xlm专题

XLM-RoBERTa 是一种多语言版本的 RoBERTa 模型
XLM-RoBERTa 是一种多语言版本的 RoBERTa 模型,由 Facebook AI 开发。它是为了处理多种语言的自然语言理解任务而设计的。 XLM-RoBERTa 的主要特性: 多语言能力:在使用 CommonCrawl 数据集的 100 种语言上进行训练,XLM-RoBERTa 可以在多种语言上表现出色,而不需要为每种语言单独训练模型。大规模预训练:该模型在大型多样化语料库上进行预
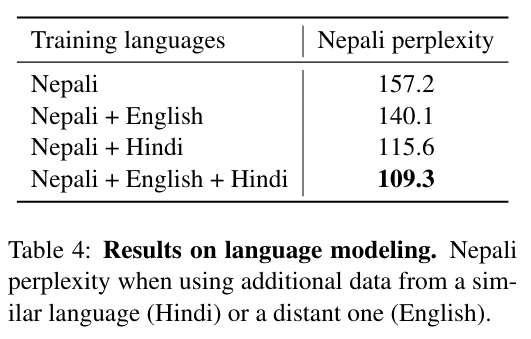
Re72:读论文 XLM Cross-lingual Language Model Pretraining
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类 论文名:Cross-lingual Language Model Pretraining 模型简称:XLM ArXiv地址:https://arxiv.org/abs/1901.07291 这是2019年NeurIPS的论文,主要做到就是跨语言BERT。主要创新点就是做了多语言的BERT预训练,改了一下放数据的方式(TLM

NLP-预训练模型:迁移学习(拿已经训练好的模型来使用)【预训练模型:BERT、GPT、Transformer-XL、XLNet、RoBerta、XLM、T5】、微调、微调脚本、【GLUE数据集】
深度学习-自然语言处理:迁移学习(拿已经训练好的模型来使用)【GLUE数据集、预训练模型(BERT、GPT、transformer-XL、XLNet、T5)、微调、微调脚本】 一、迁移学习概述二、NLP中的标准数据集1、GLUE数据集合的下载方式2、GLUE子数据集的样式及其任务类型2.1 CoLA数据集【判断句子语法是否正确】2.2 SST-2数据集【情感分类】2.3 MRPC数据集【判断

XLM跨语言模型-论文笔记
1 简介 跨语言模型XLMs。本文根据2019年Facebook AI Research的《Cross-lingual Language Model Pretraining》翻译总结。 XLMs有如下贡献: 1) 我们介绍了一个新的非监督方法,可以使用跨语言模型学习跨语言表述(TLM),同时研究了两个单语言的预训练,CLM和MLM。 2) 当并行数据(双语数据)可以获得时,我们引入了一个监督学

Python使用xlm库爬取信息
文章目录 前言使用步骤1.引入库2.下级数据 前言 记录第一次爬虫记录,以京客隆超市店铺信息为目标,拿到店铺的全部信息,并生成excel表格 使用步骤 1.引入库 在爬取网站信息是首先我们要了解该页面的组成,了解该页面的下级分类,找到你所需要的元素,通过xpath定位来获取页面的信息,需要一定的WEb元素定位的知识,只有找到正确的位置才能进行下面的操作,基本操作
【NLP】多语言预训练模型(mBERT和XLM)
融合多语言的预训练模型将不同语言符号统一表示在相同的语义向量空间内,从而达到跨语言处理的目的。 多语言BERT (Multilingual BERT, mBERT) 它能够将多种语言表示在相同的语义空间中。 通过HuggingFace提供的transformers库: 使用区分大小写的多语言BERT-base模型(bert-base-multilingual-cased),任务为掩码填充,即将

几个与BERT相关的预训练模型分享-ERNIE,XLM,LASER,MASS,UNILM
基于Transformer的预训练模型汇总 1. ERNIE: Enhanced Language Representation with Informative Entities(THU) 特点:学习到了语料库之间得到语义联系,融合知识图谱到BERT中,本文解决了两个问题,structured knowledge encoding 和 Heterogeneous Information Fu
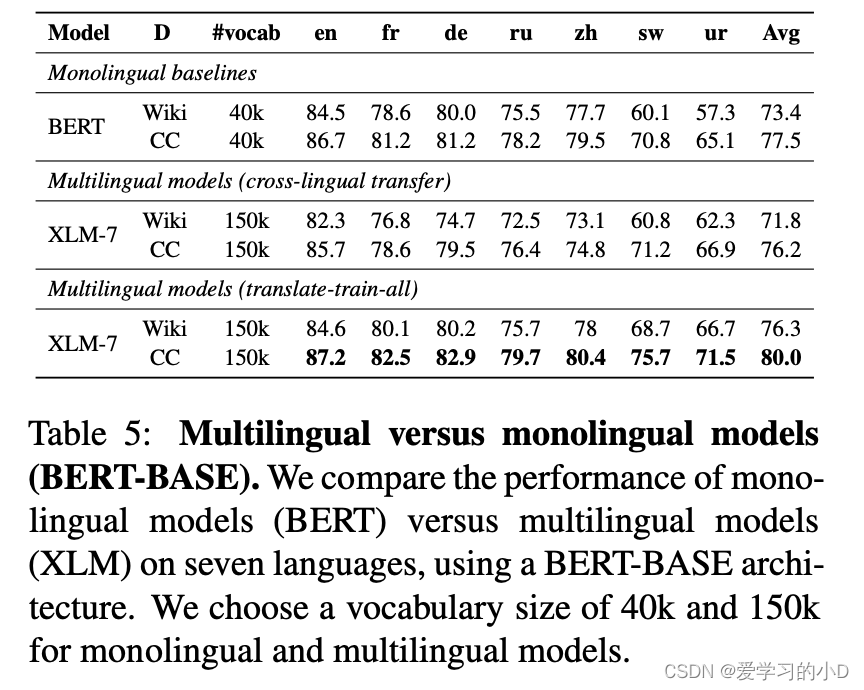
论文阅读【自然语言处理-预训练模型3】XLM-R:Unsupervised cross-lingual representation learning at scale
Unsupervised cross-lingual representation learning at scale(ACL 2019) 【论文链接】:https://aclanthology.org/2020.acl-main.747.pdf 【代码链接】:https://github.com/facebookresearch/XLM 【来源】:由Facebook AI Research

AOP中xlm配置和注解配置
概念:Aspect Oriented Programming 面向切面编程 面向切面编程时一种改编成思想。就是通过预编译和运行期的动态代理,实现程序功能的统一维护。spring是对这个思想的实现。 动态代理:简而言之就是在不修改源代码的情况下,对其中的方法进行增强,实现调用者和实现者的解耦。常用的动态代理有: JDK代理:基于接口的动态代理技术cglib代理:基于父类的动态代理技术 对一些概