lingual专题
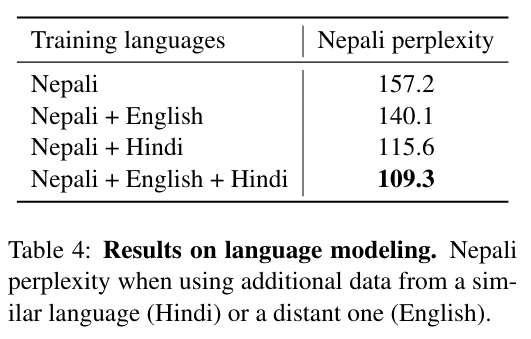
Re72:读论文 XLM Cross-lingual Language Model Pretraining
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类 论文名:Cross-lingual Language Model Pretraining 模型简称:XLM ArXiv地址:https://arxiv.org/abs/1901.07291 这是2019年NeurIPS的论文,主要做到就是跨语言BERT。主要创新点就是做了多语言的BERT预训练,改了一下放数据的方式(TLM

2020.3 Enhanced meta-learning for cross-lingual named entity recognition with minimal resources 阅读笔记
Motivation Problem Setting: a) One source language with rich labeled data.b) No labeled data in the target language. 现有的 Cross-lingula NER 方法可以分为两大类: a) Label projection (generate labeled data in tar
2017. cheap translation for Cross-lingual NER 阅读笔记
cheap translation for Cross-lingual NER, Illinois Champaign 提出了一个生成翻译字典的 cheap translation 算法该算法可以和 wikifier features、Brown Cluster features 等结合取得更好的效果通过实验说明当 source Lan. 与 traget Lan. 相似度比较高时,可以进一步提

2018.9. Neural Cross-Lingual Named Entity Recognition 阅读笔记
Jiateng Xie Neual Cross-Lingual Named Entity Recognition, CMU Abstract 本文提出了两种方法来解决 under the unsupervised transfer setting 下 cross-lingual NER 中的挑战。lexical mapping (STEP 1-3). word ordering (STEP
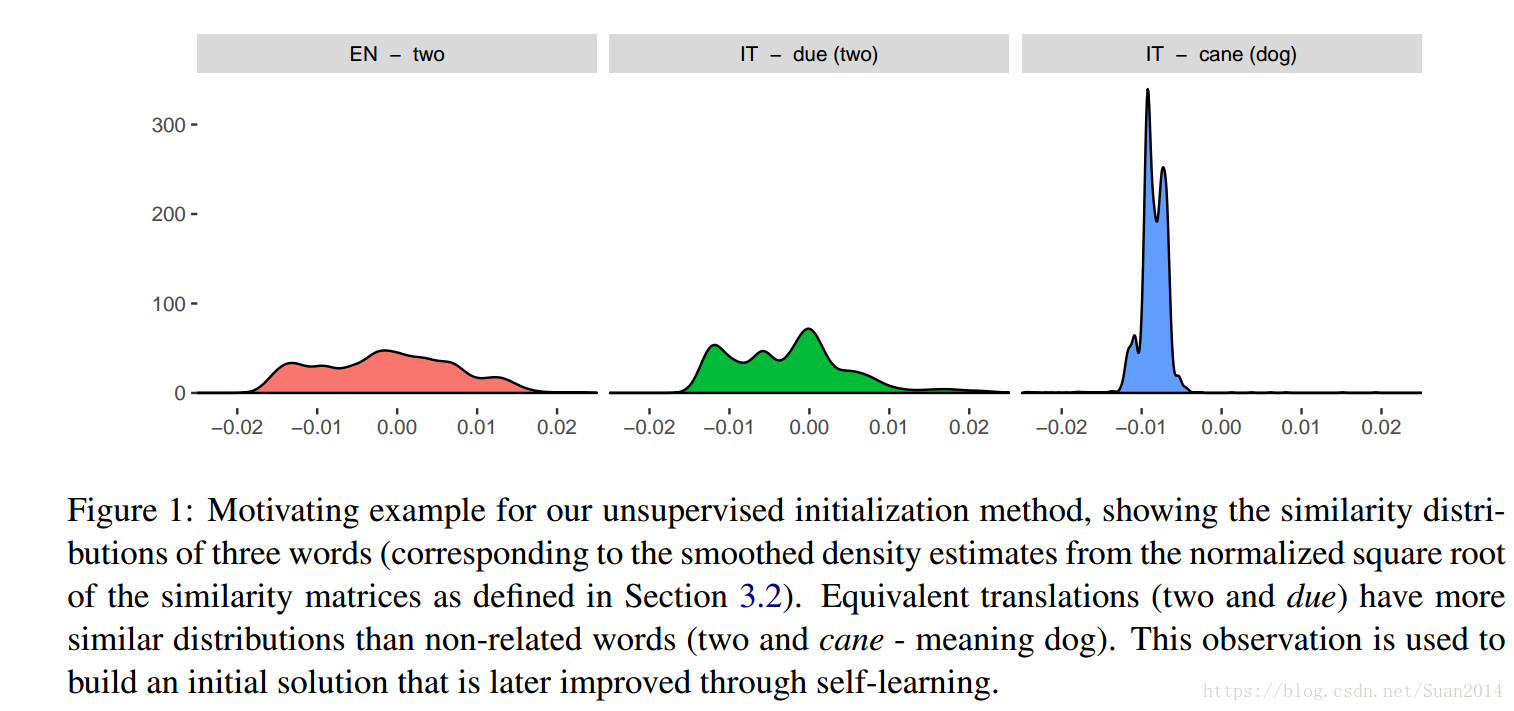
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings论文笔记
回看前几篇笔记发现我剪贴的公式显示很乱,虽然编辑时调整过了,但是不知道为什么显示的和编辑时的不一样,为方便大家的阅读,我开始尝试着采用markdown的形式写笔记,前几篇有时间的话再修改。 这篇论文阅读完,我依然有很多不懂的地方,对其操作不是很清晰,因为我没做过这方面的内容,且近期估计没时间学习其项目,所以记录理解的可能有误,希望大家带着思考阅读。 PS:感觉这篇文章的作者是这个方向的大神呢,
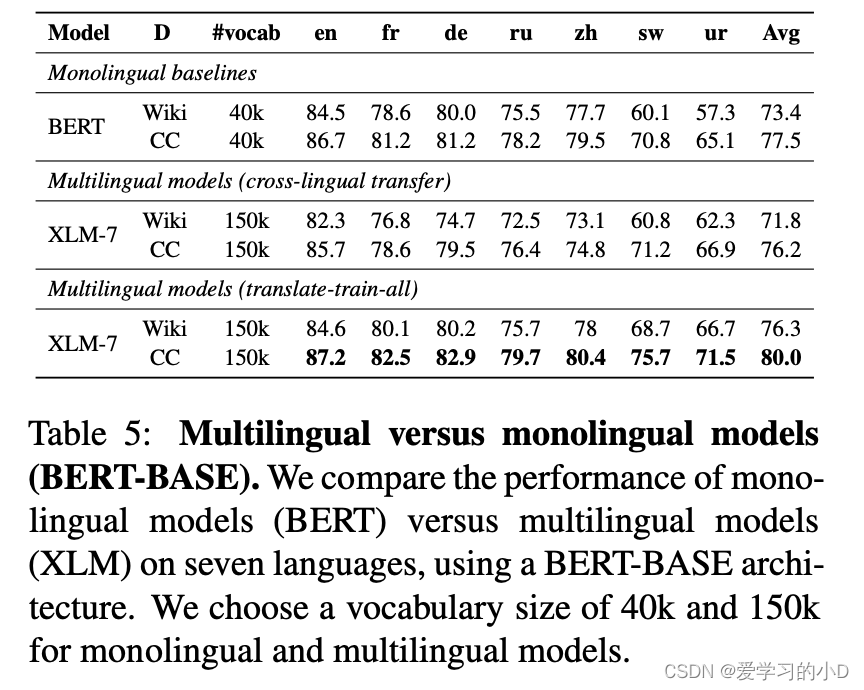
论文阅读【自然语言处理-预训练模型3】XLM-R:Unsupervised cross-lingual representation learning at scale
Unsupervised cross-lingual representation learning at scale(ACL 2019) 【论文链接】:https://aclanthology.org/2020.acl-main.747.pdf 【代码链接】:https://github.com/facebookresearch/XLM 【来源】:由Facebook AI Research

Fantasy Mix-Lingual Tacotron Version 4: Google-ZYX-Phoneme-HCSI-DBMIX 调整LID
0. 说明 VAE + LID效果目前是最好的, 将LID调整下, 不在decoder拼接LID, 在encoder_output处拼接 1. 枚举方案 有以下方案 speaker emb和residual仍然在decoder拼接, 只LID在前面speaker emb和residual放在前面与否, 仅仅是被query的内容不同; 而根据query为声学特征, memory为文本特征,

【论文解读 EMNLP 2018】Cross-Lingual Cross-Platform Rumor Verification Pivoting on Multimedia Content
论文题目:Cross-Lingual Cross-Platform Rumor Verification Pivoting on Multimedia Content 论文来源:EMNLP 2018 论文链接:https://www.aclweb.org/anthology/D18-1385/ 代码链接:https://github.com/WeimingWen/CCRV 关键词

【翻译】NCLS: Neural Cross-Lingual Summarization
Abstract 跨语言摘要(CLS)是为不同语言的源文件生成特定语言摘要的任务。现有方法通常将此任务分为两个步骤:摘要和翻译,导致错误传播的问题。为了解决这个问题,我们首次提出了一种端到端的CLS框架,我们称之为神经跨语言摘要(NCLS)。此外,我们建议通过将两个相关任务,即单语摘要和机器翻译,纳入多任务学习的CLS培训过程中,进一步改进NCLS。由于缺乏监督CLS数据,我们提出了一种往返翻译