到多个节点上的方式,以提供更高的性能和可伸缩性,本文主要介绍了Redis分片集群的实现,具有一定的参考价值,感兴趣的可以了解一... 目录1. Redis Cluster的核心概念哈希槽(Hash Slots)主从复制与故障转移2.

centos7基于keepalived+nginx部署k8s1.26.0高可用集群
《centos7基于keepalived+nginx部署k8s1.26.0高可用集群》Kubernetes是一个开源的容器编排平台,用于自动化地部署、扩展和管理容器化应用程序,在生产环境中,为了确保集... 目录一、初始化(所有节点都执行)二、安装containerd(所有节点都执行)三、安装docker-
如何在一台服务器上使用docker运行kafka集群
《如何在一台服务器上使用docker运行kafka集群》文章详细介绍了如何在一台服务器上使用Docker运行Kafka集群,包括拉取镜像、创建网络、启动Kafka容器、检查运行状态、编写启动和关闭脚本... 目录1.拉取镜像2.创建集群之间通信的网络3.将zookeeper加入到网络中4.启动kafka集群
Nacos集群数据同步方式
《Nacos集群数据同步方式》文章主要介绍了Nacos集群中服务注册信息的同步机制,涉及到负责节点和非负责节点之间的数据同步过程,以及DistroProtocol协议在同步中的应用... 目录引言负责节点(发起同步)DistroProtocolDistroSyncChangeTask获取同步数据getDis
服务器集群同步时间手记
1.时间服务器配置(必须root用户) (1)检查ntp是否安装 [root@node1 桌面]# rpm -qa|grep ntpntp-4.2.6p5-10.el6.centos.x86_64fontpackages-filesystem-1.41-1.1.el6.noarchntpdate-4.2.6p5-10.el6.centos.x86_64 (2)修改ntp配置文件 [r

HDFS—集群扩容及缩容
白名单:表示在白名单的主机IP地址可以,用来存储数据。 配置白名单步骤如下: 1)在NameNode节点的/opt/module/hadoop-3.1.4/etc/hadoop目录下分别创建whitelist 和blacklist文件 (1)创建白名单 [lytfly@hadoop102 hadoop]$ vim whitelist 在whitelist中添加如下主机名称,假如集群正常工作的节

Hadoop集群数据均衡之磁盘间数据均衡
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可以执行磁盘数据均衡命令。(Hadoop3.x新特性) plan后面带的节点的名字必须是已经存在的,并且是需要均衡的节点。 如果节点不存在,会报如下错误: 如果节点只有一个硬盘的话,不会创建均衡计划: (1)生成均衡计划 hdfs diskbalancer -plan hadoop102 (2)执行均衡计划 hd
搭建Kafka+zookeeper集群调度
前言 硬件环境 172.18.0.5 kafkazk1 Kafka+zookeeper Kafka Broker集群 172.18.0.6 kafkazk2 Kafka+zookeeper Kafka Broker集群 172.18.0.7 kafkazk3
一种改进的red5集群方案的应用、基于Red5服务器集群负载均衡调度算法研究
转自: 一种改进的red5集群方案的应用: http://wenku.baidu.com/link?url=jYQ1wNwHVBqJ-5XCYq0PRligp6Y5q6BYXyISUsF56My8DP8dc9CZ4pZvpPz1abxJn8fojMrL0IyfmMHStpvkotqC1RWlRMGnzVL1X4IPOa_ 基于Red5服务器集群负载均衡调度算法研究 http://ww

828华为云征文|华为云Flexus X实例docker部署rancher并构建k8s集群
828华为云征文|华为云Flexus X实例docker部署rancher并构建k8s集群 华为云最近正在举办828 B2B企业节,Flexus X实例的促销力度非常大,特别适合那些对算力性能有高要求的小伙伴。如果你有自建MySQL、Redis、Nginx等服务的需求,一定不要错过这个机会。赶紧去看看吧! 什么是华为云Flexus X实例 华为云Flexus X实例云服务是新一代开箱即用、体

kubernetes集群部署Zabbix监控平台
一、zabbix介绍 1.zabbix简介 Zabbix是一个基于Web界面的分布式系统监控的企业级开源软件。可以监视各种系统与设备的参数,保障服务器及设备的安全运营。 2.zabbix特点 (1)安装与配置简单。 (2)可视化web管理界面。 (3)免费开源。 (4)支持中文。 (5)自动发现。 (6)分布式监控。 (7)实时绘图。 3.zabbix的主要功能
laravel框架实现redis分布式集群原理
在app/config/database.php中配置如下: 'redis' => array('cluster' => true,'default' => array('host' => '172.21.107.247','port' => 6379,),'redis1' => array('host' => '172.21.107.248','port' => 6379,),) 其中cl

VMware8实现高可用(HA)集群
陈科肇 =========== 操作系统:中标麒麟高级操作系统V6 x86-64 实现软件:中标麒麟高可用集群软件 ======================== 1.环境的规划与配置 硬件要求 服务器服务器至少需要 2 台,每台服务器至少需要 2 块网卡以做心跳与连接公网使用存储环境 建议使用一台 SAN/NAS/ISCSI 存储作为数据共享存储空间 软
用Cri-O,Sealos CLI,Kubeadm方式部署K8s高可用集群
3.6 Cri-O方式部署K8s集群 注意:基于Kubernetes基础环境 3.6.1 所有节点安装配置cri-o [root@k8s-all ~]# VERSION=1.28[root@k8s-all ~]# curl -L -o /etc/yum.repos.d/devel:kubic:libcontainers:stable.repo https://download.opensu

Redis-主从集群
主从架构 单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。 主从数据同步原理 全量同步 主从第一次建立连接时,会执行全量同步,将master节点的所有数据都拷贝给slave节点,流程: 判断是否是第一次同步,如果是,返回版本信息(replication id 和offset),将salve节点的版本信息变为master的
Zookeeper集群是如何升级到新版本的
方案1:复用老数据方案 这是经过实践的升级方案,该方案是复用旧版本的数据,zk集群拓扑,配置文件都不变,只是启动的程序为最新的版本。 参考文章: Zookeeper集群是如何升级到新版本的 方案2:重新建立数据方案 该方案的思路是:先停掉一台follower的机器上的服务,然后加入一个新版本的zk(zk的数据目录是空的),然后启动新zk,之后新zk会把旧集群中的数据同步过来。之后再操作另
集群环境下为雪花算法生成全局唯一机器ID策略
雪花算法是生成数据id非常好的一种方式,机器id是雪花算法不可分割的一部分。但是对于集群应用,让不同的机器自动产生不同的机器id传统做法就是针对每一个机器进行单独配置,但这样做不利于集群水平扩展,且操作过程非常复杂,所以每一个机器在集群环境下是一个头疼的问题。现在借助spring+redis,给出一种策略,支持随意水平扩展,肥肠好用。 大致策略分为4步: 1.对机器ip进行hash,对某一个(大于

Kubernetes高可用集群搭建(kubeadm)
1 Kubernetes高可用集群介绍 前面已经介绍了Kubernetes的集群部署,但是都只是介绍的单master节点的情况,由于单master节点的可靠性不高,不适合实际的生产环境,此处介绍如何实现多master节点的高可用集群的搭建。 2 安装要求 一台或多台机器,操作系统CentOS7.x-x86_64硬件配置:2G或更多ARM,2个CPU或更多CPU,硬盘20G及以上集群中所有机器
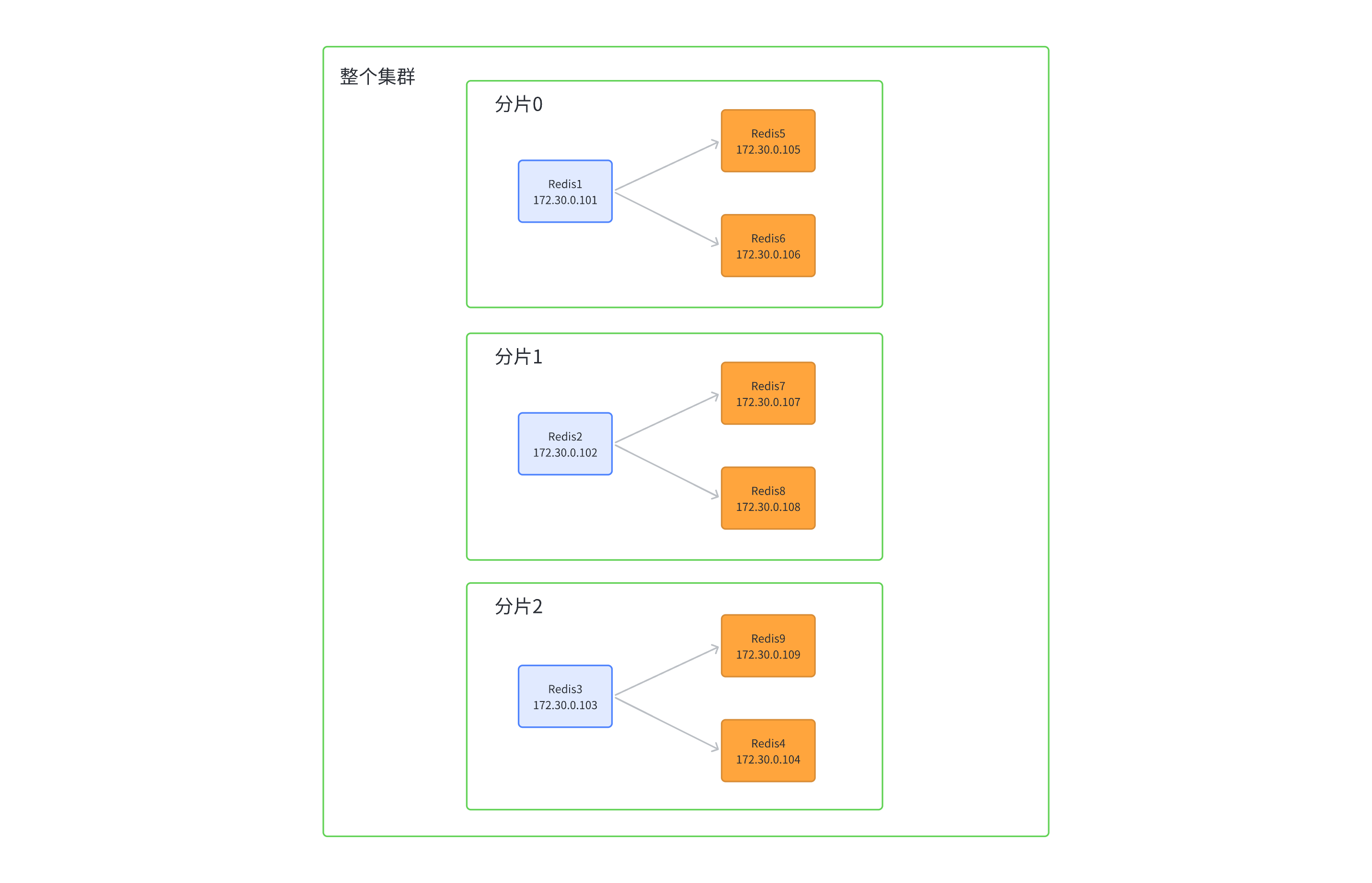
【Redis】Redis 集群搭建与管理: 原理、实现与操作
目录 集群 (Cluster)基本概念数据分片算法哈希求余⼀致性哈希算法哈希槽分区算法 (Redis 使⽤) 集群搭建 (基于 docker)第⼀步: 创建⽬录和配置第⼆步: 编写 docker-compose.yml第三步: 启动容器第四步: 构建集群 主节点宕机演⽰效果处理流程1)故障判定2)故障迁移 集群扩容第⼀步: 把新的主节点加⼊到集群第⼆步: 重新分配 slots第三步: 给新的