embeddings专题

# 使用 OpenAI 的 Embeddings 接口实现文本和代码的语义搜索
本文主要介绍 OpenAI 的 Embeddings (嵌入) 接口,该接口可以轻松执行自然语言和代码任务,如语义搜索、聚类、主题建模和分类。 Embeddings 是转换为数字序列的概念的数字表示,使计算机可以轻松理解这些概念之间的关系。Embeddings 在 3 个标准基准测试中优于顶级模型,其中代码搜索的改进相对提升了 20%。 Embeddings 对于处理自然语言和代码非常有用,因

Spring AI 第三讲Embeddings(嵌入式) Model API 第一讲Ollama 嵌入
有了 Ollama,你可以在本地运行各种大型语言模型 (LLM),并从中生成嵌入。Spring AI 通过 OllamaEmbeddingModel 支持 Ollama 文本嵌入。 嵌入是一个浮点数向量(列表)。两个向量之间的距离可以衡量它们之间的相关性。距离小表示关联度高,距离大表示关联度低。 前提条件 首先需要在本地计算机上运行 Ollama。 请参阅官方 Ollama 项目 READ
Spring AI 第三讲Embeddings(嵌入式) Model API 第一讲OpenAI 嵌入
Spring AI 支持 OpenAI 的文本嵌入模型。OpenAI 的文本嵌入测量文本字符串的相关性。嵌入是一个浮点数向量(列表)。两个向量之间的距离可以衡量它们之间的相关性。距离小表示关联度高,距离大表示关联度低。 先决条件 您需要与 OpenAI 创建一个 API,以访问 OpenAI 嵌入模型。 在 OpenAI 注册页面创建账户,并在 API 密钥页面生成令牌。Spring AI
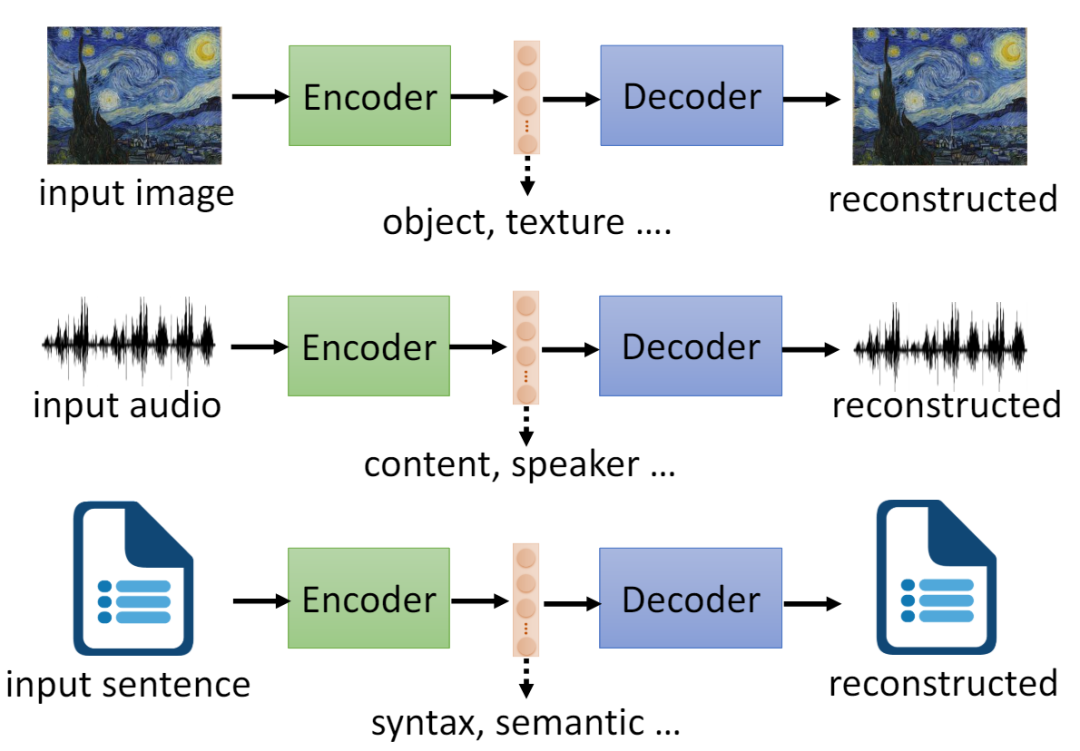
LLM的基础模型4:初识Embeddings
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。 Embeddings Embeddings会分为两个章节,前部分主要

Phn2vec Embeddings
昨天在我爱机器学习上看到Ph2vec,由于自己弄过google的word2vec,出于敏感啊。觉得这个比较好,如果大家想发论文就可以去弄个啊。这种音素转成向量空间。现在翻译在以下: 备注:因为csdn上公式和图什么的都不是很方面。呵呵……直接把word生成图片了。 呵呵……

【LocalAI】(10):在autodl上编译embeddings.cpp项目,转换bge-base-zh-v1.5模型成ggml格式,本地运行main成功
1,关于 localai LocalAI 是一个用于本地推理的,与 OpenAI API 规范兼容的 REST API。 它允许您在本地使用消费级硬件运行 LLM(不仅如此),支持与 ggml 格式兼容的多个模型系列。支持CPU硬件/GPU硬件。 【LocalAI】(10):在autodl上编译embeddings.cpp项目,转换bge-base-zh-v1.5模型成ggml格式
嵌入(embeddings)将离散的标记(tokens)转换为高维向量表示
在序列转换模型中,嵌入(embeddings)是一种将离散的标记(tokens)转换为连续的、高维向量表示的方法。这些向量通常具有维度 ,这个维度是模型的一个超参数,可以根据模型的复杂性和任务的需求进行调整。以下是这一过程的详细说明: 标记化(Tokenization): 将输入文本分割成单词、子词或字符等标记。 词汇表映射(Vocabulary Mapping): 将每个标记映

Embeddings between Hölder spaces C^{0,β}↪C^{0,α}
See https://math.stackexchange.com/questions/2617513/embeddings-between-h%c3%b6lder-spaces-c0-beta-hookrightarrow-c0-alpha

论文略读:Window Attention is Bugged: How not to Interpolate Position Embeddings
iclr 2024 reviewer 打分 6666 窗口注意力、位置嵌入以及高分辨率微调是现代Transformer X CV 时代的核心概念。论文发现,将这些几乎无处不在的组件简单地结合在一起,可能会对性能产生不利影响问题很简单:在使用窗口注意力时对位置嵌入进行插值是错误的 相对位置嵌入直接添加到注意力矩阵——>不仅速度慢,而且无法从最近的创新中受益理想情况下,希望只使用简单快速的绝对位
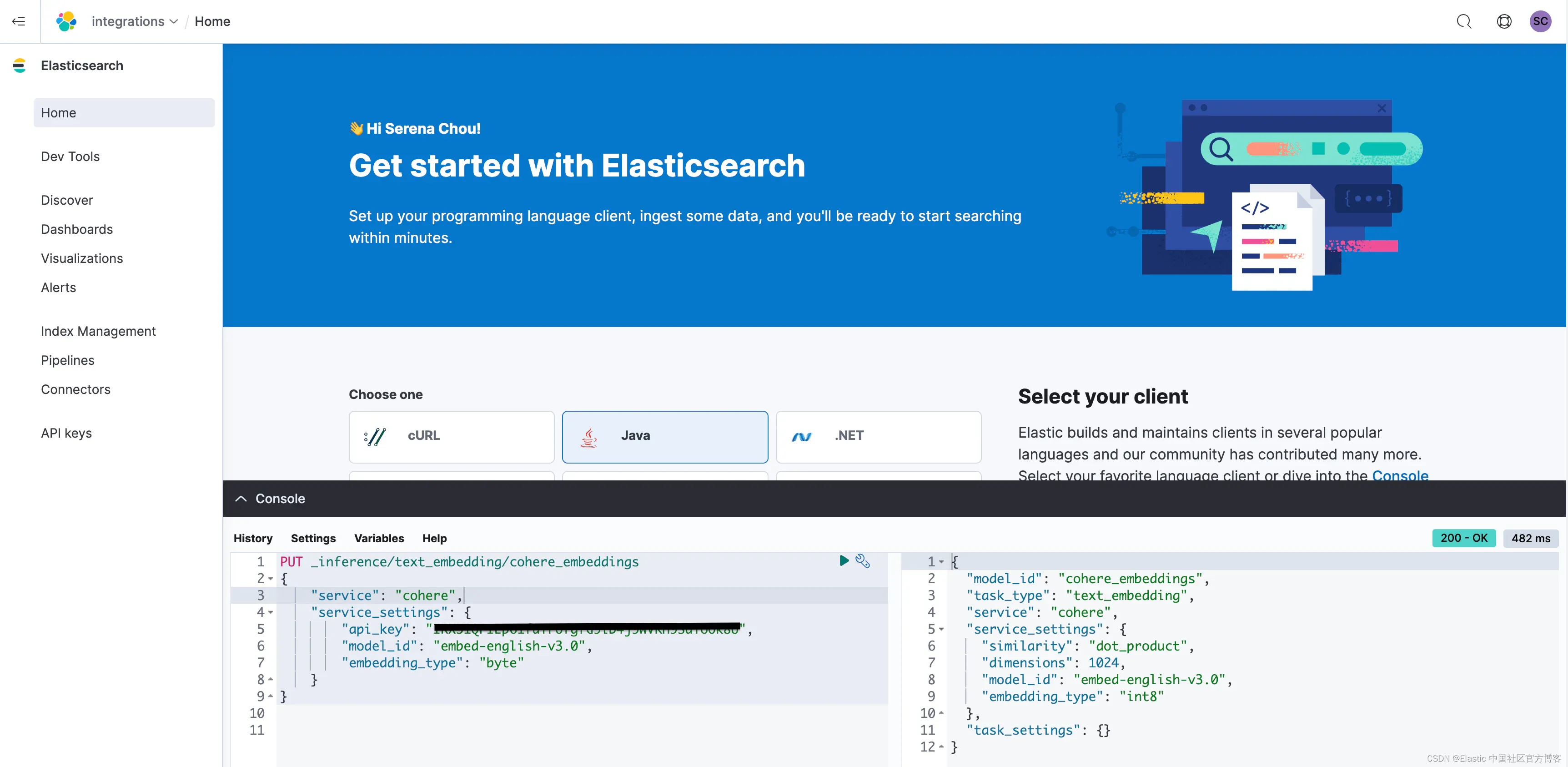
Elasticsearch 开放 inference API 增加了对 Cohere Embeddings 的支持
作者:来自 Elastic Serena Chou, Jonathan Buttner, Dave Kyle 我们很高兴地宣布 Elasticsearch 现在支持 Cohere 嵌入! 发布此功能是与 Cohere 团队合作的一次伟大旅程,未来还会有更多合作。 Cohere 是生成式 AI 领域令人兴奋的创新者,我们很自豪能够让开发人员使用 Cohere 令人难以置信。 Elastic

Spring AI Embeddings 和 Vector 入门
在前面 Spring AI Chat 简单示例 中介绍了 Chat 的基本用法,本文在此基础(主要是pom.xml)上继续探索 Embedding 和 Vector。 官方文档: embeddings: https://docs.spring.io/spring-ai/reference/api/embeddings/openai-embeddings.htmlredis: https:/
Embeddings技术简介:多维空间映射及其应用前景
嵌入技术:定义与应用 嵌入技术(Embeddings)是一种将内容转化为固定长度的浮点数数组的技术,这些数组代表内容在多维空间中的坐标,能够捕捉内容的语义意义。嵌入技术在相关内容推荐、语义搜索、代码搜索等领域有着广泛的应用。 嵌入技术的工作原理 嵌入模型通过将文本或其他类型的内容转换为数值数组,使得内容在多维空间中的位置能够表示其语义含义。例如,使用OpenAI的text-embedding
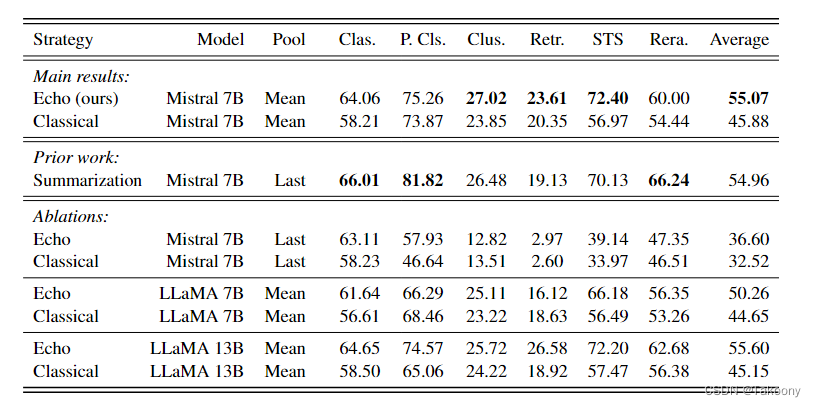
Repetition Improves Language Model Embeddings
论文结论: echo embeddings将句子重复拼接送入到decoder-only模型中,将第二遍出现的句子特征pooling作为sentence embedding效果很好,优于传统方法 echo embeddings与传统embedding方法区别,如图所示: Classical embeddings: Feed sentence x to the language model
大型语言模型的语义搜索(二):文本嵌入(Text Embeddings)
在我写的上一篇博客:关键词搜索中,我们解释了关键词搜索(Keyword Search)的技术,它通过计算问题和文档中重复词汇的数量,来搜索与问题相关的文档,常用的关键词搜索算法是Okapi BM25,简称BM25,关键词搜索算法的局限性在与它并不是根据文本本身的语义来进行文档搜索的,当文档与问题在语义上相关,但它们之间却没有重复词汇时,关键词搜索算法失效,它将无法搜索到该相关文档。为了解决这个

AIGC基础:大型语言模型 (LLM) 为什么使用向量数据库,嵌入(Embeddings)又是什么?
嵌入: 它是指什么?嵌入是将数据(例如文本、图像或代码)转换为高维向量的数值表示。这些向量捕捉了数据点之间的语义含义和关系。可以将其理解为将复杂数据翻译成 LLM 可以理解的语言。为什么有用?原始数据之间的相似性反映在高维空间中对应向量之间的距离上。这允许 LLM: 查找相似的数据:通过搜索与查询向量相近的向量,LLM 可以检索与问答、文本生成或推荐系统等任务相关的有用信息。理解上下文:通过将查
大语言模型LLM Large Language Model 的涌现Emergence 反馈强化学习 RLHF 预训练 token word embeddings 温度 temperature=0.7
1. Large Language Model(大型语言模型) Large Language Model(大型语言模型)是指具有大规模参数数量和处理能力的语言模型。这些模型通过深度学习技术训练,能够处理和生成自然语言文本。 大型语言模型在自然语言处理领域发挥着重要作用,它们能够理解和生成文本,执行语言相关的任务,如机器翻译、文本摘要、情感分析、对话系统等。这些模型的训练基于大量的文本数据集,使
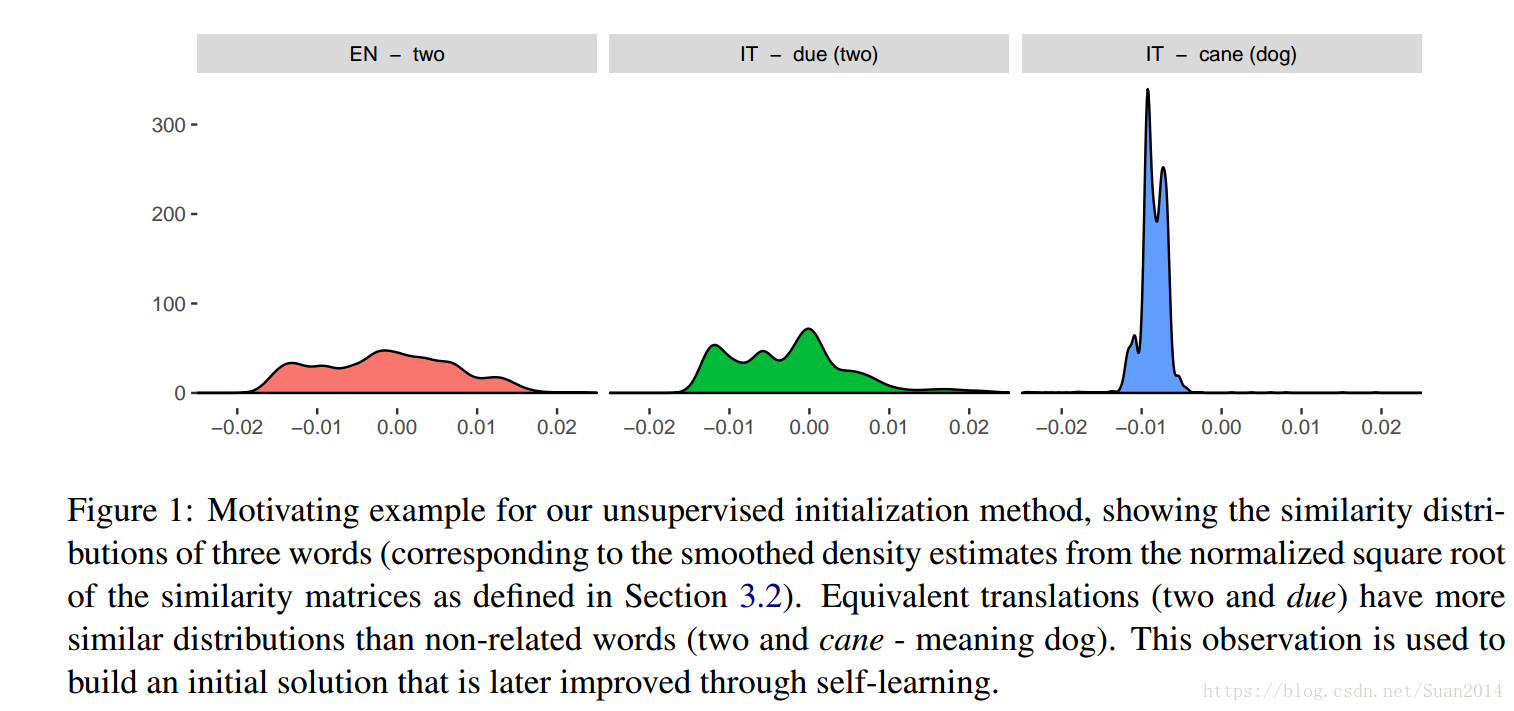
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings论文笔记
回看前几篇笔记发现我剪贴的公式显示很乱,虽然编辑时调整过了,但是不知道为什么显示的和编辑时的不一样,为方便大家的阅读,我开始尝试着采用markdown的形式写笔记,前几篇有时间的话再修改。 这篇论文阅读完,我依然有很多不懂的地方,对其操作不是很清晰,因为我没做过这方面的内容,且近期估计没时间学习其项目,所以记录理解的可能有误,希望大家带着思考阅读。 PS:感觉这篇文章的作者是这个方向的大神呢,
快速入门:使用 Gemini Embeddings 和 Elasticsearch 进行向量搜索
Gemini 是 Google DeepMind 开发的多模态大语言模型家族,作为 LaMDA 和 PaLM 2 的后继者。由 Gemini Ultra、Gemini Pro 和 Gemini Nano 组成,于 2023 年 12 月 6 日发布,定位为 OpenAI 的竞争者 GPT-4。 本教程演示如何使用 Gemini API 创建嵌入并将其存储在 Elasticsearch 中。

Embeddings: What they are and why they matter
embeddings 是什么意思https://simonwillison.net/2023/Oct/23/embeddings/推荐原因:GPT 模型的基础是一种叫做 embeddings 的技术,用来将文本转换成向量,从而可以计算出文本之间的相似度。这篇文章详细地介绍了embeddings及应用 Embeddings are a really neat trick that often co

【论文笔记】Active Domain Adaptation via Clustering Uncertainty-weighted Embeddings(ICCV2021)
论文:Active Domain Adaptation via Clustering Uncertainty-Weighted Embeddings 代码:https://github.com/virajprabhu/CLUE 本人计算机视觉研究僧,欢迎交流。 Abstract 本文通过主动学习方式,解决在域适应问题(Domain adaptation)中,选择信息量最大的目标域(target

卷积神经网络和Word Embeddings 在中文分词领域的应用
Convolutional Neural Network withWord Embeddings for Chinese Word Segmentation 近年来,许多基于特征的神经模型已被应用于CWS。虽然已经有很好的表现了,但是都有两大缺点:第一,分词模型很大程度需要依赖人工设计bigram特征,不能自动捕获n-gram特征。第二,分词模型不能最大程度上使用完整的字信息。 基于第一个缺
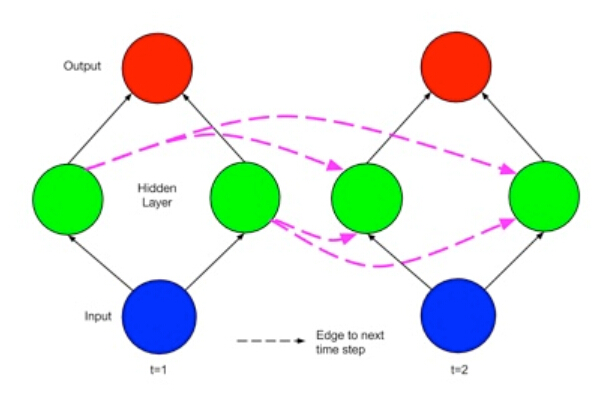
Theano-Deep Learning Tutorials 笔记:Recurrent Neural Networks with Word Embeddings
教程地址:http://deeplearning.net/tutorial/rnnslu.html 相关论文:Grégoire Mesnil, Xiaodong He, Li Deng and Yoshua Bengio - Investigation of Recurrent Neural Network Architectures and Learning Methods for Spoke
【Airbnb搜索】:Real-time Personalization using Embeddings for Search Ranking at Airbnb
原始论文下载地址: 本文是kdd 2018 的best paper,文章来自airbnb的搜索推荐团队,描述的是airbnb如何使用embedding来提高搜索和排序的效果。 知乎有官方认证的中文文章(文章地址,原始论文)。文章利用搜索的session数据来获取Listing和用户的embedding,全文思想相对来说还是比较简单的,但是整体针对业务实际情况,一步步的解决问题的思路很清晰,和a
![[论文翻译] Improving Knowledge Tracing via Pre-training Question Embeddings](https://img-blog.csdnimg.cn/9459c2c857ef406e9802f66451fe4cf6.png)
[论文翻译] Improving Knowledge Tracing via Pre-training Question Embeddings
摘要 知识追踪 (KT) 定义了根据学生的历史反应预测他们是否能正确回答问题的任务。尽管许多研究致力于利用问题信息,但问题和技能中的大量高级信息尚未被很好地提取,这使得以前的工作难以充分执行。在本文中,我们证明了通过在丰富的边信息上为每个问题预训练嵌入,然后在获得的嵌入上训练深度 KT 模型,可以实现 KT 的巨大收益。具体而言,边信息包括问题难度和问题与技能二分图中包含的三种关系。为了预训练问
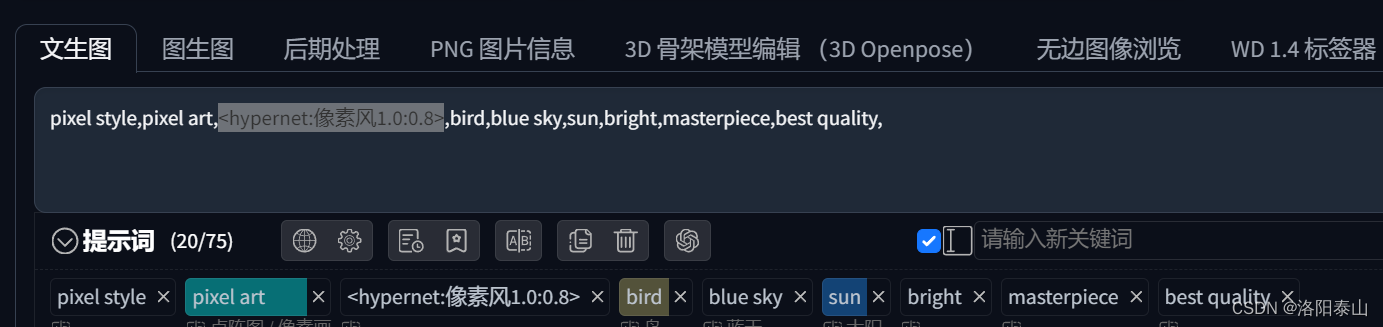
AI 绘画 | Stable Diffusion 进阶 Embeddings(词嵌入)、LoRa(低秩适应模型)、Hypernetwork(超网络)
前言 Stable Diffusion web ui,除了依靠文生图(即靠提示词生成图片),图生图(即靠图片+提示词生成图片)外,这两种方式还不能满足我们所有的绘图需求,于是就有了 Embeddings(词嵌入)、LoRa(低秩适应模型)、Hypernetwork(超网络)。 Embeddings模型 模型非常小,常常用于放在反向提示词里,让图像不出现生么,当然也可与用于正向提示词,生成我们想
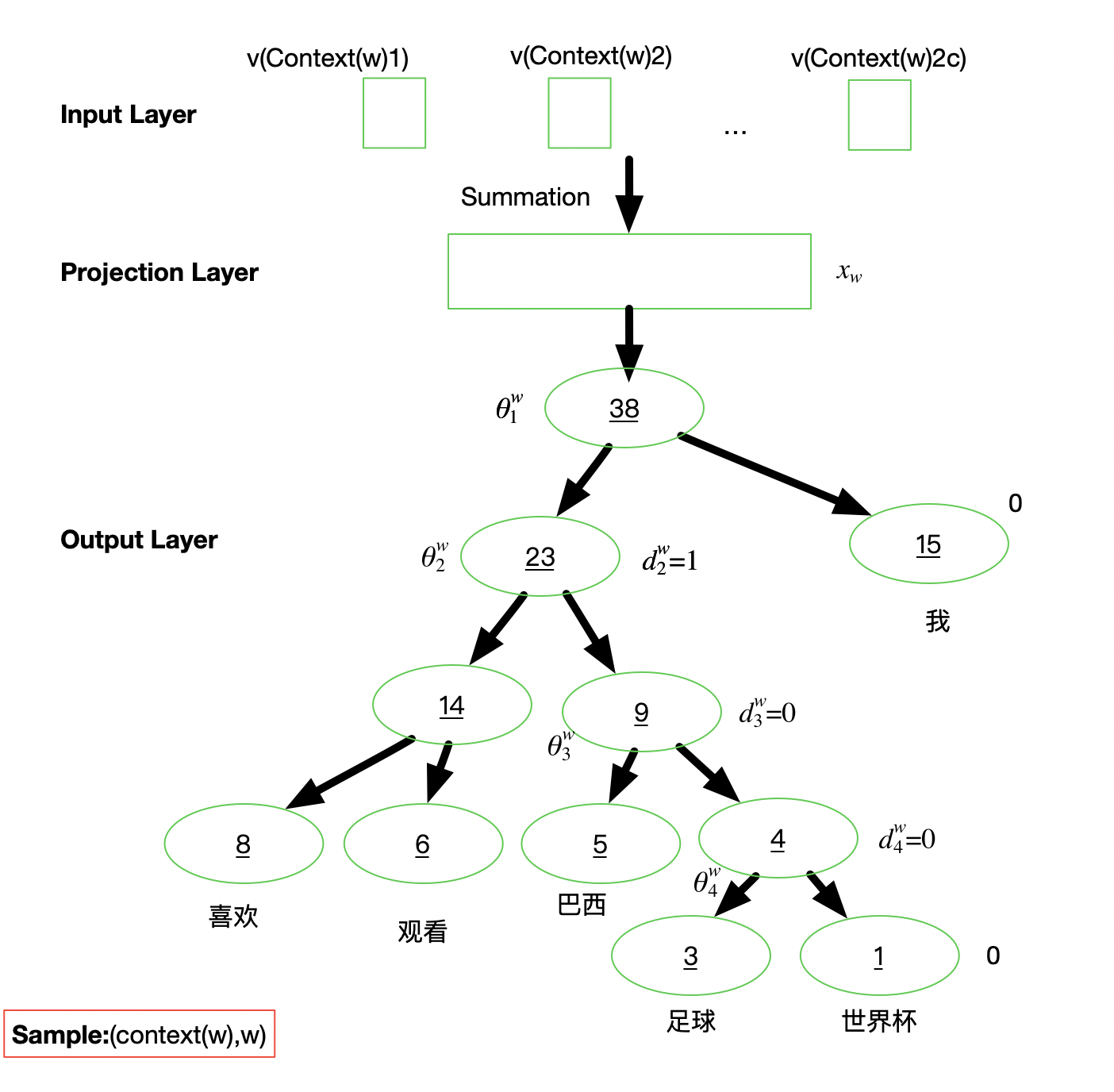
PyTorch笔记 - Word Embeddings Word2vec 原理与源码
欢迎关注我的CSDN:https://blog.csdn.net/caroline_wendy 本文地址:https://blog.csdn.net/caroline_wendy/article/details/128227529 语言建模 基于已有的人类组织的文本语料,来去无监督学习如何组织一句话,并还能得到单词的语义表征。统计模型:n-gram,N个单词所构成的序列,在文档中出现的次