roberta专题


优化RoBERTa:在AMD上使用混合精度进行微调
Optimizing RoBERTa: Fine-Tuning with Mixed Precision on AMD — ROCm Blogs 简介 在这篇博客中,我们将探讨如何微调鲁棒优化的BERT预训练方法([RoBERTa](https://arxiv.org/abs/1907.11692))大型语言模型,重点在于PyTorch的混合精度功能。具体来说,我们将利用AMD GPU进行混合

XLM-RoBERTa 是一种多语言版本的 RoBERTa 模型
XLM-RoBERTa 是一种多语言版本的 RoBERTa 模型,由 Facebook AI 开发。它是为了处理多种语言的自然语言理解任务而设计的。 XLM-RoBERTa 的主要特性: 多语言能力:在使用 CommonCrawl 数据集的 100 种语言上进行训练,XLM-RoBERTa 可以在多种语言上表现出色,而不需要为每种语言单独训练模型。大规模预训练:该模型在大型多样化语料库上进行预
自然语言处理实战项目28-RoBERTa模型在BERT的基础上的改进与架构说明,RoBERTa模型的搭建
大家好,我是微学AI,今天给大家介绍下自然语言处理实战项目28-RoBERTa模型在BERT的基础上的改进与架构说明,RoBERTa模型的搭建。在BERT的基础上,RoBERTa进行了深度优化和改进,使其在多项NLP任务中取得了卓越的成绩。接下来,我们将详细了解RoBERTa的原理、架构以及它在BERT基础上的改进之处,并通过实战项目来演示如何搭建RoBERTa模型。让我们开始学习-RoBERTa

第12章:NLP比赛的明星模型RoBERTa架构剖析及完整源码实现
1,为什么说BERT模型本身的训练是不充分甚至是不科学的? 2,RoBERTa去掉NSP任务的数学原理分析 3,抛弃了token_type_ids的RoBERTa 4,更大的mini-batches在面对海量的数据训练时是有效的数学原理解析 5,为何更大的Learning rates在大规模数据上会更有效? 6,由RoBERTa对hyperparameters调优的数学依据 7,RoB

NLP-预训练模型:迁移学习(拿已经训练好的模型来使用)【预训练模型:BERT、GPT、Transformer-XL、XLNet、RoBerta、XLM、T5】、微调、微调脚本、【GLUE数据集】
深度学习-自然语言处理:迁移学习(拿已经训练好的模型来使用)【GLUE数据集、预训练模型(BERT、GPT、transformer-XL、XLNet、T5)、微调、微调脚本】 一、迁移学习概述二、NLP中的标准数据集1、GLUE数据集合的下载方式2、GLUE子数据集的样式及其任务类型2.1 CoLA数据集【判断句子语法是否正确】2.2 SST-2数据集【情感分类】2.3 MRPC数据集【判断
大型语言模型:RoBERTa — 一种稳健优化的 BERT 方法
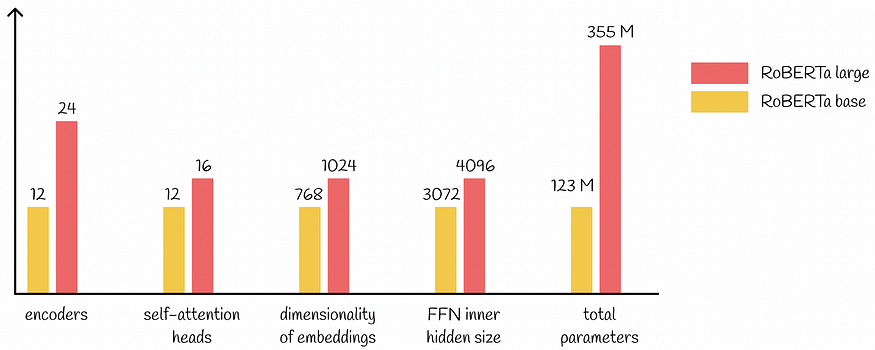
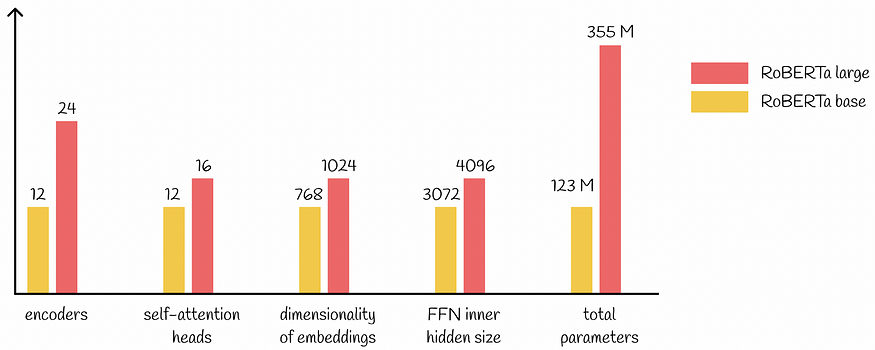
@slavahead 一、介绍 BERT模型的出现BERT模型带来了NLP的重大进展。 BERT 的架构源自 Transformer,它在各种下游任务上取得了最先进的结果:语言建模、下一句预测、问答、NER标记等。 尽管 BERT 性能出色,研究人员仍在继续尝试其配置,希望获得更好的指标。幸运的是,他们成功了,并提出了一种名为 RoBERTa
![[RoBERTa]论文实现:RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://img-blog.csdnimg.cn/direct/0784bd8fbe274ebdb0c271aa94984dad.png)
[RoBERTa]论文实现:RoBERTa: A Robustly Optimized BERT Pretraining Approach
文章目录 一、完整代码二、论文解读2.1 模型架构2.2 参数设置2.3 数据2.4 评估 三、对比四、整体总结 论文:RoBERTa:A Robustly Optimized BERT Pretraining Approach 作者:Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen,
【原理】预训练模型之自然语言理解--RoBERTa
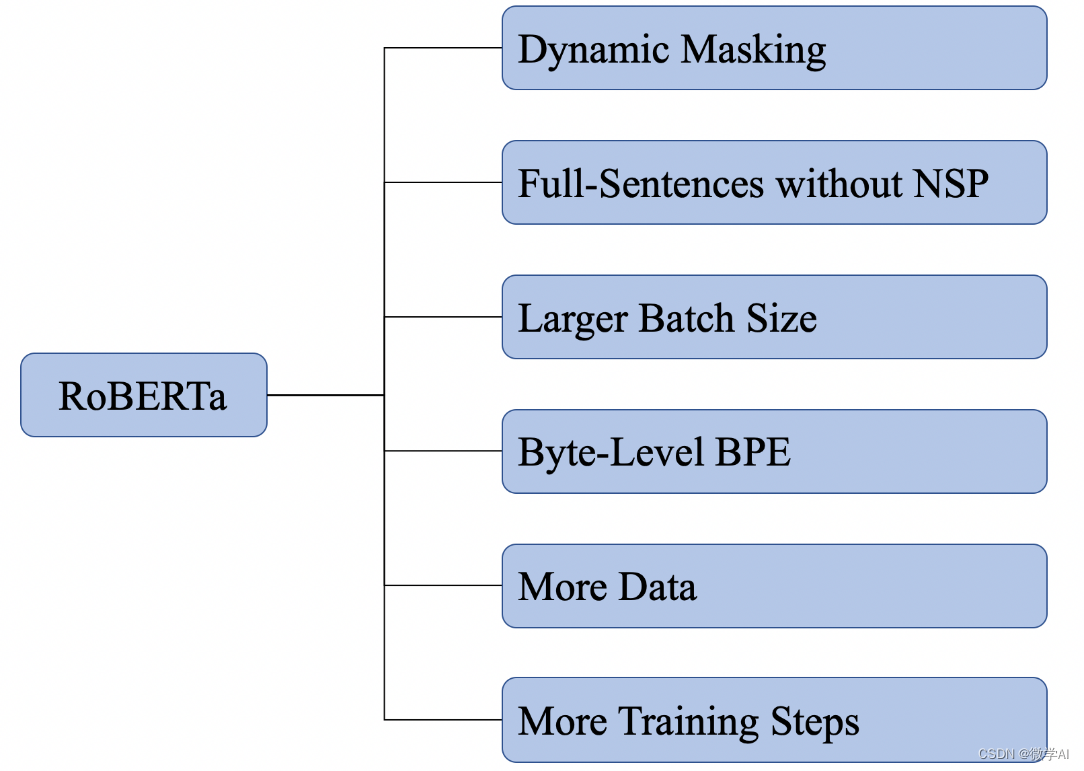
RoBERTa: A Robustly Optimized BERT Pretraining Approach 从模型结构上讲,相比BERT,RoBERTa基本没有什么创新,它更像是关于BERT在预训练方面进一步的探索。其改进了BERT很多的预训练策略,其结果显示,原始BERT可能训练不足,并没有充分地学习到训练数据中的语言知识。 图1展示了RoBERTa主要探索的几个方面,并这些方面进行融合
大型语言模型:RoBERTa — 一种鲁棒优化的 BERT 方法
一、介绍 BERT模型的出现导致了NLP的重大进展。BERT的架构源自Transformer,在各种下游任务上实现了最先进的结果:语言建模,下一句预测,问答,NER标记等。 大型语言模型:BERT — 来自变压器的双向编码器表示 了解BERT如何构建最先进的嵌入 towardsdatascience.com 尽管B
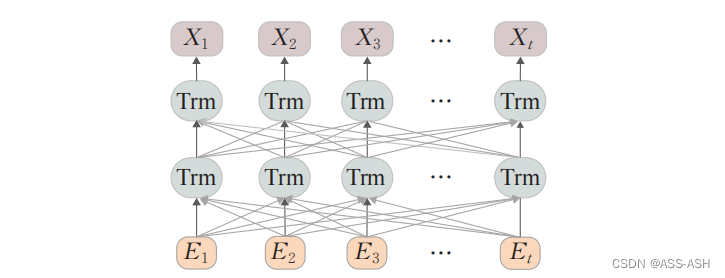
RoBERTa极简简介
RoBERTa模型是在BERT预训练模型的基础上改进了三点: 一、采用动态Masking机制,每次向模型输入一个序列时,都会生成一种新的遮盖方式 二、删除了Next Sentence Prediction(NSP)任务 三、增加了预训练过程的预料规模,扩大Batch Size的同时增加了训练时的步长 与BERT模型一致,RoBERTa模型同样使用多个双向Tra

NLP(五十四)在Keras中使用英文Roberta模型实现文本分类
英文Roberta模型是2019年Facebook在论文RoBERTa: A Robustly Optimized BERT Pretraining Approach中新提出的预训练模型,其目的是改进BERT模型存在的一些问题,当时也刷新了一众NLP任务的榜单,达到SOTA效果,其模型和代码已开源,放在Github中的fairseq项目中。众所周知,英文Roberta模型使用Torch框架训练
【深度学习】BERT变体—RoBERTa
RoBERTa是的BERT的常用变体,出自Facebook的RoBERTa: A Robustly Optimized BERT Pretraining Approach。来自Facebook的作者根据BERT训练不足的缺点提出了更有效的预训练方法,并发布了具有更强鲁棒性的BERT:RoBERTa。 RoBERTa通过以下四个方面改变来改善BERT的预训练

BERT和ALBERT的区别;BERT和RoBERTa的区别;与bert相关的模型总结
一.BERT和ALBERT的区别: BERT和ALBERT都是基于Transformer的预训练模型,它们的几个主要区别如下: 模型大小:BERT模型比较大,参数多,计算资源消耗较大;而ALBERT通过技术改进,显著减少了模型的大小,降低了计算资源消耗。 参数共享:ALBERT引入了跨层参数共享机制,即在整个模型的所有层中,隐藏层的参数是共享的,也就是说每一层都使用相同的参数。相比之下,B
论文阅读——RoBERTa
一、LM效果好但是各种方法之间细致比较有挑战性,因为训练耗费资源多、并且在私有的不同大小的数据集上训练,不同超参数选择对结果影响很大。使用复制研究的方法对BERT预训练的超参数和数据集的影响细致研究,发现BERT训练不够,提出训练BERT的方法RoBERTa。 RoBERTa方法: 1、训练更长时间、数据集更大 2、移除NSP任务 3、在更长的序列上训练:We train only wit
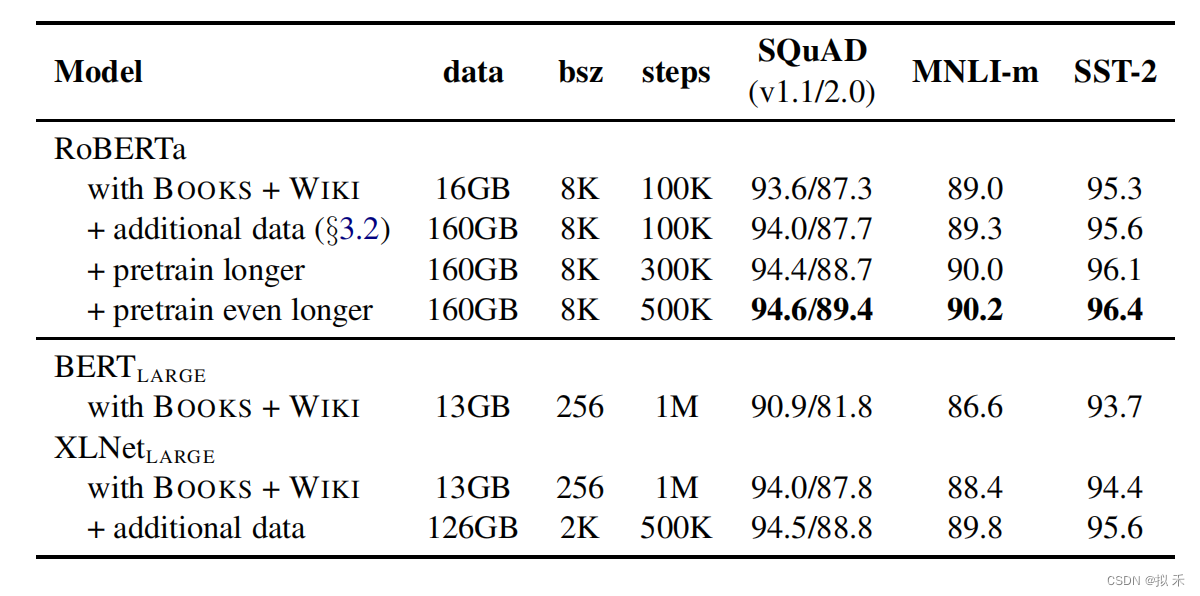
【NLP】 RoBERTa: A Robustly Optimized BERT Pretraining Approach
1. Dynamic Masking🌺 RoBERTa 是对 BERT 的优化提升,改进之一就是在 Masked Language Model (MLM) 任务中,使用 dynamic masking 代替原先的 static masking。 BERT :随机15%的 token 进行 mask,这个过程在数据预处理阶段进行的,而非模型训练阶段。每个样本只会进行一次随机 mask,

【Deep Learning A情感文本分类实战】2023 Pytorch+Bert、Roberta+TextCNN、BiLstm、Lstm等实现IMDB情感文本分类完整项目(项目已开源)
🍊作者最近在看了大量论文的源代码后,被它们干净利索的代码风格深深吸引,因此也想做一个结构比较规范而且内容较为经典的任务 🍊本项目使用Pytorch框架,使用上游语言模型+下游网络模型的结构实现IMDB情感分析 🍊语言模型可选择Bert、Roberta 🍊主神经网络模型可选择BiLstm、LSTM、TextCNN、Rnn、Gru、FNN、Attention共7种 🍊语言模型
BERT变体(1):ALBERT、RoBERTa、ELECTRA、SpanBERT
Author:龙箬 Computer Application Technology Change the World with Data and Artificial Intelligence ! CSDN@weixin_43975035 *天下之大,虽离家万里,何处不可往!何事不可为! 1. ALBERT \qquad ALBERT的英文全称为A Lite version of BE
基于 chinese-roberta-wwm-ext 微调训练中文命名实体识别任务
一、模型和数据集介绍 1.1 预训练模型 chinese-roberta-wwm-ext 是基于 RoBERTa 架构下开发,其中 wwm 代表 Whole Word Masking,即对整个词进行掩码处理,通过这种方式,模型能够更好地理解上下文和语义关联,提高中文文本处理的准确性和效果。 与原始的 BERT 模型相比,chinese-roberta-wwm-ext 在训练数据规模和训练步数
基于 chinese-roberta-wwm-ext 微调训练中文命名实体识别任务
一、模型和数据集介绍 1.1 预训练模型 chinese-roberta-wwm-ext 是基于 RoBERTa 架构下开发,其中 wwm 代表 Whole Word Masking,即对整个词进行掩码处理,通过这种方式,模型能够更好地理解上下文和语义关联,提高中文文本处理的准确性和效果。 与原始的 BERT 模型相比,chinese-roberta-wwm-ext 在训练数据规模和训练步数
大型语言模型:RoBERTa — 一种鲁棒优化的 BERT 方法
一、介绍 BERT模型的出现导致了NLP的重大进展。BERT的架构源自Transformer,在各种下游任务上实现了最先进的结果:语言建模,下一句预测,问答,NER标记等。 大型语言模型:BERT — 来自变压器的双向编码器表示 了解BERT如何构建最先进的嵌入 towardsdatascience.com 尽管B