本文主要是介绍TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks论文阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
由于未修剪的视频占用大量的内存空间,目前SOTA的TAL方法使用了预先处理好的视频特征。这些特征是从视频编码器中提取出来的,它们通常被用于动作分类任务的训练,这使得这些特征不一定适合于时序动作检测。在这项工作中,我们提出了一种新的用于视频片段特征的有监督预训练范式,它不仅训练活动分类活动,还考虑背景剪辑和全局视频信息,以提高时间敏感度。大量的实验表明,使用我们的新的预训练策略训练得到的特征显著提高了最近SOTA方法在三个任务上的性能:时间动作定位、动作建议生成和密集视频字幕。我们还表明,我们的预训练方法在三个编码器架构和两个预训练数据集上是有效的。我们认为视频特征编码是定位算法的重要组成部分,提取时间敏感的特征对于建立更准确的模型至关重要。
Introduction
贡献如下:(I)我们提出了TSP,一个时间敏感的视频编码器有监督预训练任务。TSP训练一个编码器来明确区分未修剪的视频中的前景和背景剪辑。(II)我们通过丰富的实验表明,使用TSP任务预训练的特征显著提高了三个视频定位问题的性能。此外,我们还展示了我们的预训练策略在三个编码器架构和两个预训练数据集上的泛化能力。我们还证明了在同一目标问题上训练的多个定位算法的一致性能增益。(三)我们对我们的特征进行了广泛的分析研究。有趣的是,我们观察到TSP预训练可以提高对短动作实例的时间动作定位性能。该研究还表明,我们的特征实际上是时间敏感的,可以编码不同于前景剪辑的背景剪辑。
Technical Approach
Traditional Pretraining:由于在不大幅降采样空间或时间的情况下,将整个未裁剪的视频送入gpu中进行训练是不切实际的,目前最先进的定位算法有一个共同的做法,即它们不直接在目标任务(例如TAL)上调整视频编码器。相反,他们使用预先训练好的编码器作为固定的特征提取器。修剪动作分类(TAC)是对这些编码器进行预训练的传统方法。TAC任务的目的是对短视频的片段进行分类,其中动作跨越整个视频。虽然TAC已经成功地提供了区分不同动作类的特性,但它通常不能区分动作实例和它附近的背景上下文。例如,最近的研究表明,最先进的TAL方法对动作实例周围的上下文相当敏感,它们无法区分动作及其时间背景上下文是提高本地化性能的主要障碍。我们认为,在这些最先进的定位方法中使用的特性,在TAC上进行了预训练,是这种混淆的一个来源。因此,我们提出背离传统的策略,通过一种新的预训练任务使特征对时间敏感。
How to Incorporate Temporal Sensitivity:TAC预训练的编码器的一个限制方面是,它们只能从正样本(前景/动作剪辑)中学习。直观地说,从负样本(背景/无动作剪辑)中学习有望提高这些编码器的时间辨别能力。给定一个未修剪的视频,一个用于定位问题的很好的编码器应该能够区分不同动作的语义以及动作和它们的背景上下文。直观地说,知道剪辑是在动作内部还是外部的剪辑特性,可以直接帮助本地化方法为TAL和提案找到更好的活动/提案边界。因此,我们建议对编码器进行预训练,用(1)对前景剪辑的标签进行分类,用(2)对剪辑的动作内外进行分类。
Temporally-Sensitive Pretraining:
输入数据:我们使用带有时间注释的未修剪的视频对模型进行预训练。编码器以端到端方式从原始视频输入中学习。特别地,给定一个未修剪的视频,我们采样一个固定大小的输入片段X,大小为3×L×H×W,其中3是RGB通道,L是帧数,H和W是帧的高度和宽度。我们分配X两个标签:如果该剪辑来自前景片段,(1)分配动作类标签yc,(2)还有一个二进制时间区域标签yr,指示该剪辑是否来自视频的前景/动作(=1)或背景/无动作(=0)区域。
本地和全局特征编码:设E是将剪辑X转换为大小为F的特征向量f的视频编码器。我们将f称为局部剪辑特征。假设是未修剪视频的一组剪辑。我们将最大合并特征 f g f^g fg=max(E(Xi))称为全局视频特征(GVF)。如果只给定一个短片段X,分类X是在动作内部还是外部是具有挑战性的。这个挑战源于这样一个事实:我们只能访问本地上下文,而我们希望解决的任务本身就需要对视频内容的全局理解。为了克服这一挑战,我们将GVF与本地片段特征相结合,以更好地学习该任务。
两个分类头:我们使用两个分类头来对编码器进行预训练。具体来说,第一个头(动作标签头)由一个大小为F×C的全连接(FC)层组成,其中C是数据集中动作类的数量。该层将局部特征f转换为一个动作标签的对数向量。第二个头部(时间区域头部)是一个大小为2F×2的FC层,它以局部和全局特征的连接, f f f⊕ f g f^g fg作为输入,以产生一个时间区域对数向量。
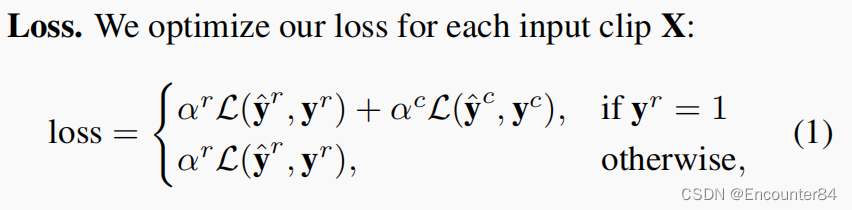
优化细节:时间标注的视频数据集在前景和背景的时间之间存在自然的不平衡。为了减轻这种不平衡,我们以这样一种方式对视频片段进行子样本采样:即对相同数量的前景和背景视频样本进行训练。我们在Kinetics-400数据集上预训练我们的编码器的权重。许多最近的模型已经公开了它们在Kinetics数据集上预训练的权重,我们在我们的实验中使用了这些模型。理想情况下,我们希望通过我们的模型的GVF部分反向传播损失。然而,正如前面提到的,在gpu中处理整个未修剪的视频是不切实际的。因此,我们在训练过程中冻结了GVF,即我们从Kinetics中预训练的初始化编码器中预先计算出每个视频的GVF。
这篇关于TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks论文阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







