本文主要是介绍【NLP】 RoBERTa: A Robustly Optimized BERT Pretraining Approach,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. Dynamic Masking🌺
RoBERTa是对BERT的优化提升,改进之一就是在Masked Language Model (MLM)任务中,使用dynamic masking代替原先的static masking。
BERT:随机15%的 token 进行 mask,这个过程在数据预处理阶段进行的,而非模型训练阶段。每个样本只会进行一次随机 mask,每个 epoch 都是相同的。
RoBERTa:复制同一语句10次,对每一句进行随机15%的 token 进行 mask,假设训练40轮,,每个训练 sentence 都有着相同的 mask 四次。当预训练轮数较大或数据量较大时,动态掩码方法能够提高数据的复用效率。
2. Without NSP💐
在原始的
BERT的预训练过程中,会将两个文本片段拼接在一起作为输入,并通过Next Sentence Prediction(NSP)任务预测这两段文本是否构成“下一个句子”关系。
在论文中,作者对比了4组实验结果,发现去掉 NSP,实验结果反而更好。
3. 更多的预训练数据集🍀
在
RoBERTa中,进一步将预训练数据的规模扩展至160GB,是BERT的10倍。
4. 更大的 Batch Size 及更多的 Steps🍂
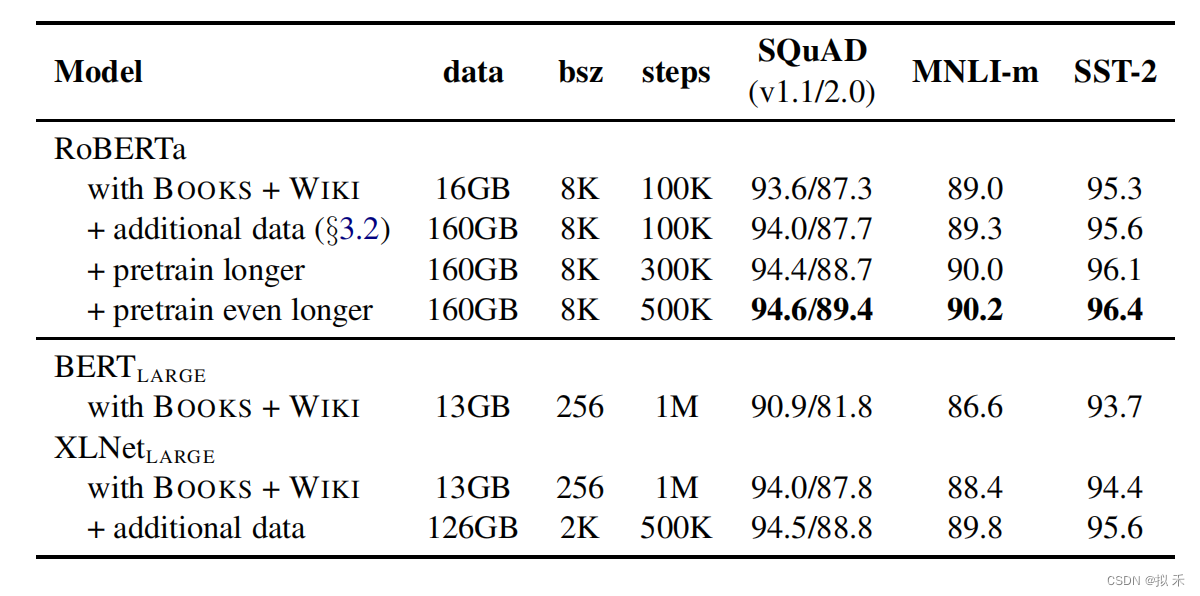
RoBERTa采用了8K的批次大小,并且进一步将训练步长加大至500K,使用更大的批次能够有效减少训练时长,当固定批次大小并增加训练步数后,也能得到更好的实验结果,如下图所示。
5. 更大的词表🌼
RoBERTa采用了更大的词表,使用 byte-level BPE(BPE: Byte Pair Encoding)作为 tokenizer。RoBERTa的词表大小是 50265,比BERT的 30522 更大。这是为了更好地处理英语语言的多样性和复杂性。
byte-level BPE则是一种 subword tokenization 方法,通过将单词切分成较小的子单元来帮助模型更好地理解单词。与传统的 BPE 不同,byte-level BPE 考虑了字符级别的信息,因此可以更好地处理一些语言中常见的字符序列,例如单词内部的连字符或下划线等。
在原始BERT中,采用一个30K大小的 WordPiece 词表。这种词表的一个弊端是,如果输入文本无法通过词表中的 WordPiece 子词进行拼接组合,则会映射到 “unknown” 这种未登录词标识。
RoBERTa采用 SentencePiece 这种字节级别 byte-level 的 BPE 词表的好处是能够编码任意输入文本,因此不会出现未登录词的情况。
这篇关于【NLP】 RoBERTa: A Robustly Optimized BERT Pretraining Approach的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





