本文主要是介绍Re72:读论文 XLM Cross-lingual Language Model Pretraining,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名:Cross-lingual Language Model Pretraining
模型简称:XLM
ArXiv地址:https://arxiv.org/abs/1901.07291
这是2019年NeurIPS的论文,主要做到就是跨语言BERT。主要创新点就是做了多语言的BERT预训练,改了一下放数据的方式(TLM,放平行语料做预训练)
文章目录
- 1. 研究方法
- 1. 词表
- 2. 预训练目标
- 2. 实验结果
1. 研究方法
1. 词表
所有语言共用一套BPE词表。
2. 预训练目标
无监督单语言预训练:
Causal Language Modeling (CLM):预测未来内容。为了简便起见,删除了每个batch没有上下文的开头词语。
Masked Language Modeling (MLM):完形填空。用的是text streams而不是sentence pair(意思就是可以咔咔塞一大段,但句子长度相似),对标点符号用多项分布抽样
在有平行语料条件下的监督多语言预训练:
Translation Language Modeling (TLM):MLM加强版,用平行语料来代替text streams

综合后:
① CLM / MLM:每个batch用单语言
② TLM + MLM:不同batch用不同的学习目标
2. 实验结果
没啥好讲的,反正表现出了模型效果最好。
跨语言分类:

无监督翻译:

有监督翻译:

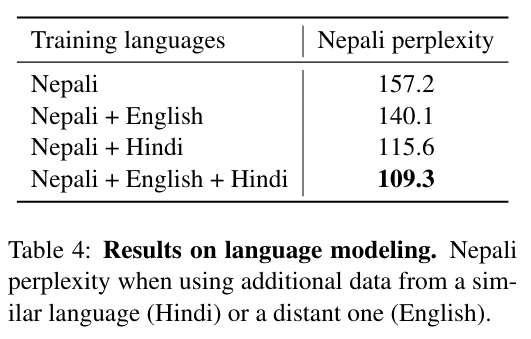
用相似语言共同预训练可以提高低资源预训练模型效果(perplexity):
这篇关于Re72:读论文 XLM Cross-lingual Language Model Pretraining的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






