本文主要是介绍基于 chinese-roberta-wwm-ext 微调训练中文命名实体识别任务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、模型和数据集介绍
1.1 预训练模型
chinese-roberta-wwm-ext 是基于 RoBERTa 架构下开发,其中 wwm 代表 Whole Word Masking,即对整个词进行掩码处理,通过这种方式,模型能够更好地理解上下文和语义关联,提高中文文本处理的准确性和效果。
与原始的 BERT 模型相比,chinese-roberta-wwm-ext 在训练数据规模和训练步数上做了一些调整,以进一步提升模型的性能和鲁棒性。并且在大规模无监督语料库上进行了预训练,使其具备强大的语言理解和生成能力。它能够广泛应用于各种自然语言处理任务,如文本分类、命名实体识别、情感分析等。我们可以使用这个模型作为基础,在不同的任务上进行微调和迁移学习,以实现更准确、高效的中文文本处理。
huggingface地址:https://huggingface.co/hfl/chinese-roberta-wwm-ext
进到 huggingface 中下载预训练模型:
1.2 数据集
数据集采用 CLUENER(中文语言理解测评基准)2020数据集
进入下面链接下载数据集:
https://www.cluebenchmarks.com/introduce.html
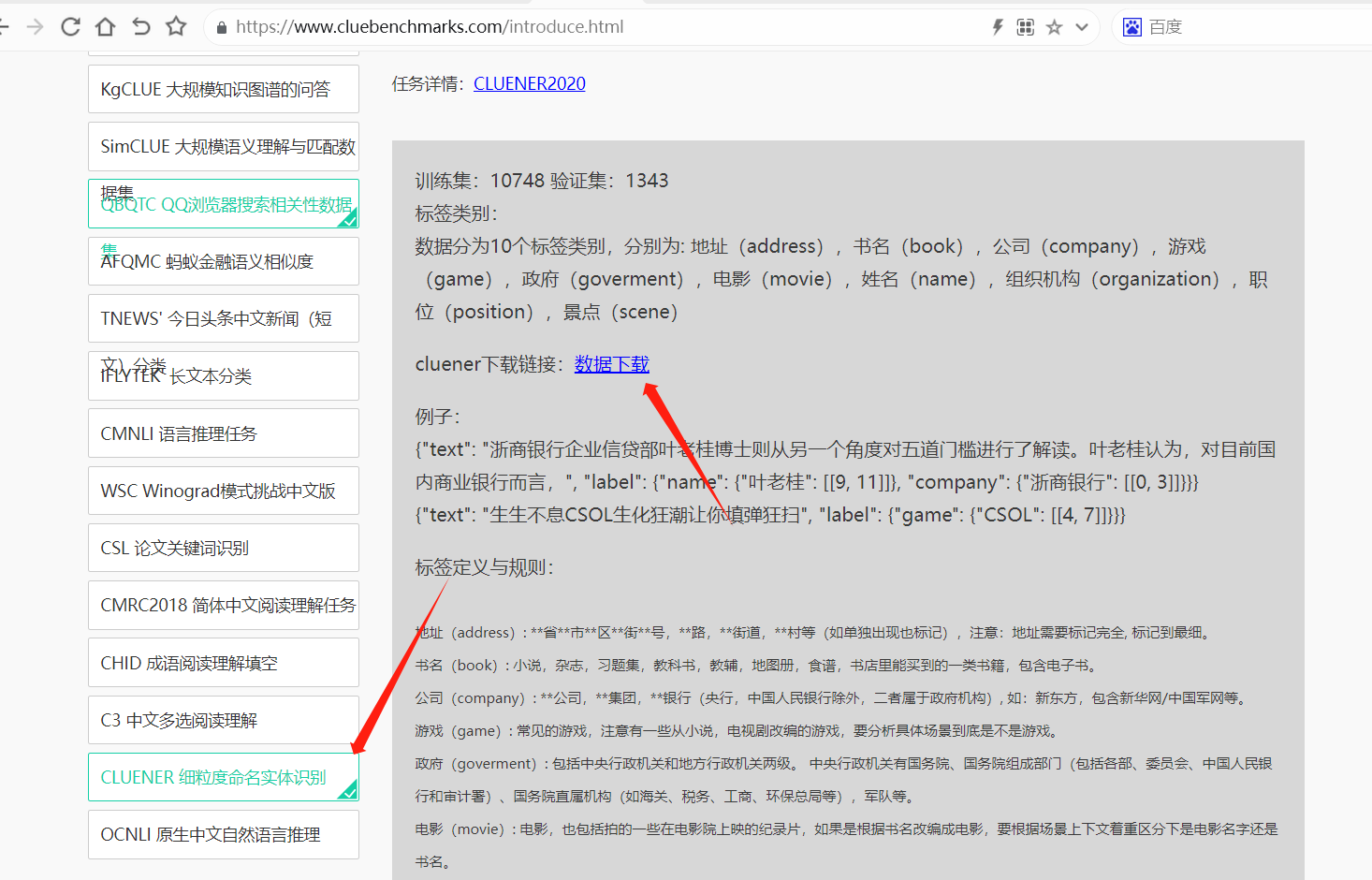
数据分为10个标签类别,分别为: 地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)
数据实例如下:
{"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,", "label": {"name": {"叶老桂": [[9, 11]]}, "company": {"浙商银行": [[0, 3]]}}}
{"text": "生生不息CSOL生化狂潮让你填弹狂扫", "label": {"game": {"CSOL": [[4, 7]]}}}
{"text": "那不勒斯vs锡耶纳以及桑普vs热那亚之上呢?", "label": {"organization": {"那不勒斯": [[0, 3]], "锡耶纳": [[6, 8]], "桑普": [[11, 12]], "热那亚": [[15, 17]]}}}
{"text": "加勒比海盗3:世界尽头》的去年同期成绩死死甩在身后,后者则即将赶超《变形金刚》,", "label": {"movie": {"加勒比海盗3:世界尽头》": [[0, 11]], "《变形金刚》": [[33, 38]]}}}
{"text": "布鲁京斯研究所桑顿中国中心研究部主任李成说,东亚的和平与安全,是美国的“核心利益”之一。", "label": {"address": {"美国": [[32, 33]]}, "organization": {"布鲁京斯研究所桑顿中国中心": [[0, 12]]}, "name": {"李成": [[18, 19]]}, "position": {"研究部主任": [[13, 17]]}}}
{"text": "目前主赞助商暂时空缺,他们的球衣上印的是“unicef”(联合国儿童基金会),是公益性质的广告;", "label": {"organization": {"unicef": [[21, 26]], "联合国儿童基金会": [[29, 36]]}}}
{"text": "此数据换算成亚洲盘罗马客场可让平半低水。", "label": {"organization": {"罗马": [[9, 10]]}}}
{"text": "你们是最棒的!#英雄联盟d学sanchez创作的原声王", "label": {"game": {"英雄联盟": [[8, 11]]}}}
{"text": "除了吴湖帆时现精彩,吴待秋、吴子深、冯超然已然归入二三流了,", "label": {"name": {"吴湖帆": [[2, 4]], "吴待秋": [[10, 12]], "吴子深": [[14, 16]], "冯超然": [[18, 20]]}}}
{"text": "在豪门被多线作战拖累时,正是他们悄悄追赶上来的大好时机。重新找回全队的凝聚力是拉科赢球的资本。", "label": {"organization": {"拉科": [[39, 40]]}}}
首先将数据集转换成 BIO 标注格式:
import json# 将数据转为 BIO 标注形式
def dimension_label(path, save_path, labels_path=None):label_dict = ['O']with open(save_path, "a", encoding="utf-8") as w:with open(path, "r", encoding="utf-8") as r:for line in r:line = json.loads(line)text = line['text']label = line['label']text_label = ['O'] * len(text)for label_key in label: # 遍历实体标签B_label = "B-" + label_keyI_label = "I-" + label_keyif B_label not in label_dict:label_dict.append(B_label)if I_label not in label_dict:label_dict.append(I_label)label_item = label[label_key]for entity in label_item: # 遍历实体position = label_item[entity]start = position[0][0]end = position[0][1]text_label[start] = B_labelfor i in range(start + 1, end + 1):text_label[i] = I_labelline = {"text": text,"label": text_label}line = json.dumps(line, ensure_ascii=False)w.write(line + "\n")w.flush()if labels_path: # 保存 label ,后续训练和预测时使用label_map = {}for i,label in enumerate(label_dict):label_map[label] = iwith open(labels_path, "w", encoding="utf-8") as w:labels = json.dumps(label_map, ensure_ascii=False)w.write(labels + "\n")w.flush()if __name__ == '__main__':path = "./cluener_public/dev.json"save_path = "./data/dev.json"dimension_label(path, save_path)path = "./cluener_public/train.json"save_path = "./data/train.json"labels_path = "./data/labels.json"dimension_label(path, save_path, labels_path)转换后的格式如下所示:
{"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,", "label": ["B-company", "I-company", "I-company", "I-company", "O", "O", "O", "O", "O", "B-name", "I-name", "I-name", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
{"text": "生生不息CSOL生化狂潮让你填弹狂扫", "label": ["O", "O", "O", "O", "B-game", "I-game", "I-game", "I-game", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
{"text": "那不勒斯vs锡耶纳以及桑普vs热那亚之上呢?", "label": ["B-organization", "I-organization", "I-organization", "I-organization", "O", "O", "B-organization", "I-organization", "I-organization", "O", "O", "B-organization", "I-organization", "O", "O", "B-organization", "I-organization", "I-organization", "O", "O", "O", "O"]}
{"text": "加勒比海盗3:世界尽头》的去年同期成绩死死甩在身后,后者则即将赶超《变形金刚》,", "label": ["B-movie", "I-movie", "I-movie", "I-movie", "I-movie", "I-movie", "I-movie", "I-movie", "I-movie", "I-movie", "I-movie", "I-movie", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-movie", "I-movie", "I-movie", "I-movie", "I-movie", "I-movie", "O"]}
{"text": "布鲁京斯研究所桑顿中国中心研究部主任李成说,东亚的和平与安全,是美国的“核心利益”之一。", "label": ["B-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "B-position", "I-position", "I-position", "I-position", "I-position", "B-name", "I-name", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-address", "I-address", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
{"text": "目前主赞助商暂时空缺,他们的球衣上印的是“unicef”(联合国儿童基金会),是公益性质的广告;", "label": ["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "O", "O", "B-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "I-organization", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
{"text": "此数据换算成亚洲盘罗马客场可让平半低水。", "label": ["O", "O", "O", "O", "O", "O", "O", "O", "O", "B-organization", "I-organization", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
{"text": "你们是最棒的!#英雄联盟d学sanchez创作的原声王", "label": ["O", "O", "O", "O", "O", "O", "O", "O", "B-game", "I-game", "I-game", "I-game", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
{"text": "除了吴湖帆时现精彩,吴待秋、吴子深、冯超然已然归入二三流了,", "label": ["O", "O", "B-name", "I-name", "I-name", "O", "O", "O", "O", "O", "B-name", "I-name", "I-name", "O", "B-name", "I-name", "I-name", "O", "B-name", "I-name", "I-name", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
{"text": "在豪门被多线作战拖累时,正是他们悄悄追赶上来的大好时机。重新找回全队的凝聚力是拉科赢球的资本。", "label": ["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-organization", "I-organization", "O", "O", "O", "O", "O", "O"]}
labels.json 标签如下:
{"O": 0, "B-name": 1, "I-name": 2, "B-company": 3, "I-company": 4, "B-game": 5, "I-game": 6, "B-organization": 7, "I-organization": 8, "B-movie": 9, "I-movie": 10, "B-address": 11, "I-address": 12, "B-position": 13, "I-position": 14, "B-government": 15, "I-government": 16, "B-scene": 17, "I-scene": 18, "B-book": 19, "I-book": 20}
二、模型微调训练
2.1 处理数据集构建 Dataset
ner_datasets.py
from torch.utils.data import Dataset, DataLoader
import torch
import jsonclass NERDataset(Dataset):def __init__(self, tokenizer, file_path, labels_map, max_length=300):self.tokenizer = tokenizerself.max_length = max_lengthself.labels_map = labels_mapself.text_data = []self.label_data = []with open(file_path, "r", encoding="utf-8") as r:for line in r:line = json.loads(line)text = line['text']label = line['label']self.text_data.append(text)self.label_data.append(label)def __len__(self):return len(self.text_data)def __getitem__(self, idx):text = self.text_data[idx]labels = self.label_data[idx]# 使用分词器对句子进行处理inputs = self.tokenizer.encode_plus(text,None,add_special_tokens=True,padding='max_length',truncation=True,max_length=self.max_length,return_tensors='pt')input_ids = inputs['input_ids'].squeeze()attention_mask = inputs['attention_mask'].squeeze()# 将标签转换为数字编码label_ids = [self.labels_map[l] for l in labels]if len(label_ids) > self.max_length:label_ids = label_ids[0:self.max_length]if len(label_ids) < self.max_length:# 标签填充到最大长度label_ids.extend([0] * (self.max_length - len(label_ids)))return {'input_ids': input_ids,'attention_mask': attention_mask,'labels': torch.LongTensor(label_ids)}2.2 模型迭代训练
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import AutoTokenizer, AutoModelForTokenClassification
from ner_datasets import NERDataset
from tqdm import tqdm
import json
import time, sys
import numpy as np
from sklearn.metrics import f1_scoredef train(epoch, model, device, loader, optimizer, gradient_accumulation_steps):model.train()time1 = time.time()for index, data in enumerate(tqdm(loader, file=sys.stdout, desc="Train Epoch: " + str(epoch))):input_ids = data['input_ids'].to(device)attention_mask = data['attention_mask'].to(device)labels = data['labels'].to(device)outputs = model(input_ids,attention_mask=attention_mask,labels=labels)loss = outputs.loss# 反向传播,计算当前梯度loss.backward()# 梯度累积步数if (index % gradient_accumulation_steps == 0 and index != 0) or index == len(loader) - 1:# 更新网络参数optimizer.step()# 清空过往梯度optimizer.zero_grad()# 100轮打印一次 lossif index % 100 == 0 or index == len(loader) - 1:time2 = time.time()tqdm.write(f"{index}, epoch: {epoch} -loss: {str(loss)} ; each step's time spent: {(str(float(time2 - time1) / float(index + 0.0001)))}")def validate(model, device, loader):model.eval()acc = 0f1 = 0with torch.no_grad():for _, data in enumerate(tqdm(loader, file=sys.stdout, desc="Validation Data")):input_ids = data['input_ids'].to(device)attention_mask = data['attention_mask'].to(device)labels = data['labels']outputs = model(input_ids, attention_mask=attention_mask)_, predicted_labels = torch.max(outputs.logits, dim=2)predicted_labels = predicted_labels.detach().cpu().numpy().tolist()true_labels = labels.detach().cpu().numpy().tolist()predicted_labels_flat = [label for sublist in predicted_labels for label in sublist]true_labels_flat = [label for sublist in true_labels for label in sublist]accuracy = (np.array(predicted_labels_flat) == np.array(true_labels_flat)).mean()acc = acc + accuracyf1score = f1_score(true_labels_flat, predicted_labels_flat, average='macro')f1 = f1 + f1scorereturn acc / len(loader), f1 / len(loader)def main():labels_path = "./data/labels.json"model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext'train_json_path = "./data/train.json"val_json_path = "./data/dev.json"max_length = 300epochs = 5batch_size = 1lr = 1e-4gradient_accumulation_steps = 16model_output_dir = "output"device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载labelwith open(labels_path, "r", encoding="utf-8") as r:labels_map = json.loads(r.read())# 加载分词器和模型tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForTokenClassification.from_pretrained(model_name, num_labels=len(labels_map))model.to(device)# 加载数据print("Start Load Train Data...")train_dataset = NERDataset(tokenizer, train_json_path, labels_map, max_length)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)print("Start Load Validation Data...")val_dataset = NERDataset(tokenizer, val_json_path, labels_map, max_length)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)# 定义优化器和损失函数optimizer = torch.optim.AdamW(model.parameters(), lr=lr)print("Start Training...")best_acc = 0.0for epoch in range(epochs):train(epoch, model, device, train_loader, optimizer, gradient_accumulation_steps)print("Start Validation...")acc, f1 = validate(model, device, val_loader)print(f"Validation : acc: {acc} , f1: {f1}")if best_acc < acc: # 保存准确率最高的模型print("Save Model To ", model_output_dir)model.save_pretrained(model_output_dir)tokenizer.save_pretrained(model_output_dir)best_acc = accif __name__ == '__main__':main()运行之后可以看到训练进度:
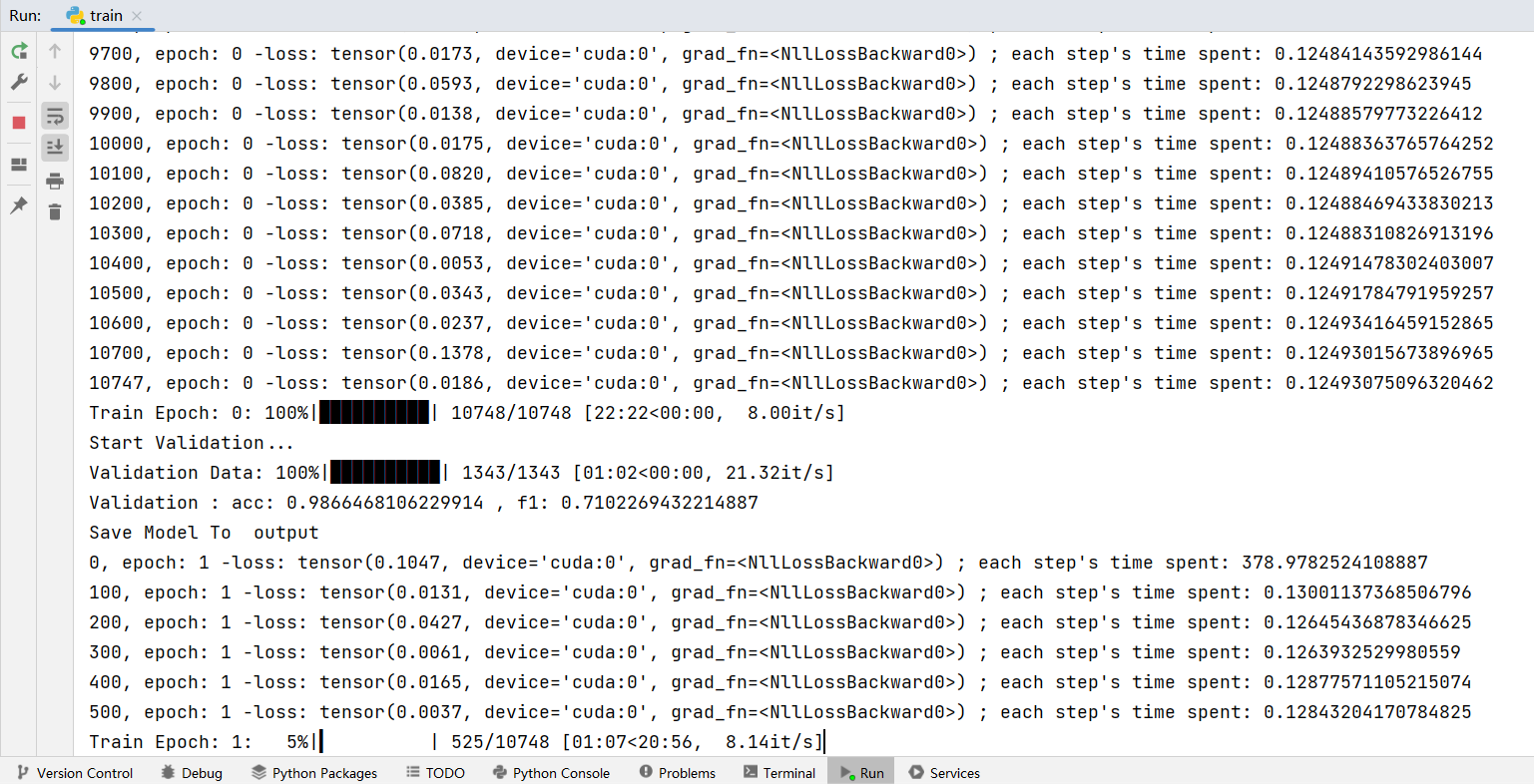
训练中可以看到验证集的准确率和f1 指标,并保存一个准确率最高的模型。
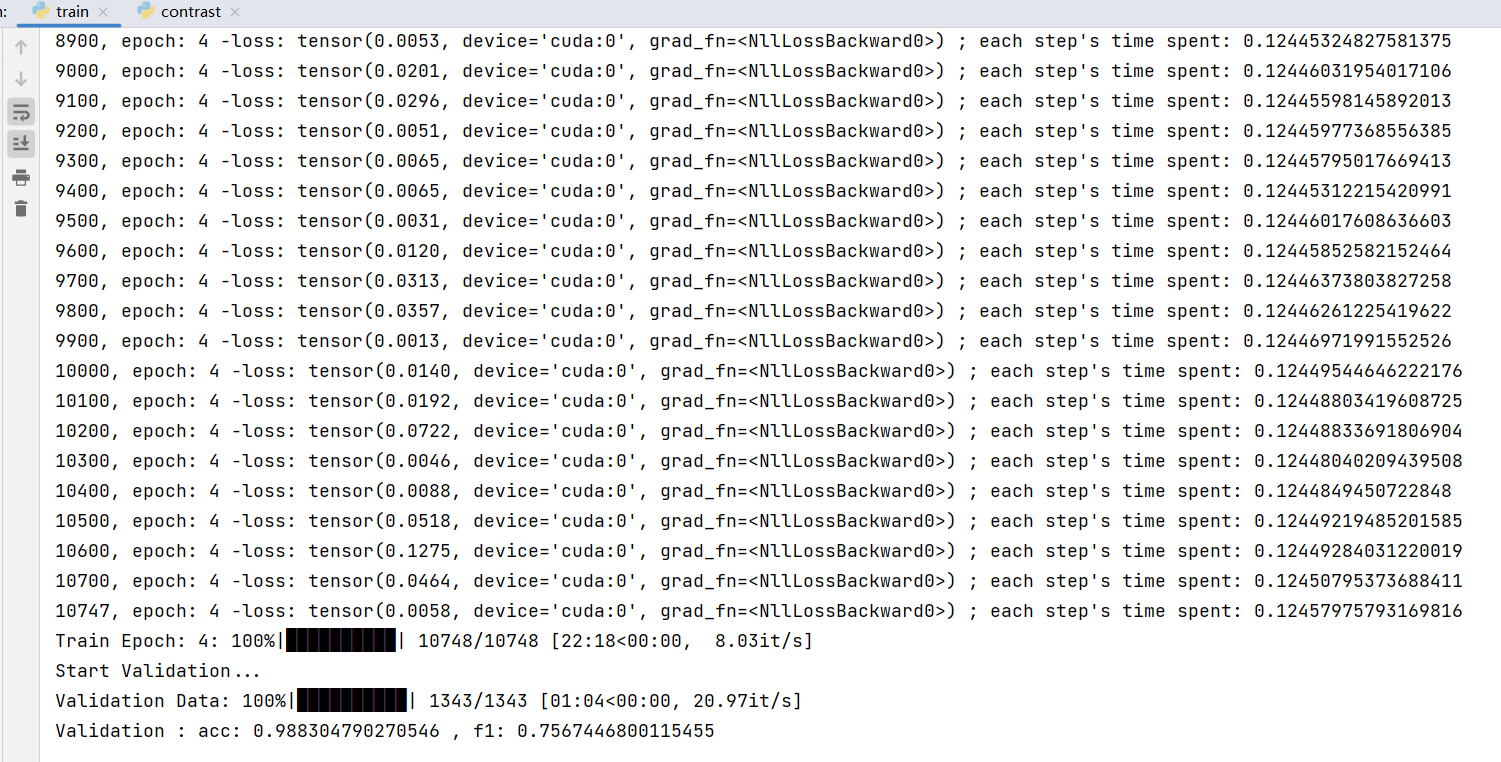
训练完成后,可以看到最后一轮的 acc: 0.988304790270546 , f1: 0.7567446800115455,在 output 下可以看到保存的模型文件:
三、模型测试
from transformers import AutoTokenizer, AutoModelForTokenClassification
import torch
import json# 解析实体
def post_processing(outputs, text, labels_map):_, predicted_labels = torch.max(outputs.logits, dim=2)predicted_labels = predicted_labels.detach().cpu().numpy()predicted_tags = [labels_map[label_id] for label_id in predicted_labels[0]]result = {}entity = ""type = ""for index, word_token in enumerate(text):tag = predicted_tags[index]if tag.startswith("B-"):type = tag.split("-")[1]if entity:if type not in result:result[type] = []result[type].append(entity)entity = word_tokenelif tag.startswith("I-"):type = tag.split("-")[1]if entity:entity += word_tokenelse:if entity:if type not in result:result[type] = []result[type].append(entity)entity = ""return resultdef main():labels_path = "./data/labels.json"model_name = './output'max_length = 300device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载labellabels_map = {}with open(labels_path, "r", encoding="utf-8") as r:labels = json.loads(r.read())for label in labels:label_id = labels[label]labels_map[label_id] = label# 加载分词器和模型tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForTokenClassification.from_pretrained(model_name, num_labels=len(labels_map))model.to(device)while True:text = input("请输入:")if not text or text == '':continueif text == 'q':breakencoded_input = tokenizer(text, padding="max_length", truncation=True, max_length=max_length)input_ids = torch.tensor([encoded_input['input_ids']]).to(device)attention_mask = torch.tensor([encoded_input['attention_mask']]).to(device)outputs = model(input_ids, attention_mask=attention_mask)result = post_processing(outputs, text, labels_map)print(result)if __name__ == '__main__':main()输入:根据北京市住房和城乡建设委员会总体工作部署,市建委调配给东城区118套房源,99户家庭全部来到现场
识别结果:
{'government': ['北京市住房和城乡建设委员会'], 'address': ['东城区']}
输入:为星际争霸2冠军颁奖的嘉宾是来自上海新闻出版局副局长陈丽女士。最后,为魔兽争霸3项目冠军—
识别结果:
{'game': ['星际争霸2', '魔兽争霸3'], 'position': ['上海新闻出版局'], 'name': ['副局长', '陈丽']}
输入:作出对成钢违纪辞退处理决定,并开具了退工单。今年8月,公安机关以不应当追究刑事责任为由
识别结果:
{'name': ['成钢'], 'government': ['公安机关']}
这篇关于基于 chinese-roberta-wwm-ext 微调训练中文命名实体识别任务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




