本文主要是介绍风格控制水平创新高!南理工InstantX小红书发布CSGO:简单高效的端到端风格迁移框架,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


论文链接:https://arxiv.org/pdf/2408.16766
项目链接:https://csgo-gen.github.io/
亮点直击
- 构建了一个专门用于风格迁移的数据集
- 设计了一个简单但有效的端到端训练的风格迁移框架CSGO框架,以验证这个大规模数据集在风格迁移中的有益效果。
- 引入了内容对齐评分(Content Alignment Score,简称CAS)来评估风格迁移的质量,有效衡量迁移后内容损失的程度。
- 大量的定性和定量研究验证了本文提出的方法在零样本风格迁移方面取得了先进的成果。
扩散模型在受控图像生成方面展示了卓越的能力,这进一步激发了对图像风格迁移的兴趣。现有的工作主要集中在基于训练自由的方法(例如图像反演),这是由于特定数据的稀缺。在本研究中,本文提出了一种用于内容-风格-风格化图像三元组的数据构建pipeline,该pipeline生成并自动清理风格化数据三元组。基于此pipeline,本文构建了IMAGStyle数据集,这是第一个包含21万图像三元组的大规模风格迁移数据集,供社区探索和研究。配备IMAGStyle数据集,本文提出了CSGO,一种基于端到端训练的风格迁移模型,该模型通过独立特征注入显式解耦内容和风格特征。统一的CSGO实现了图像驱动的风格迁移、文本驱动的风格化合成以及文本编辑驱动的风格化合成。大量实验表明,本文的方法在增强图像生成中的风格控制能力方面是有效的。
数据 pipeline
在本节中,本文首先介绍用于构建内容-风格-风格化图像三元组的提议pipeline。然后,本文详细描述构建的IMAGStyle数据集。
构建内容-风格-风格化图像三元组的pipeline
风格化图像生成。 给定任意的内容图像 C C C 和任意的风格图像 S S S,目标是生成一个风格化图像 T T T,它既保留 C C C 的内容,又采用 S S S 的风格。本文受到 B-LoRA Frenkel 等人(2024)的启发,该研究发现内容 LoRA 和风格 LoRA 可以通过 SD 训练的 LoRA 隐式分离,分别保留原始图像的内容和风格信息。因此,本文首先使用大量的内容和风格图像训练大量的 LoRA。为了确保生成的图像 T T T 的内容尽可能与 C C C 对齐,针对 C C C 的 LoRA 仅使用一个内容图像 C C C 进行训练。
然后,每个训练好的 LoRA 通过 Frenkel 等人(2024)提到的隐式分离方法分解为一个内容 LoRA 和一个风格 LoRA。最后,将图像 C C C 的内容 LoRA 与 S S S 的风格 LoRA 结合,使用基础模型生成目标图像 T = { T 1 , T 2 , … , T n } T = \{T_1, T_2, \ldots, T_n\} T={T1,T2,…,Tn}。然而,隐式分离方法不稳定,导致内容和风格 LoRA 无法可靠地保留内容或风格信息。这表现为生成的图像 T i T_i Ti 并不总是与 C C C 的内容一致,如下图 2 所示。因此,有必要过滤 T T T,选择最合理的 T i T_i Ti 作为目标图像。

风格化图像清理。 通过人工参与的慢速数据清理方法对于构建大规模风格化数据三元组是不可接受的。为此,本文开发了一种自动清理方法,以高效地获得理想且高质量的风格化图像 T T T。首先,本文提出了一个内容对齐评分(CAS),它有效地衡量生成图像与内容图像的内容对齐情况。它被定义为生成图像和原始内容图像的内容语义特征(不包含风格信息)之间的特征距离。其表示如下:
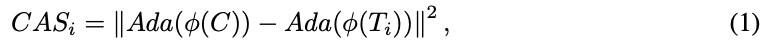
其中 C A S i CAS_i CASi 表示生成图像 T i T_i Ti 的内容对齐评分, ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 表示图像编码器。
本文比较了主流的特征提取器,结果显示最接近人工筛选结果的是 DINOV2 Li 等人(2023)。 A d a ( F ) Ada(F) Ada(F) 表示移除风格信息的特征 F F F 的函数。本文遵循 AdaIN Huang & Belongie (2017) 的方法,用均值和方差来表示风格信息。其表示如下:

其中, μ ( F ) \mu(F) μ(F) 和 ρ ( F ) \rho(F) ρ(F) 分别表示特征 F F F 的均值和方差。显然,更小的 C A S CAS CAS 表明生成的图像更接近原始图像的内容。在下面算法1中,本文提供了本文的pipeline的伪代码。

IMAGSTYLE 数据集详细信息
内容图像。 为了确保内容图像具有清晰的语义信息并在训练后便于分离,本文使用显著性检测数据集 MSRA10K和 MSRA-B作为内容图像。此外,对于素描风格化,本文从 ImageNet-Sketch中抽取了1000张素描图像作为内容图像。内容图像的类别分布如下图3所示。本文使用 BLIP(Li 等人,2023)为每个内容图像生成一个标题。总共训练了11,000张内容图像,并用作内容 LoRA。

风格图像。 为了确保风格多样性的丰富性,本文从Wikiart数据集中抽取了5000张不同绘画风格的图像(历史画、肖像画、风俗画、风景画和静物画)。此外,本文使用Midjourney生成了5000张涵盖多种风格的图像,包括古典、现代、浪漫、现实主义、超现实主义、抽象、未来主义、明亮、黑暗等风格。总共使用了10,000张风格图像来训练风格LoRA。
数据集。 基于前文中描述的pipeline,本文构建了一个风格迁移数据集IMAGStyle,该数据集包含210,000个内容-风格-风格化图像三元组作为训练数据集。此外,本文从网络上收集了248张内容图像,这些图像包含真实场景、素描场景、人脸和风格场景的图像,以及206张不同场景的风格图像作为测试数据集。在测试中,每张内容图像会被转换为206种风格。此数据集将用于社区研究风格迁移和风格化合成。
方法
CSGO框架
所提出的风格迁移模型CSGO,如下图4所示,旨在实现任意图像的任意风格化,而无需微调,包括素描和自然图像驱动的风格迁移、文本驱动的风格化合成以及文本编辑驱动的风格化合成。得益于所提出的IMAGStyle数据集,CSGO支持端到端的风格迁移训练范式。为了确保有效的风格迁移和准确的内容保留,本文精心设计了内容和风格控制模块。此外,为了减少内容图像泄露风格信息或风格图像泄露内容的风险,内容控制和风格控制模块被明确解耦,对应的特征被独立提取。具体来说,本文将CSGO分为两个主要组件,并详细描述它们。

内容控制,内容控制的目的是确保风格化图像保留内容图像的语义、布局和其他特征。为此,本文精心设计了两种内容控制方法。首先,本文通过预训练的ControlNet实现内容控制,其输入是内容图像及其对应的标题。本文利用特定内容可控模型(Tile ControlNet)的能力,减少从头训练内容保留的数据需求和计算成本。紧随ControlNet之后,ControlNet的输出直接注入到基础模型(预训练UNet in SD)的上采样块中,以获得融合输出 D i ′ = D i + δ c × C i D'_i = D_i + \delta_c \times C_i Di′=Di+δc×Ci,其中 D i D_i Di表示基础模型第 i i i块的输出, C i C_i Ci表示ControlNet第 i i i块的输出, δ c \delta_c δc表示融合权重。此外,为了在基础模型的下采样块中实现内容控制,本文利用了一个额外的可学习交叉注意力层,将内容特征注入到下采样块中。具体来说,本文使用预训练的CLIP图像编码器和一个可学习的投影层来提取内容图像的语义特征 F ( C ) ′ F(C)' F(C)′。然后,本文利用一个额外的交叉注意力层将提取的内容特征注入到基础模型的下采样块中,即 D C ′ = D + λ c × D C D'_C = D + \lambda_c \times D_C DC′=D+λc×DC,其中 D D D表示基础模型的输出, D C D_C DC表示内容IP-Adapter的输出, λ c \lambda_c λc表示融合权重。这两种内容控制策略确保了风格迁移过程中内容损失较小。
模型训练和推理
训练。 基于提出的数据集IMAGStyle,我们的CSGO是首个端到端风格迁移训练的实现。给定内容图像 C C C、内容图像的描述 P P P、风格图像 S S S和目标图像 T T T,我们基于预训练的扩散模型训练一个风格迁移网络。我们的训练目标是建模在内容图像和风格图像条件下,目标图像 T T T与高斯噪声之间的关系,表示如下:
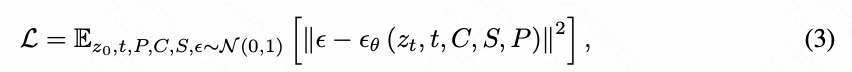
其中, ϵ \epsilon ϵ表示随机采样的高斯噪声, ϵ θ \epsilon_\theta ϵθ 表示CSGO的可训练参数, t t t表示时间步。注意,在训练过程中,潜变量 z t z_t zt是通过风格图像 T T T构建的, z t = α ˉ t ψ ( T ) + 1 − α ˉ t ϵ z_t = \sqrt{\bar{\alpha}_t}\psi(T) + \sqrt{1 - \bar{\alpha}_t}\epsilon zt=αˉtψ(T)+1−αˉtϵ,其中 ψ ( ⋅ ) \psi(\cdot) ψ(⋅)是将原始输入映射到潜在空间的函数, α ˉ t \bar{\alpha}_t αˉt与扩散模型一致。我们在训练阶段随机丢弃内容图像和风格图像的条件,以在推断阶段启用无分类器指导。
推理。 在推理阶段,我们采用无分类器指导。时间步 t t t 的输出表示如下:
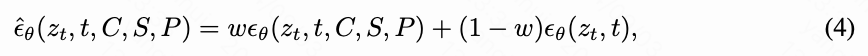
其中 w w w 表示无分类器指导因子(CFG)。
实验
实验设置
设置。 在IMAGStyle数据集中,训练阶段我们建议使用“a [vcp]”作为内容图像的提示词,使用“a [stp]”作为风格图像的提示词。秩值设置为64,每个B-LoRA训练1000步。生成阶段,我们建议使用“a [vcp] in [stv] style”作为提示词。对于CSGO框架,使用stabilityai/stable-diffusion-xl-base-1.0作为基础模型,预训练的ViT-H作为图像编码器,以及TTPlanet/TTPLanet SDXL Controlnet Tile Realistic作为ControlNet。图像统一设置为512×512分辨率。文本、内容图像和风格图像的丢弃率为0.15。学习率为 1 e − 4 1e^{-4} 1e−4。训练阶段, λ c = λ s = δ c = 1.0 \lambda_c = \lambda_s = \delta_c = 1.0 λc=λs=δc=1.0。推理阶段,我们建议 λ c = λ s = 1.0 \lambda_c = \lambda_s = 1.0 λc=λs=1.0 和 δ c = 0.5 \delta_c = 0.5 δc=0.5。我们的实验在8个NVIDIA H800 GPU(80GB)上进行,每个GPU的批量大小为20,训练80000步。
数据集和评估。 使用提出的IMAGStyle作为训练数据集,并使用其测试数据集作为评估数据集。我们采用Somepalli等人提出的CSD评分作为评估指标来评估风格相似性。同时,我们使用提出的内容对齐评分(CAS)作为评估指标来评估内容相似性。
基线方法。 比较了最近的几种先进的基于反演的风格识别方法,包括Chung等人(2024)的StyleID、Hertz等人(2024)的StyleAligned方法,以及基于Transformer结构的StyTR2 Deng等人(2022)。此外,还比较了Wang等人(2024a)的Instantstyle和Junyao等人(2024)的StyleShot(及其细粒度控制方法StyleShot-lineart),这些方法引入了ControlNet和IPAdapter结构作为基线。在文本驱动的风格控制任务中,我们还引入了Qi等人(2024)的DEADiff作为基线。
实验结果
图像驱动的风格迁移。 在下表1中,展示了所提出方法在图像驱动风格迁移任务中与最近先进方法的CSD评分和CAS。就风格控制而言,我们的CSGO获得了最高的CSD评分,表明CSGO在风格控制方面达到了最先进的水平。由于采用了解耦的风格注入方法,所提出的CSGO能够有效地提取风格特征并将其与高质量的内容特征融合。如下图5所示,CSGO在自然、素描、人脸和艺术场景中精确地迁移风格,同时保持内容的语义。


在内容保留方面,可以观察到基于反演的StyleID和StyleAligned在素描风格迁移场景中过于强烈地保持了原始内容(CAS非常低)。然而,它们无法注入风格信息,因为CSD评分很低。使用线条来控制内容的InstantStyle和StyleShot(包括Lineart)受线条细节水平的影响,在不同程度上会丢失内容(如人脸场景)。所提出的CSGO直接利用内容图像的所有信息,内容保留效果最佳。上表1中的定量结果也表明,所提出的CSGO在实现精确风格迁移的同时,保持了高质量的内容保留。
文本驱动的风格化合成。 所提出的方法支持文本驱动的风格控制,即给定一个文本提示词和一个风格图像,生成具有相似风格的图像。下图6展示了所提出的CSGO与最先进方法的生成结果对比。在简单场景中,很直观地观察到我们的CSGO更遵循文本提示。这是因为得益于内容和风格特征的显式解耦,风格图像仅注入风格信息而不暴露内容。此外,在复杂场景中,得益于精心设计的风格特征注入模块,CSGO在转换文本含义的同时实现了最佳的风格控制。如下图7所示,展示了更多结果。


文本编辑驱动的风格化合成。 所提出的CSGO支持文本编辑驱动的风格控制。如下图8所示,在风格迁移过程中,我们保持原始内容图像的语义和布局,同时允许对文本提示词进行简单编辑。上述优秀结果表明,所提出的CSGO是一个强大的风格控制框架。

消融研究
**内容控制和风格控制。**我们讨论了两种特征注入方法的影响,如下图9所示。内容图像必须通过ControlNet注入以保持布局,同时保留语义信息。如果内容特征仅通过IP-Adapter注入到CSGO框架中(下图9(1)),则内容特征只保留语义信息。

引入ControlNet注入后,内容保留的质量得到了提升,如下图12所示。然而,如果风格特征仅注入到基础UNet中而不通过ControlNet注入,这会削弱生成图像的风格,这可以在上图9(2)和(3)的对比中观察到。因此,所提出的CSGO在ControlNet分支中预先注入风格特征,以进一步融合风格特征,从而增强迁移效果。

风格图像投影层。 风格图像投影层可以有效地从原始embedding中提取风格特征。我们探索了普通线性层和重采样器结构,实验结果如下图10所示。使用重采样器结构能够捕捉到更详细的风格特征,同时避免内容泄露。

Token数量。 探讨了风格投影层中token数量 t t t对风格迁移和文本驱动风格合成结果的影响。实验结果如上图10所示,随着 t t t的增加,风格控制逐渐变得更好。这与我们的预期一致,即 t t t影响特征提取的质量。更大的 t t t意味着投影层能够提取出更丰富的风格特征。

内容尺度 δ c \delta_c δc 的影响。 正如下图13所示,当 δ c \delta_c δc 较小时,内容特征注入较弱,CSGO更遵循文本提示和风格。当 δ c \delta_c δc 增大时,内容保留的质量变得更好。然而,我们注意到,当 δ c \delta_c δc 较大时(例如0.9和1.2),风格信息被严重削弱。

CFG尺度的影响。 无分类器引导增强了文本到图像模型的能力。所提出的CSGO同样受CFG尺度强度的影响。正如上图13所示,引入CFG增强了风格迁移效果。
风格尺度 λ s \lambda_s λs 和内容尺度 λ c \lambda_c λc 的影响。风格尺度影响风格注入的程度。如上图13显示,如果风格尺度小于1.0,生成图像的风格会被严重削弱。我们建议风格尺度应在1.0到1.5之间。下采样块中的内容控制利用内容图像的语义信息来强化内容的准确保留。上图13显示,当 λ c \lambda_c λc 接近1.0时效果最佳。
结论
首先提出了一个用于构建内容-风格-风格化图像三元组的流程。基于此流程,我们构建了第一个大规模风格迁移数据集IMAGStyle,该数据集包含21万个图像三元组,涵盖了广泛的风格场景。为了验证IMAGStyle对风格迁移的影响,我们提出了CSGO,这是一种简单但高度有效的端到端训练风格迁移框架。我们验证了所提出的CSGO可以在统一框架下同时执行图像风格迁移、文本驱动的风格合成和文本编辑驱动的风格合成任务。大量实验验证了IMAGStyle和CSGO对风格迁移的有益效果。我们希望我们的工作能够激励研究社区进一步探索风格化研究。
未来工作。 尽管所提出的数据集和框架已经取得了非常先进的性能,但仍有改进的空间。由于时间和计算资源的限制,我们仅构建了21万个数据三元组。我们相信,通过扩大数据集的规模,CSGO的风格迁移质量将会更好。同时,所提出的CSGO框架是一个基础版本,仅验证了生成风格化数据集对风格迁移的有益效果。我们认为,通过优化风格和内容特征提取及融合方法,可以进一步提高风格迁移的质量。
参考文献
[1] CSGO: Content-Style Composition in Text-to-Image Generation
这篇关于风格控制水平创新高!南理工InstantX小红书发布CSGO:简单高效的端到端风格迁移框架的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






