pretraining专题
Re72:读论文 XLM Cross-lingual Language Model Pretraining
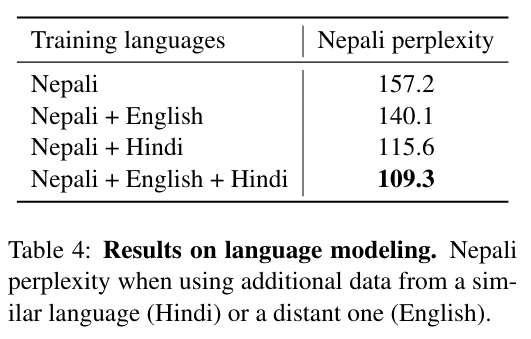
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类 论文名:Cross-lingual Language Model Pretraining 模型简称:XLM ArXiv地址:https://arxiv.org/abs/1901.07291 这是2019年NeurIPS的论文,主要做到就是跨语言BERT。主要创新点就是做了多语言的BERT预训练,改了一下放数据的方式(TLM

【VLP(Visual-Linguistic Pretraining)模型相关基本知识】
VLP(Visual-Linguistic Pretraining)模型相关基本知识 VLP(Visual-Linguistic Pretraining)模型是一种用于视觉与语言联合训练的模型。它旨在通过同时学习视觉和语言任务,从大规模的视觉和语言数据中提取丰富的视觉和语义特征。 VLP模型的发展方向主要包括以下几个方面: 提高模型的视觉理解能力:通过引入更强大的视觉特征提取器、改进的注意力机制
1.Chinese Tiny LLM_ Pretraining a Chinese-Centric Large Language Model
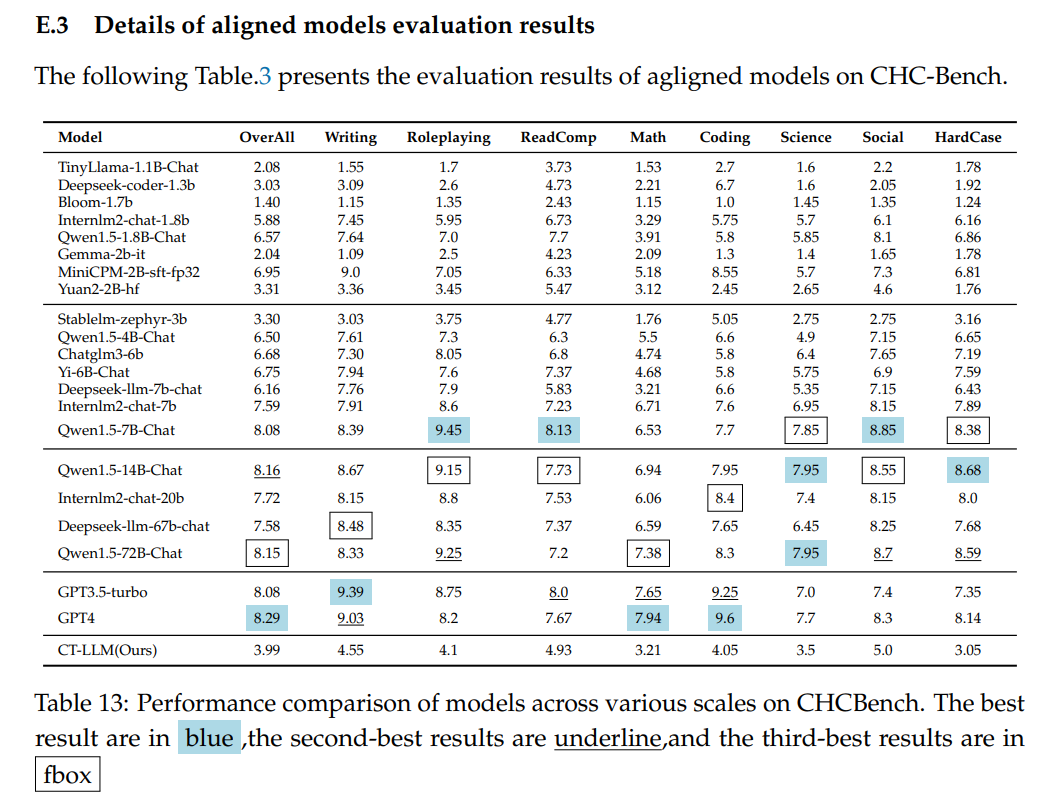
文章目录 摘要一、背景二、预训练数据统计信息数据处理 模型架构 三、SFT四、Learning from Human Preferences五、评估数据集和指标训练过程和比较分析安全性评估中文硬指令理解与遵循评价 六、结论 https://arxiv.org/abs/2404.04167https://github.com/Chinese-Tiny-LLM/Chinese-Tiny

RegionCLIP网络结构解析 Region-based Language-Image Pretraining
1、简单介绍 主要是关注目标检测方面的工作,现在纯CV已经前景黯淡,即使前段时间的YOLOv9发布也是关注一般。 现在大模型已成热点,而大模型要求的数据量和算力和算法复杂度,显然让很多人却步。但是具有大模型特点的多模态算法也算是研究的趋势,所以目前主要是关注多模态方面的目标检测工作。 其中目标检测领域,目前和多模态相关的主要是 开集、开放词汇、描述性目标检测以及情景理解等。相关的研究工作已经越
微调实操一: 增量预训练(Pretraining)
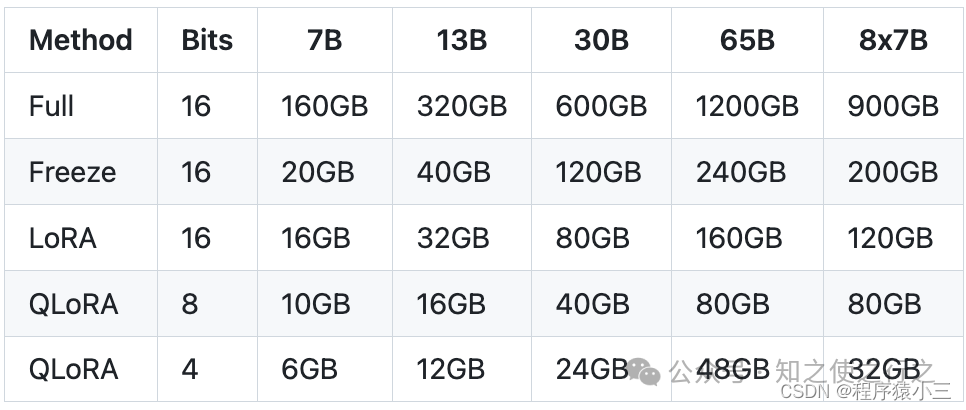
1、前言 《微调入门篇:大模型微调的理论学习》我们对大模型微调理论有了基本了解,这篇结合我们现实中常见的场景,进行大模型微调实操部分的了解和学习,之前我有写过类似的文章《实践篇:大模型微调增量预训练实践(二)》利用的MedicalGPT的源码在colab进行操作, 由于MedicalGPT代码比较难以理解,而且模型只能从hugging face上下载,对于一些国内服务器无法访问,我重构了代码,让
XLNet: 通用自回归预训练语言理解(Generalized Autoregressive Pretraining for Language Understanding)
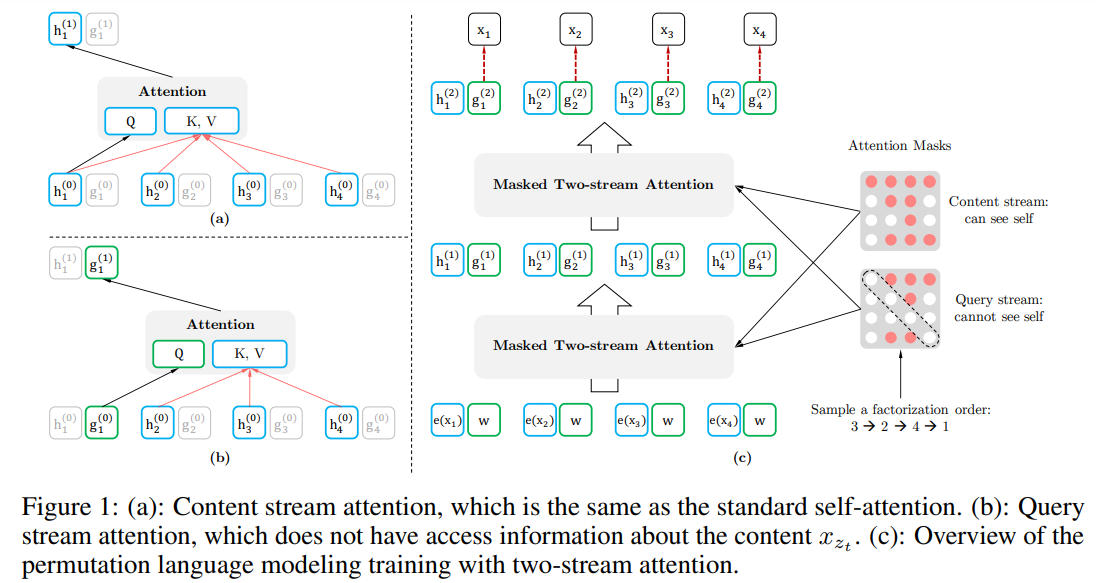
文章目录 引言提出的方法背景目标:排列语言模型结构:基于目标感知的双流注意力融合Transformer-XL多句建模讨论 Reference: 1. XLNet: Generalized Autoregressive Pretraining for Language Understanding 2. XLNet原理解读 引言 AR模型以前向或后向的单向方式建模语言模型

Airbert: In-domain Pretraining for Vision-and-Language Navigation
题目:Airbert:视觉和语言导航的域内预训练 摘要 为了解决VLN数据集稀缺的问题,本文创建了一个数据集BNB。我们首先从在线租赁市场的数十万个列表中收集图像标题 (IC) 对。接下来,我们使用 IC 对提出自动策略来生成数百万个 VLN 路径-指令 (PI) 对。我们进一步提出了一种shuffling loss,可以改善路径-指令对内时间顺序的学习。 我们使用 BnB 来预训练我们的

【三维生成与重建】ZeroRF:Zero Pretraining的快速稀疏视图360°重建
系列文章目录 题目:ZeroRF: Fast Sparse View 360◦ Reconstruction with Zero Pretraining 任务:稀疏重建;拓展:Image to 3D、文本到3D 作者:Ruoxi Shi* Xinyue Wei* Cheng Wang Hao Su ,来自UC San Diego code:https://github.com/eliphatfs
【三维生成与重建】ZeroRF:Zero Pretraining的快速稀疏视图360°重建
系列文章目录 题目:ZeroRF: Fast Sparse View 360◦ Reconstruction with Zero Pretraining 任务:稀疏重建;拓展:Image to 3D、文本到3D 作者:Ruoxi Shi* Xinyue Wei* Cheng Wang Hao Su ,来自UC San Diego code:https://github.com/eliphatfs

UNSUPERVISED PRETRAINING TRANSFERS WELL ACROSS LANGUAGES
UNSUPERVISED PRETRAINING TRANSFERS WELL ACROSS LANGUAGES 1. 论文思路: 作者基于CPC的自监督预训练方法提出了改进版本,解决了原CPC配置中encoder通过batch normalization 泄露信息的问题,并用一层Transformer layer 提升了phoneme 的表征能力。最终得出的主要结论是:通过改进版cpc学习到
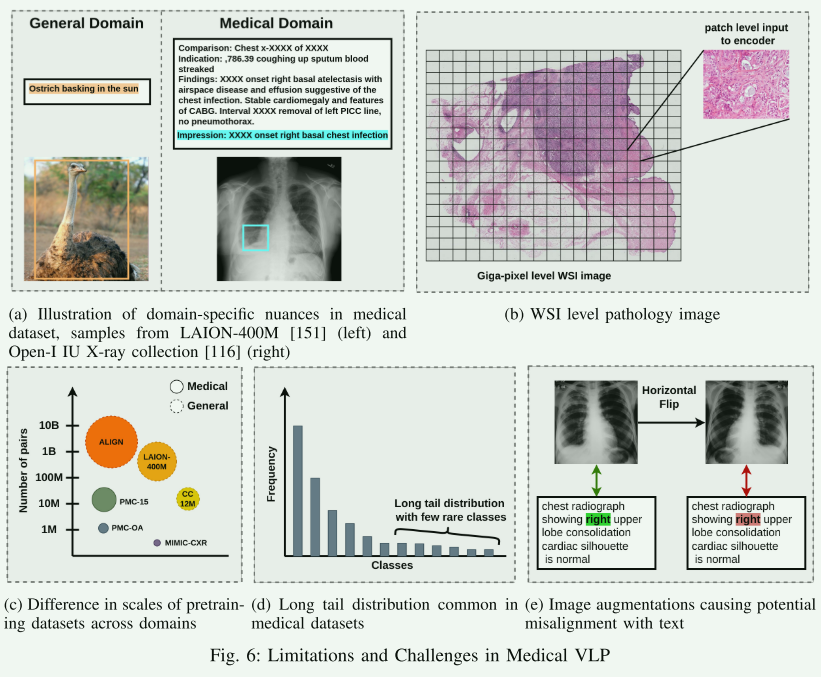
【论文阅读笔记】Medical Vision Language Pretraining: A survey
arXiv:2312.06224Submitted 11 December, 2023; originally announced December 2023. 这篇综述文章很长,本文对各部分简要概述。 【文章整体概述】 医学视觉语言预训练(VLP)最近已经成为解决医学领域标记数据稀缺问题的一种有希望的解决方案。通过利用成对或非成对的视觉和文本数据集进行自监督学习,模型能够获得大量知识并学习
![[RoBERTa]论文实现:RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://img-blog.csdnimg.cn/direct/0784bd8fbe274ebdb0c271aa94984dad.png)
[RoBERTa]论文实现:RoBERTa: A Robustly Optimized BERT Pretraining Approach
文章目录 一、完整代码二、论文解读2.1 模型架构2.2 参数设置2.3 数据2.4 评估 三、对比四、整体总结 论文:RoBERTa:A Robustly Optimized BERT Pretraining Approach 作者:Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen,

GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF 文章目录 GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHFPretraining 预训练阶段Supervised FineTuning (SFT)监督微调阶段Reward Modeling 奖励评价建模Reinforment Learni
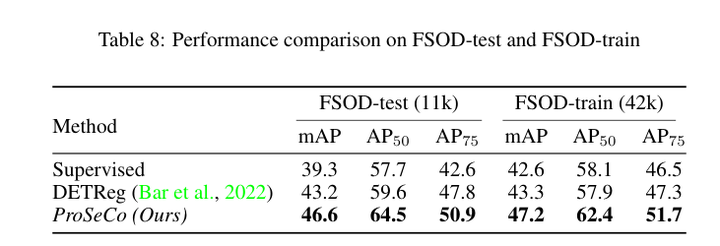
目标检测:Proposal-Contrastive Pretraining for Object Detection from Fewer Data
论文作者:Quentin Bouniot,Romaric Audigier,Angélique Loesch,Amaury Habrard 作者单位:Université Paris-Saclay; Université Jean Monnet Saint-Etienne; Universitaire de France (IUF) 论文链接:http://arxiv.org/ab
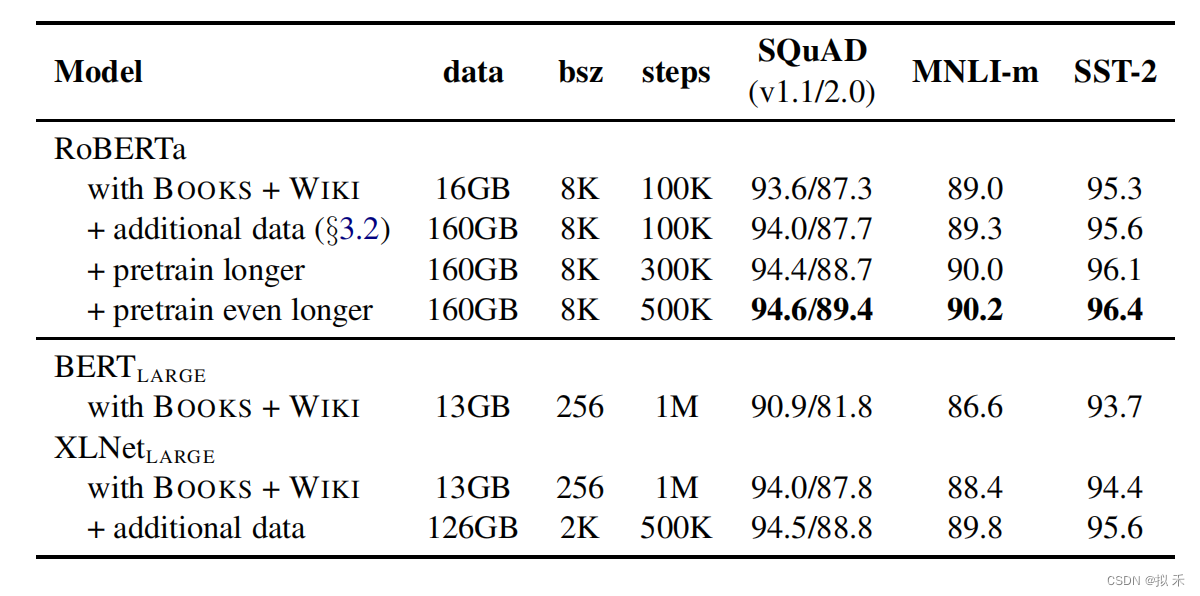
【NLP】 RoBERTa: A Robustly Optimized BERT Pretraining Approach
1. Dynamic Masking🌺 RoBERTa 是对 BERT 的优化提升,改进之一就是在 Masked Language Model (MLM) 任务中,使用 dynamic masking 代替原先的 static masking。 BERT :随机15%的 token 进行 mask,这个过程在数据预处理阶段进行的,而非模型训练阶段。每个样本只会进行一次随机 mask,

微调预训练模型方式的文本语义匹配(Further Pretraining Bert)
微调预训练模型方式的文本语义匹配(Further Pretraining Bert) 今年带着小伙伴参加了天池赛道三: 小布助手对话短文本语义匹配比赛,虽然最后没有杀进B榜,但也是预料之中的结果,最后成绩在110名左右,还算能接受。 言归正传,本文会解说苏剑林(苏神)的Baseline方案和代码,然后会分享我在Baseline上使用的tricks还有我们的方案和实验结果。 干货 Github
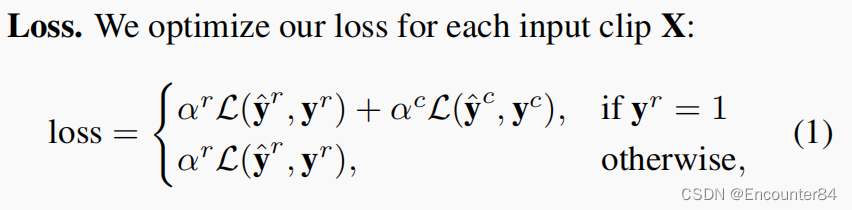
TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks论文阅读笔记
Abstract 由于未修剪的视频占用大量的内存空间,目前SOTA的TAL方法使用了预先处理好的视频特征。这些特征是从视频编码器中提取出来的,它们通常被用于动作分类任务的训练,这使得这些特征不一定适合于时序动作检测。在这项工作中,我们提出了一种新的用于视频片段特征的有监督预训练范式,它不仅训练活动分类活动,还考虑背景剪辑和全局视频信息,以提高时间敏感度。大量的实验表明,使用我们的新的预训练策略训
NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
本文是LLM系列文章,针对《NarrowBERT: Accelerating Masked Language Model Pretraining and Inference》的翻译。 NarrowBERT:加速掩蔽语言模型的预训练和推理 摘要1 引言2 NarrowBERT3 实验4 讨论与结论局限性 摘要 大规模语言模型预训练是自然语言处理中一种非常成功的自监督学习形式,但随着