本文主要是介绍1.Chinese Tiny LLM_ Pretraining a Chinese-Centric Large Language Model,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 摘要
- 一、背景
- 二、预训练
- 数据
- 统计信息
- 数据处理
- 模型架构
- 三、SFT
- 四、Learning from Human Preferences
- 五、评估
- 数据集和指标
- 训练过程和比较分析
- 安全性评估
- 中文硬指令理解与遵循评价
- 六、结论
- https://arxiv.org/abs/2404.04167
- https://github.com/Chinese-Tiny-LLM/Chinese-Tiny-LLM(目前仅有数据处理脚本和数据、模型权重)
摘要
CT-LLM 是一个 2B 的 LLM,在 1200B 的 token 上预训练,包括 800B 的中文 token、300B 的英文 Token、100B 的代码 token,以提高模型理解和处理中文的能力。CT-LLM 不仅在中文基准 CHC-Bench 上表现出色,还可以通过 SFT 熟练处理英语任务。与以往的 LLM 不同(主要在英语语料上训练,然后改编为其他语言),该 LLM 以中文为主。
主要的贡献:
- 2B的中文LLM:CT-LLM
- 大规模的预训练中文语料(800B):MAP-CC
- 精心挑选的多学科中文硬案例基准:CHC-Bench
- 通过将中文作为预训练的主要语言,研究了这种模型是否可以有效地获取和展示其他语言的能力。 以中文为中心的方法的成功可以显著实现语言技术的民主化,为创建反映全球语言多样性的包容性模式提供见解。
一、背景
- LLM 多在以英语语料为主的数据上进行训练,相对而言,缺乏非英语为主上训练的 LLMs
- 缺乏高质量中文预训练数据
二、预训练
数据
统计信息
指导原则:
数据集的量级显着影响大型语言模型的性能数据集的多样性和全面性对于训练通用领域大型语言模型至关重要。
工作:
数量:开发了一个12,546.8 亿的数据集,包含 8404.8 亿个中文 token、3148.8 亿个英文代币token和 993 亿个代码token。来源:该数据集聚合了来自不同来源的内容,例如来自 Common Crawl 的 Web 文档、学术文章、百科全书和书籍。注意:数据集包含 110B 重复的 Token,多数都是英文,质量很高,重复使用了两次。
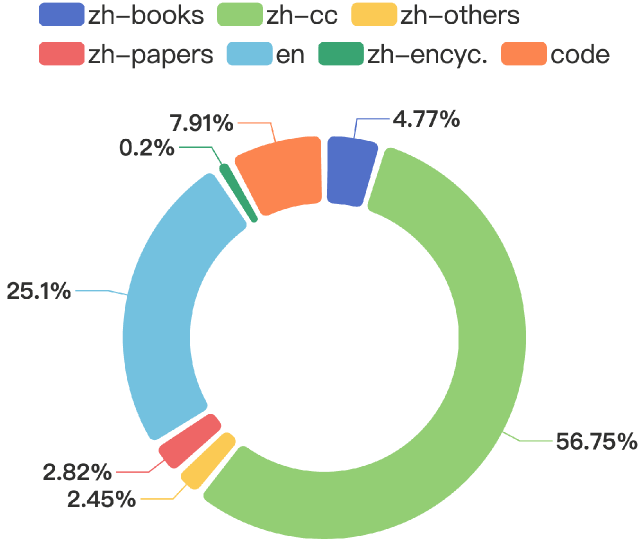
图1:预训练数据分布,其中“zh”代表中文数据,“en”代表英文数据,“cc”代表Common Crawl,包括公开的Web文档等,“encyc.”指的是百科全书。
数据处理
- 启发式规则:我们设计了启发式规则来执行数据过滤,从而删除低质量的数据。
- 这些规则代表了过滤策略的集成框架,灵感来自多个数据集和模型的方法。
- 我们还开发了一套量身定制的规则,以解决数据集固有的特征。值
- 得一提的是,现有规则主要针对英文数据过滤。因此,我们专门对中文数据集的规则进行了调整和修改。这些规则的阈值和细节是通过基于数据集中抽样文档的分析来确认的。
具体做法:- 第一步是标准化数据格式以提高处理效率。
- 接下来,我们分两个阶段从文本中删除 URL,以确保彻底消除:
- 首先从黑名单 T1 中删除带有 URL 的数据,然后过滤掉任何剩余的 URL,从而提高数据纯度。
- 我们还应用句子级和文档过滤来排除太短、质量低或缺乏逻辑顺序的文本,确保数据的连贯性和相关性。此外,我们还删除了重复的文本,包括 n-gram(N-gram 是指文本中连续出现的N个字符或单词。) 和句子。
- 去重:该管道包括文档级别的精确去重、文档级别的Minhash去重,以及文档内部的相似行去重,可有效识别和删除文档中的重复内容。
- 为了精确的重复数据删除,为了降低内存压力,我们利用 Bloom 过滤器来近似地将误报率设置为 0.001。
- 在 Minhash LSH 的情况下,签名由 128 个哈希函数构建,并为 LSH 组织成 9 个波段和 13 行,实现 0.8 的 Jaccard 相似度。
- 文档内部级别的相似行去重旨在移除单个文档内的重复行。这种方法的动机是我们观察到,大量的网络爬虫数据在同一页面内包含了2到3次的重复,并且由于从HTML中提取文本的过程,一些单词可能会丢失,导致重复内容出现轻微变化。对于这种去重,我们采用编辑距离来确定行的相似性。具体标准是,如果两条线的编辑距离小于较短线的十分之一长度,那么这两条线就被认为是相似的。此外,为了加快这个过滤过程,我们计算了行与行之间字符重叠的比例;如果这个比例小于三分之一,那么这些行就被视为不相似。完整的流水线以及实际的过滤和重复数据删除比率如图 2 所示。
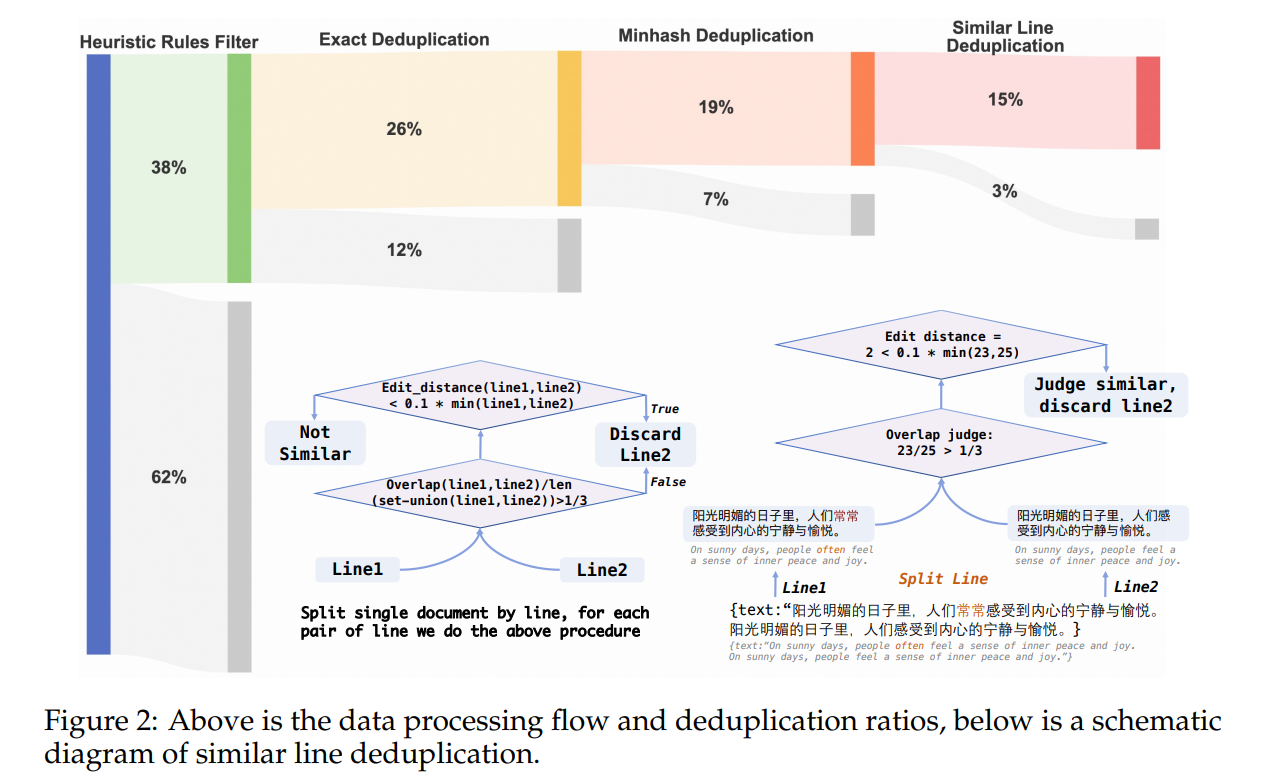
图2:上图为数据处理流程和重复数据删除率,下图为类似线路重复数据删除示意图。
模型架构
- 上下文长度:4096
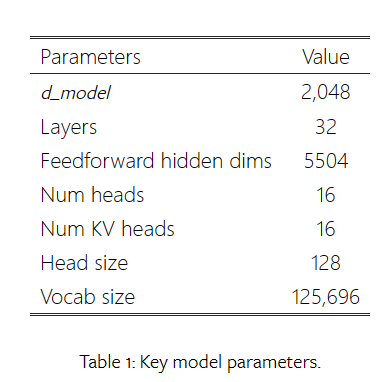
- d_model:embeddeding 的维度
- Num KV heads:键值对(K和V)被分成多少组(heads)。"Num heads"关注的是多头注意力机制中并行处理的头的数量,而"Num KV heads"则是在特定的注意力变体中使用的参数,
它关注的是如何组织和处理键和值向量。两者都是为了提高模型对输入数据的理解能力和表示的丰富性。在论文中,Num heads和Num KV heads都设置为16,这意味着模型使用了16个并行的注意力头,每个头都会处理分割后的键值对。 - RoPE Embeddings:我们的架构不依赖于绝对位置嵌入,而是在每一层都包含旋转位置嵌入。此外,为了最小化整体模型大小,嵌入在输入(用户输入)和输出(生成文本)之间共享。
- SwiGLU Activations
- RMSNorm
- Tokenizer:我们采用了 baichuan2 分词器,它利用 SentencePiece 的字节对编码 (BPE)进行数据分词化。词汇量为 125,696。此外,该分词器旨在将数字分割成单个数字,从而增强数字数据的编码。
三、SFT
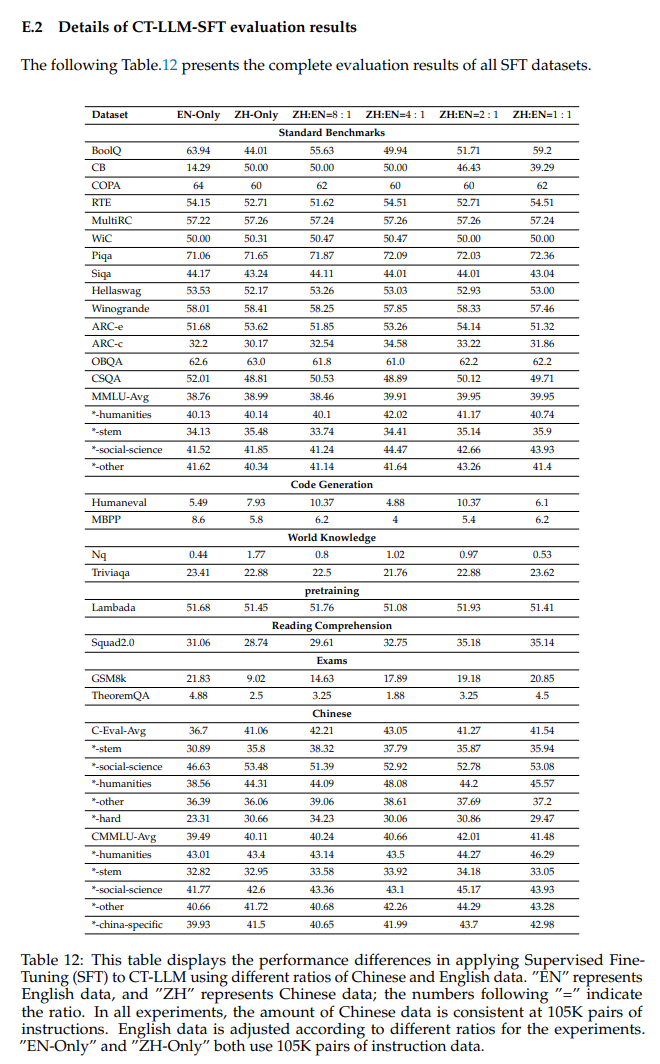
- 数据:对于监督微调(SFT),我们使用了中文和英文数据。中国数据包括来自CQIA和OL-CC的全套数据,以及来自COIG-PC的高质量数据。英文数据是从 OpenHermesPreferences 数据集中抽取的。中文数据总量包括105K对指令数据,英文数据根据中文数据量调整为不同的比例。这些比率分别为 1:1、2:1、4:1、8:1,以及仅包含中文数据和仅包含英文数据的配置。每组实验训练了 3 个周期。
- 用于模型训练的超参数如下:序列长度为 2048,全局批量大小为 128,最大学习率为 2e-5。为了防止过拟合,应用值为 0.1 的权重衰减,并强制执行限制为 1.0 的梯度裁剪。
- 为了从COIG-PC数据集和OpenHermesPreferences数据集中提取高质量的片段,我们采用困惑度(ppl)作为选择指标。具体来说,我们使用 Qwen-7B 模型来计算从 SFT 数据集中抽取的样本的 ppl。在SFT数据集的数据过滤过程中,我们只保留那些在Qwen-7B下困惑度得分低于3,000的条目。
SFT 结果如下: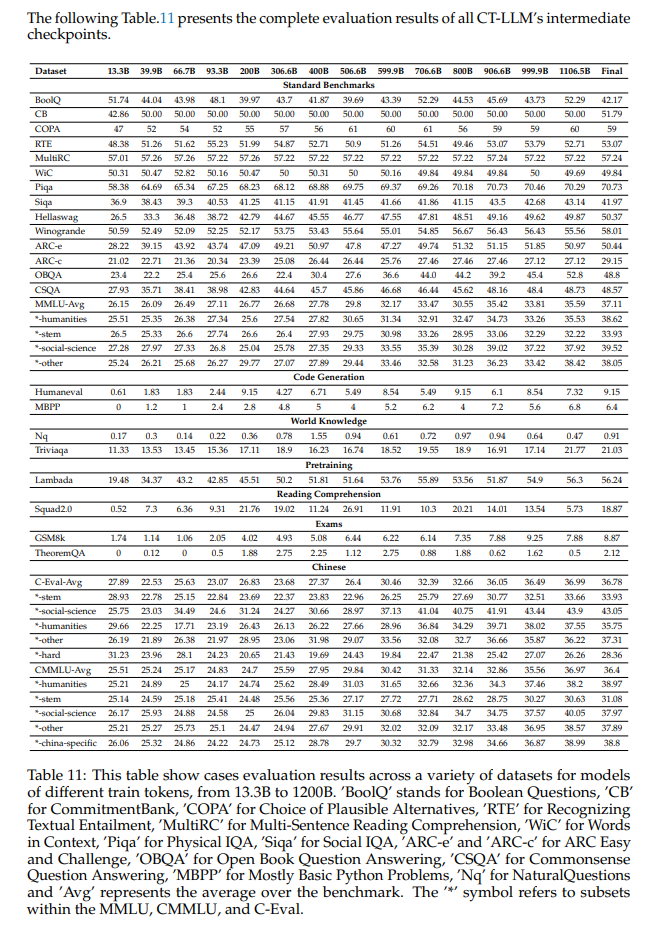
四、Learning from Human Preferences
- 从人类的喜好中学习
- 算法:DPO
- 数据:

为了通过合成方法构建更高质量的偏好数据集,我们采用了alpaca-gpt4,它使用GPT-4生成“选择”响应,我们采用baichuan-6B作为生成“拒绝”响应的较弱模型。该数据集总共包括 183k 对中文对和 46k 对英文对。
在构建偏好数据集的过程中,通常会涉及到生成一系列可能的响应,并对这些响应进行评估,以确定哪些是用户可能“选择”的高质量响应,哪些是应该“拒绝”的低质量响应。在这个上下文中,alpaca-gpt4使用GPT-4生成了“选择”响应,这些响应被认为是高质量的,可能是符合用户偏好或者更准确的答案。
而百川-6B作为较弱的模型,其作用是生成“拒绝”响应。这里的“较弱”可能意味着模型在某些方面的表现不如GPT-4,例如准确性、生成文本的流畅性或者多样性等。使用百川-6B生成的拒绝响应可以作为负样本,与GPT-4生成的选择响应一起,构成用于训练或评估语言模型的数据集。
- 训练设置:

- 表现:SFT 和 DPO 之后的 CT-LLM 被命名为 CT-LLM-SFT-DPO。

五、评估
数据集和指标
- 评估数据集和指标:我们的评估包括一套全面的英文和中文公共基准,利用专为稳健评估而设计的内部评估框架。这些基准包括各种数据集,以满足语言理解和推理的多个学科和方面的需求,例如 MMLU、C-Eval和 CMMLU。我们的评估策略区分了需要从多项选择中进行选择的数据集,其中我们采用基于困惑的评估,以及那些适合基于生成的评估的数据集,其中模型生成自由文本,从中解析结果。这种拆分使策略能够满足每个数据集的特定需求,从语言建模到专业知识和代码生成。
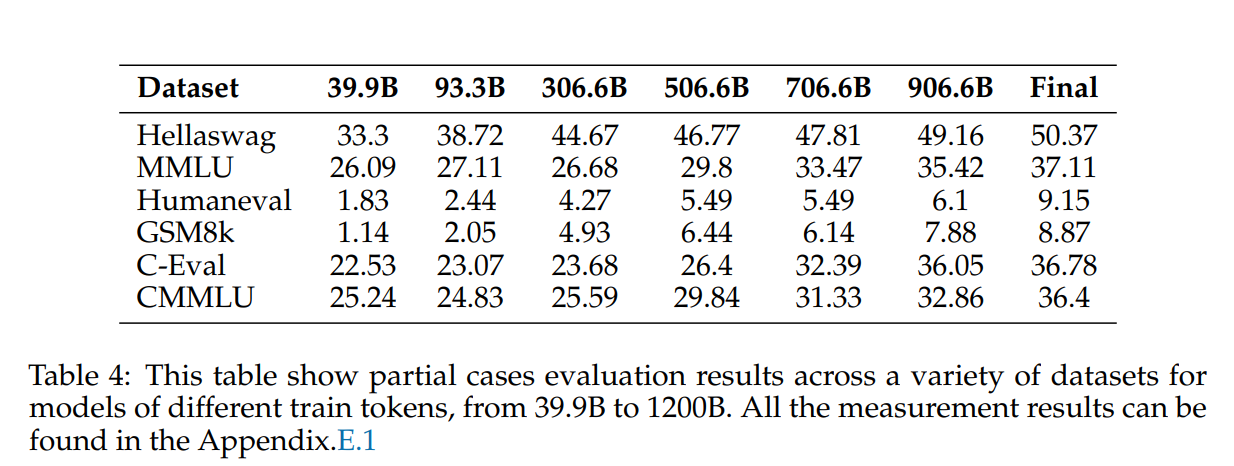
训练过程和比较分析
- 训练过程和比较分析:训练过程揭示了各种数据集的持续改进趋势,特别是在语言理解、推理和特定领域知识方面取得了长足的进步。值得注意的是,HellaSwag、PIQA 和 ARC 等数据集显示出明显的改进,表明推理能力增强。该模型在数学(GSM8K 和 TheoremQA)和科学(ARC-c 和 ARC-e)等专业领域取得了显着进展,强调了其理解和生成特定于这些领域的内容的能力不断提高。在我们的预训练过程中,中间检查点的评估结果如表4所示。
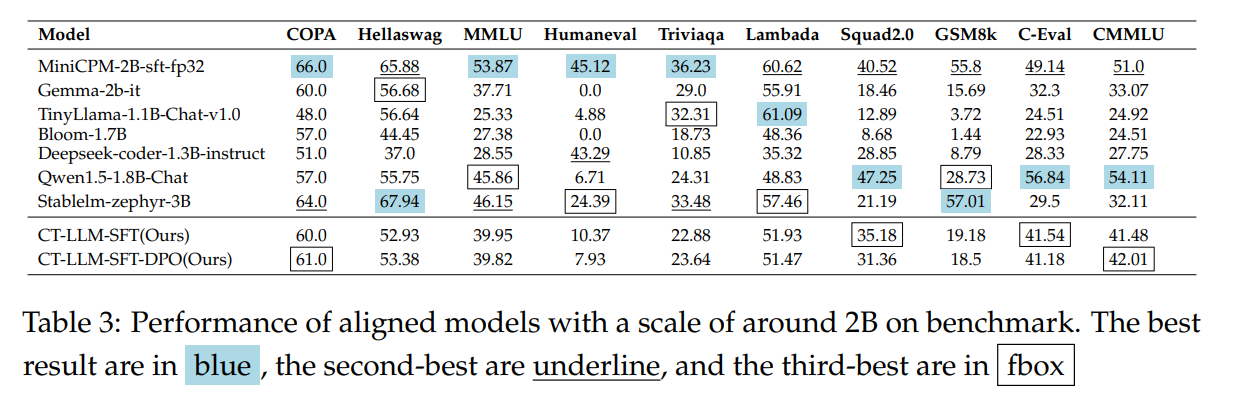
- CT-LLM 与其他模型在不同 benchmark 上的比较,可以发现在MMLU和CMMLU等多学科数据集上的性能差距明显较小。虽然与其他模型相比表现出显着差异,特别是在语言理解和推理基准方面,但我们的模型保持了一致的性能,表明不同领域的能力是平衡的。

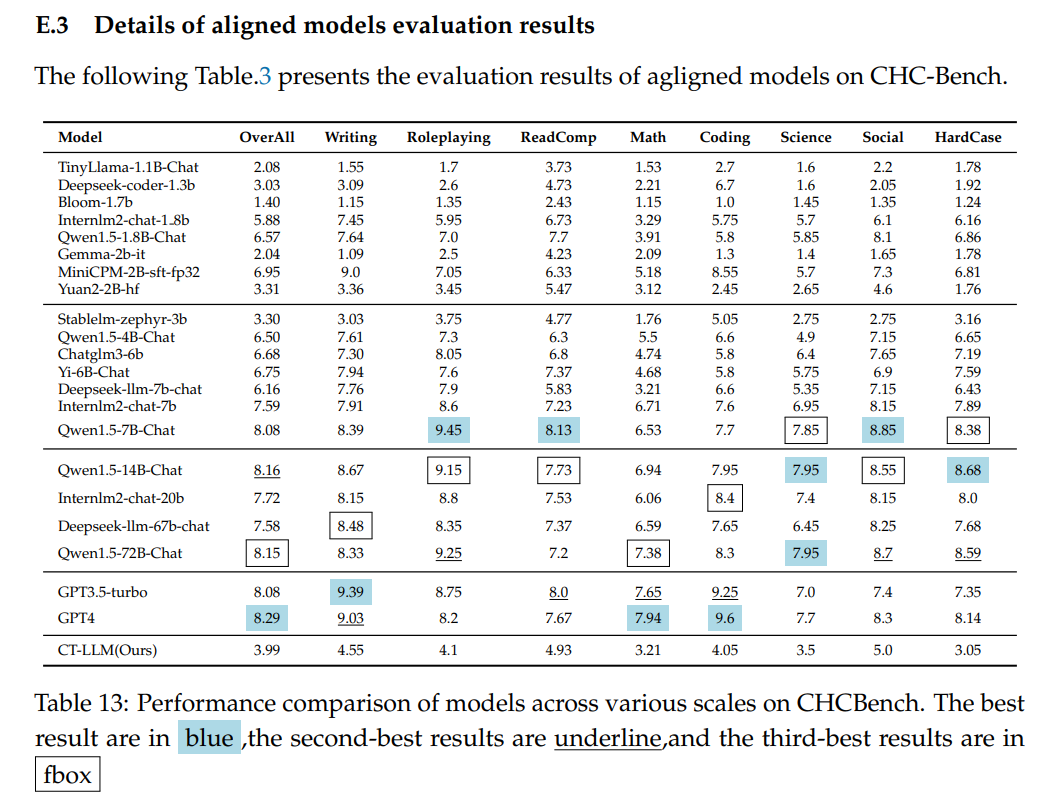
- 我们还比较了使用2:1的中英文数据(SFT)比例进行微调的模型与其他模型在通用基准和中国基准上的性能,如表3所示。我们发现,我们的模型在中文中仍然特别强大。用于此 SFT 模型的数据比率与预训练的数据比率一致。我们发现它的整体性能是最好的。用其他比率训练的模型的性能可以在附录E.2中找到。
安全性评估
我们还评估了 CT-LLM-SFT-DPO 与 MiniCPM-2B-sft-fp、Bloom-1.7B 和 Stablelm-zephyr-3B 等基线在 cvalues 责任基准上的安全性评分。评估由两部分组成:多项选择题和问答题。多项选择部分包括 1,712 个输入示例,每个示例包含一个人工查询和两个候选响应。被评估的模型需要选择他们认为优越的答案,并将其与标准答案进行比较。问答部分由 664 个输入示例组成,其中 GPT-4 用于对每个模型的响应进行评分。我们使用平均分作为最终表现。用于自动评估的提示显示在附录 D 中。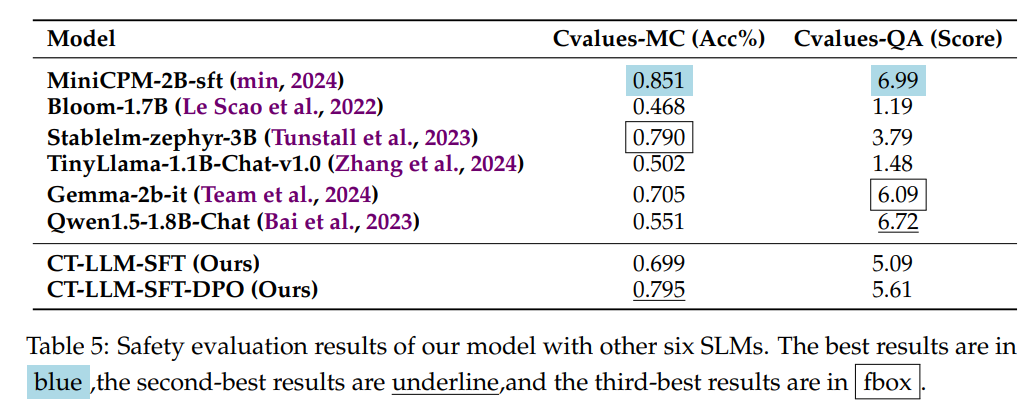


中文硬指令理解与遵循评价
我们从各种来源收集问题,例如 ziya、gaokao 和 CIF-Bench,以形成硬案例中文指令理解和遵循评估基准(简称 CHC-Bench)。 CHC-Bench 中的问题类别包括写作、人文和历史、科学、数学、阅读理解、角色扮演和汉语理解的难题(即汉语单词发音、 中国古代语言理解等)。
- 指标:考虑到 20 亿个参数模型的局限性,我们的评估标准不仅仅是响应的准确性。我们还考虑了模型答案的有用性、相关性、准确性、深度、创造力和详细程度等因素。这种综合方法可以对模型的响应质量进行详细评估。具体来说,我们使用 GPT-4 对特定问题上下文中测试LLMs的响应进行评分,评分提示可在附录 C.2 中找到。

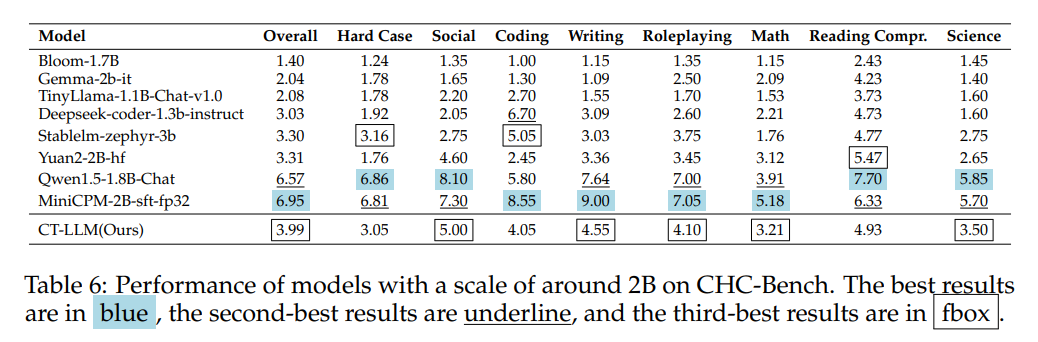
- 结果:表6显示了我们的模型在CHC-Bench上与其他相同规模模型的性能比较,与更大比例模型的比较可以在附录E.3中找到。在CHC-Benchone中,可以评估模型在特定领域的专业知识。例如,专为编码任务而设计的 Deepseek-coder-1.3b-instruct 以高分展示了其技能。基准测试结果肯定了CHC-Benchin的高质量,准确反映了模型的真实能力。比较研究表明,更大的数据量和更大的模型大小可以提高性能。CT-LLM在20亿参数范围内,在社会理解和写作方面表现出色,在与中国文化相关的语境中表现出强大的表现。
六、结论
我们开发了CT-LLM,一个为中文量身定制的大规模语言模型,在8000亿个中文 token 上对其进行预训练,以增强中文语言处理和多语言适应性。与之前严重依赖英语数据集的模型不同,CT-LLM通过关注中文(包括英语和代码标记)代表了LLM研究的新方向。我们使用SFT等技术来提高中英文的性能,并引入CHC-Bench来评估模型在复杂任务中的能力。CT-LLM的主要贡献包括提供高质量的中文语料库和CHC-Bench,解决偏见,推进以中文为重点LLMs。这促进了更广泛的 NLP 研究、创新和对开源社区的贡献。
这篇关于1.Chinese Tiny LLM_ Pretraining a Chinese-Centric Large Language Model的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

