本文主要是介绍A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
回看前几篇笔记发现我剪贴的公式显示很乱,虽然编辑时调整过了,但是不知道为什么显示的和编辑时的不一样,为方便大家的阅读,我开始尝试着采用markdown的形式写笔记,前几篇有时间的话再修改。
这篇论文阅读完,我依然有很多不懂的地方,对其操作不是很清晰,因为我没做过这方面的内容,且近期估计没时间学习其项目,所以记录理解的可能有误,希望大家带着思考阅读。
PS:感觉这篇文章的作者是这个方向的大神呢,引用里好多都是他自己的文章
原文下载链接
项目下载链接
摘要
- 跨语种嵌入映射(cross-lingual embedding mappings)的核心思想:分别训练单个语种语料,再通过线性变换映射到shared space。
- 方法整体分为监督的、半监督的和非监督的,监督和半监督都要依赖种子字典(seed dictionary),本文主要研究非监督的方法
- 非监督方法主要有两种:对抗训练(adversarial training)和自学习(self-learning)
- 对抗训练的缺点:依赖favorable conditions(如限制在相关的语种,类似维基百科的语料)
- 自学习的缺点:初始化不好时,易陷入差的(poor)局部最优
- 本文即使根据自学习的缺点提出了初始化的方法。
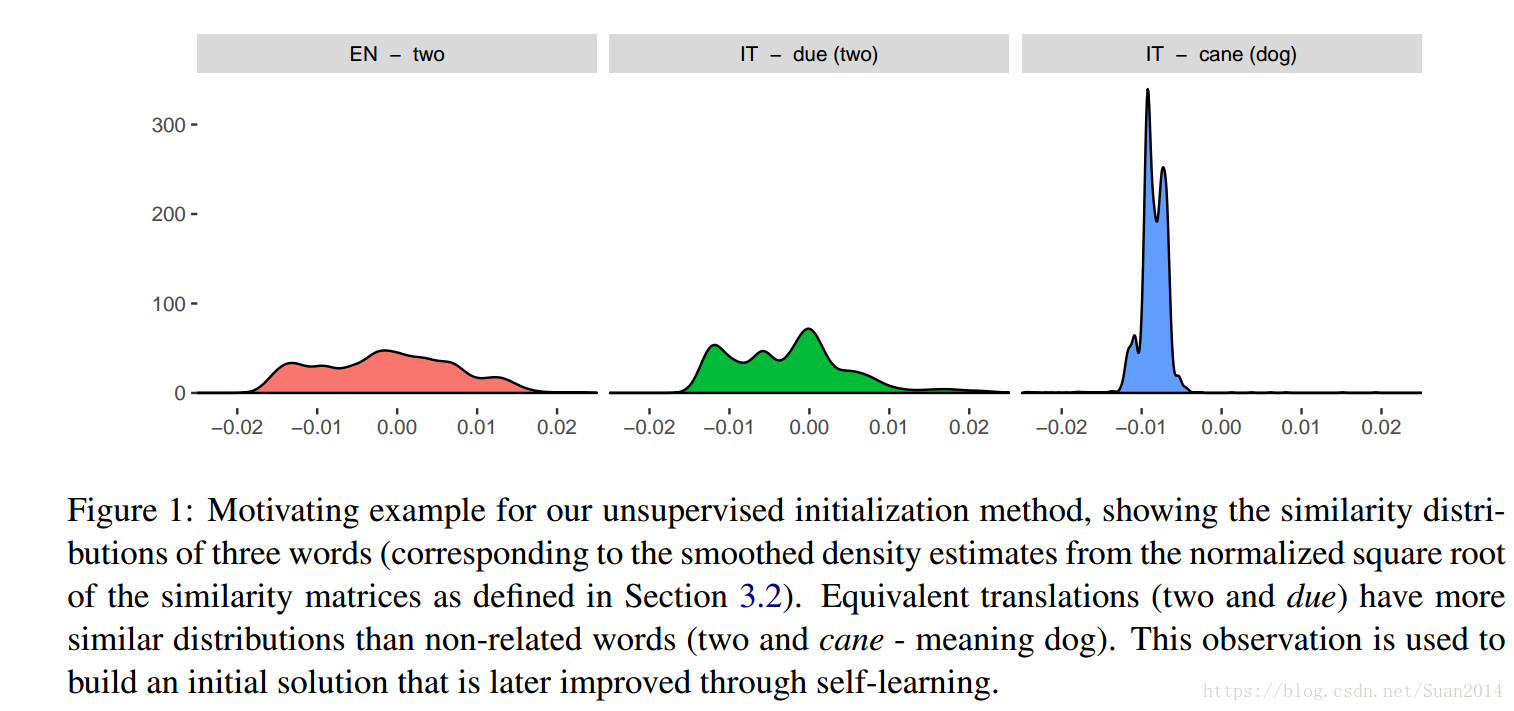
- 提出方法的依据是:观察到不同语种中相同的词有相似的相似度分布,如图1所示:
Figure 1中的第一幅图是英文单词two的相似度分布,第二幅图是意大利语due(等同于two)的相似度分布,第三幅图是意大利语cane(等同于dog)的相似度分布。
本文算法
设X和Z是两种语言的embedding矩阵,所以他们的第 i t h ith ith行 X i ∗ X_{i*} Xi∗和 Z i ∗ Z_{i*} Zi∗表示他们语种中的第 i i i个词,我们的目标就是学习变换矩阵 W X {W_{X}} WX和 W Z {W_{Z}} WZ,所以映射embedding X W X {XW_{X}} XWX和 Z W Z {ZW_{Z}} ZWZ在相同的跨语种空间,同时,要在两个语种中构建一个字典即稀疏矩阵 D D D,如果目标语言中的第j个单词是源语言中第i个单词的翻译,则Dij = 1。
本文算法主要分四步:1)normalize embedding的预处理;2)完全非监督的初始化方案;3)鲁棒性强的self-learning步骤;4)最后微调通过对称re-weighting进一步improve mapping.
1 embedding normalization
这边具体不知道怎么做的,只能把翻译写下来了(也不知道翻的对不对):长度标准化嵌入,然后平均每个维度的中心,然后长度再次标准化它们。(原文:length normalizes the embeddings, then mean centers each dimension, and then length normalizes them again.)
2 完全非监督初始化
这里我就拷贝公式了,剩下的部分因为我也似懂非懂所以就简单写一下:mapping中的一个难点是X和Z并不对应,此处包含两方面,词不对应(反应到行),维度不对应(反应到列)。
本文的方法是首先通过 M X = X X T M_{X}=XX^{T} MX=XXT和 M Z = Z Z T M_{Z}=ZZ^{T} MZ=ZZT分别求其相似度矩阵,然后对每一行进行排序,然后在进行第一节的规范化操作;
3 Robust self-learning
这部分没看懂啊,大家还是认真看原文吧
4 Symmetric re-weighting
同上一节(羞愧)
这篇文章没仔细看,很多细节没看懂,所以记得也比较草率,之所以还这样记录下来是为了记录下其核心思想,等回顾时也许能用上。这篇写的很差,大家见谅啊~~~~
这篇关于A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






