迁移专题

在不同系统间迁移Python程序的方法与教程
《在不同系统间迁移Python程序的方法与教程》本文介绍了几种将Windows上编写的Python程序迁移到Linux服务器上的方法,包括使用虚拟环境和依赖冻结、容器化技术(如Docker)、使用An... 目录使用虚拟环境和依赖冻结1. 创建虚拟环境2. 冻结依赖使用容器化技术(如 docker)1. 创

SQL Server数据库迁移到MySQL的完整指南
《SQLServer数据库迁移到MySQL的完整指南》在企业应用开发中,数据库迁移是一个常见的需求,随着业务的发展,企业可能会从SQLServer转向MySQL,原因可能是成本、性能、跨平台兼容性等... 目录一、迁移前的准备工作1.1 确定迁移范围1.2 评估兼容性1.3 备份数据二、迁移工具的选择2.1

将sqlserver数据迁移到mysql的详细步骤记录
《将sqlserver数据迁移到mysql的详细步骤记录》:本文主要介绍将SQLServer数据迁移到MySQL的步骤,包括导出数据、转换数据格式和导入数据,通过示例和工具说明,帮助大家顺利完成... 目录前言一、导出SQL Server 数据二、转换数据格式为mysql兼容格式三、导入数据到MySQL数据
CentOs7上Mysql快速迁移脚本
因公司业务需要,对原来在/usr/local/mysql/data目录下的数据迁移到/data/local/mysql/mysqlData。 原因是系统盘太小,只有20G,几下就快满了。 参考过几篇文章,基于大神们的思路,我封装成了.sh脚本。 步骤如下: 1) 先修改好/etc/my.cnf, ##[mysqld] ##datadir=/data/loc

CentOS下mysql数据库data目录迁移
https://my.oschina.net/u/873762/blog/180388 公司新上线一个资讯网站,独立主机,raid5,lamp架构。由于资讯网是面向小行业,初步估计一两年内访问量压力不大,故,在做服务器系统搭建的时候,只是简单分出一个独立的data区作为数据库和网站程序的专区,其他按照linux的默认分区。apache,mysql,php均使用yum安装(也尝试

Linux Centos 迁移Mysql 数据位置
转自:http://www.tuicool.com/articles/zmqIn2 由于业务量增加导致安装在系统盘(20G)磁盘空间被占满了, 现在进行数据库的迁移. Mysql 是通过 yum 安装的. Centos6.5Mysql5.1 yum 安装的 mysql 服务 查看 mysql 的安装路径 执行查询 SQL show variables like

风格控制水平创新高!南理工InstantX小红书发布CSGO:简单高效的端到端风格迁移框架
论文链接:https://arxiv.org/pdf/2408.16766 项目链接:https://csgo-gen.github.io/ 亮点直击 构建了一个专门用于风格迁移的数据集设计了一个简单但有效的端到端训练的风格迁移框架CSGO框架,以验证这个大规模数据集在风格迁移中的有益效果。引入了内容对齐评分(Content Alignment Score,简称CAS)来评估风格迁移

从VC6迁移至VS2005 ,VS2008
最近开发平台由VC6.0升级至VS2005,需要将原有的项目迁移,特将碰到的问题归纳如下: 1消息映射 VS2005对消息的检查更为严格,以前在VC6下完全正常运行的消息映射在VS2005下编译不通过 a. ON_MESSAGE(message,OnMyMessage); OnMyMessage返回值必须为LRESULT,其形式为:afx_msg LRESULT OnMyMessage(

基于人工智能的图像风格迁移系统
目录 引言项目背景环境准备 硬件要求软件安装与配置系统设计 系统架构关键技术代码示例 数据预处理模型训练模型预测应用场景结论 1. 引言 图像风格迁移是一种计算机视觉技术,它可以将一种图像的风格(如梵高的绘画风格)迁移到另一幅图像上,从而生成一幅具有特定艺术风格的图像。基于深度学习的图像风格迁移技术已经广泛应用于艺术创作、图像处理等领域。本文将介绍如何构建一个基于人工智能的图像风格迁移

gs_dump和gs_dumpall 迁移数据库
目录 0、源端实例收集AWR1、创建目录2、gs_dump - 业务停机3、gs_dumpall - 业务停机4、拷贝文件5、目标实例导入数据 0、源端实例收集AWR https://blog.csdn.net/hezuijiudexiaobai/article/details/134220949 1、创建目录 mkdir -p /pgdata/data/opengauss-
ASM 10G 基于RMAN 迁移
ASM 10G 基于RMAN 迁移 场景 单节点基于10G R2 的数据库,其数据文件及日志文件均存放在ASM 里,现在为业务需求,将此数据库做迁 移,迁移到另个机房,但是两个机房的网络是通畅的,为尽量减少数据的丢失及平稳迁移和经济实惠,迁 移时,数据库需停应用 工具 本次采用RMAN 的duplicate 命令来进行迁移,运用此命令简化复杂度; 一、源库和目标库的
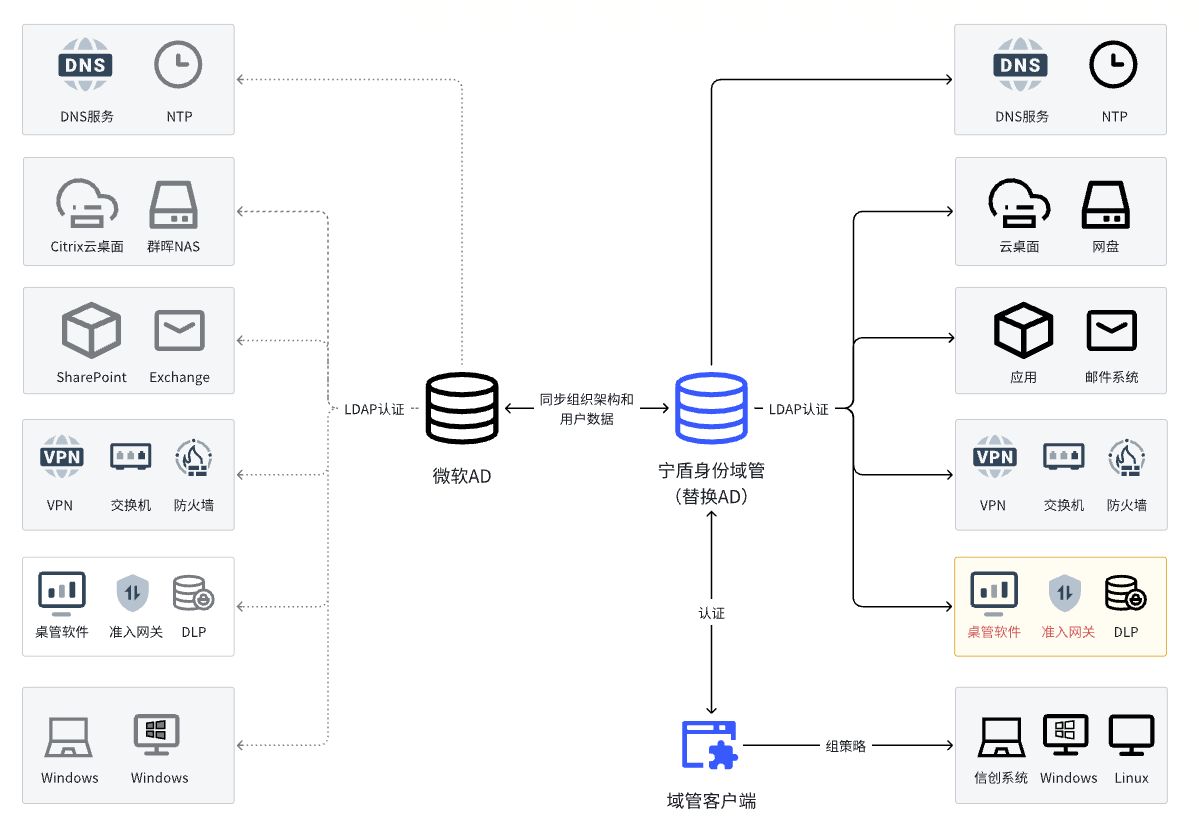
替换Windows AD时,网络准入场景如何迁移对接国产身份域管?
Windows AD是迄今为止身份管理和访问控制领域的最佳实践,全球约90%的中大型企业采用AD作为底层数字身份基础设施,管理组织、用户、应用、网络、终端等IT资源。但随着信创建设在党政机关、金融、央国企、电力等各行各业铺开,对Windows AD域的替换成为企业信息安全建设中不可避免的议题之一。 鉴于AD在企业中的应用程度不同,可将企业分为轻度、中度及深度三类Windows AD

HBase实践 | HBase TB级数据规模不停机迁移最佳实践
背景 有关HBase集群如何做不停服的数据迁移一直都是云HBase被问的比较多的一个问题,目前有许多开源的工具或者HBase本身集成的方案在性能、稳定性、使用体验上都不是很好,因此阿里云提供了BDS迁移服务,可以帮助云上客户实现TB级数据规模不停机迁移 支持场景 HBase大版本升级, 1.x升级2.x集群配置升级,8核16G升级为16核32G集群网络环境变更,经典网络迁移到VPC异地跨机房迁

MySQL 迁移中 explicit_defaults_for_timestamp 参数影响
前言 最近在做数据迁移的时候,使用的是云平台自带的同步工具,在预检查阶段,当时报错 explicit_defaults_for_timestamp 参数在目标端为 off 建议修改 on,有什么风险呢?在此记录下。 测试对比 MySQL 默认情况下 explicit_defaults_for_timestamp = 0 我们对比一下看看。 explicit_defaults_for_tim

成功进行云迁移与现代化的7个关键步骤
随着全球逐渐从供应链噩梦和因封锁及控制措施引起的通胀急剧上升中恢复正常,一个显而易见的问题是:运营成本必须降低。 但这不仅仅是成本问题;商业领袖还必须准备好增加股东价值,并为客户和目标市场提供最优价值。尽管实现这一目标的方法有很多,但没有一种方法能在云迁移的所有三个方面达到这种效果。 然而,云迁移和现代化的实施部分往往充满挑战,这些挑战可能迅速逆转甚至阻碍任何已经实现的收益。以下是七个成功的云

Sqoop 数据迁移
Sqoop 数据迁移 一、Sqoop 概述二、Sqoop 优势三、Sqoop 的架构与工作机制四、Sqoop Import 流程五、Sqoop Export 流程六、Sqoop 安装部署6.1 下载解压6.2 修改 Sqoop 配置文件6.3 配置 Sqoop 环境变量6.4 添加 MySQL 驱动包6.5 测试运行 Sqoop6.5.1 查看Sqoop命令语法6.5.2 测试数据库连接

震惊,从仿真走向现实,3D Map最大提升超12,Cube R-CNN使用合成数据集迁移到真实数据集
震惊,从仿真走向现实,3D Map最大提升超12,Cube R-CNN使用合成数据集迁移到真实数据集 Abstract 由于摄像机视角多变和场景条件不可预测,在动态路边场景中从单目图像中准确检测三维物体仍然是一个具有挑战性的问题。本文介绍了一种两阶段的训练策略来应对这些挑战。我们的方法首先在大规模合成数据集RoadSense3D上训练模型,该数据集提供了多样化的场景以实现稳健的特征学习。随后,

自动驾驶真正踏出迈向“用户”的第一步:IROS24新SOTA提出个性化的实例迁移模仿学习
导读: 本文针对自动驾驶规划任务,提出了一种基于实例的迁移模仿学习方法,通过预先训练的微调框架从专家域迁移专业知识,以解决用户域数据稀缺问题。实验结果显示,该方法能有效捕捉用户驾驶风格并实现具有竞争力的规划性能,但仍需开发合适的用户风格测量方法。©️【深蓝AI】编译 1. 摘要 个性化运动规划在自动驾驶领域中具有重要意义,可以满足个人用户的独特需求。然而,以往的工作在同时解决两个关键问题
从Milvus迁移DashVector
本文档演示如何从Milvus将Collection数据全量导出,并适配迁移至DashVector。方案的主要流程包括: 首先,升级Milvus版本,目前Milvus只有在最新版本(v.2.3.x)中支持全量导出其次,将Milvus Collection的Schema信息和数据信息导出到具体的文件中最后,以导出的文件作为输入来构建DashVector Collection并数据导入 下面,将详细
conda迁移windows虚拟环境到linux
conda迁移windows虚拟环境到linux 近期使用python在windows下开发了一些算法,使用了conda来管理开发环境,准备迁移到linux下进行测试,Linux服务器在内网无法联网,迁移过程颇费周折,记录一下。 Conda是广为熟知的包管理器和虚拟环境管理器,有Anaconda,Miniconda两个版本,这里我使用的是Miniconda,安装过程略,安装好以后可以使用con

一键云迁移:利用VMware PowerCLI将OVA虚拟机顺利迁移到AWS
哈喽大家好,欢迎来到虚拟化时代君(XNHCYL)。 “ 大家好,我是虚拟化时代君,一位潜心于互联网的技术宅男。这里每天为你分享各种你感兴趣的技术、教程、软件、资源、福利…(每天更新不间断,福利不见不散) 第一章、小叙 众所周知,在vSphere6.5/6.7版本后,已经无法通过Web Console导出虚拟机为OVA(单个文件),vSphere 7和8只能通过Po
Elasticsearch 基于Reindex跨集群数据迁移
Reindex可用于Elasticsearch跨集群数据迁移,并且不会复制原索引的mapping(映射)、shard(分片)、replicas(副本)等配置信息。 1、仅在目标ES的elasticsearch.yml文件中添加如下配置 #reindex操作远程列表 reindex.remote.whitelist: ["192.168.101.101:9200"] 2、在目标集群执行

pytorch+深度学习实现图像的神经风格迁移
本文的完整代码和部署教程已上传至本人的GitHub仓库,欢迎各位朋友批评指正! 1.各代码文件详解 1.1 train.py train.py 文件负责训练神经风格迁移模型。 加载内容和风格图片:使用 utils.load_image 函数加载并预处理内容和风格图片。初始化生成图像:将内容图像加上随机噪声作为初始生成图像。加载模型:实例化并加载神经风格迁移模型。设置优化器和损失函数:
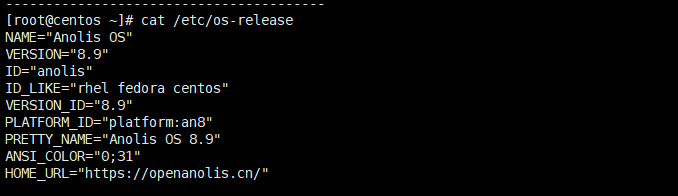
信创实践(2):利用Leapp工具迁移CentOS至AnolisOS,实现系统升级与自主可控
1. 引言 为了满足用户在CentOS退出后对操作系统使用的诉求,OpenAnolis龙蜥社区正式发布了Anolis OS。越来越多的CentOS客户期望能够迁移到Anolis OS上来。操作系统迁移是一个复杂工程,手工迁移技术要求高,操作复杂度强,需要耗费大量的人力和时间。OpenAnolis龙蜥社区针对这一痛点,为CentOS用户提供了迁移到Anolis OS的迁移解决方案AOMS ( An

ubuntu 20.4安装 cloudcanal 数据迁移工具
该工具支持同步的数据库如下图 1 安装环境依赖 备注,需要docker和docker-compose【最新版本即可】 sudo apt updatesudo apt install apt-transport-https ca-certificates curl gnupg-agent software-properties-commonsudo apt-get install -