本文主要是介绍PyTorch笔记 - Word Embeddings Word2vec 原理与源码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎关注我的CSDN:https://blog.csdn.net/caroline_wendy
本文地址:https://blog.csdn.net/caroline_wendy/article/details/128227529
语言建模
- 基于已有的人类组织的文本语料,来去无监督学习如何组织一句话,并还能得到单词的语义表征。
- 统计模型:n-gram,N个单词所构成的序列,在文档中出现的次数,基于贝叶斯公式。
- 无监督学习:NNLM(Neural Network Language Model)《A Neural Probabilistic Language Model》,Neural Network + n-gram
- 大规模无监督学习:word2vec、BERT(Bidirectional Encoder Representations from Transformers)
n-gram模型
- 特点:统计性、简单、泛化能力差、无法得到单词的语义信息
- 定义:n个相邻字符构成的序列
- uni-gram,单一单词
- bi-gram,两个单词
- tri-gram,三个单词
- 用途:基于n-gram的频数分析文本,如垃圾邮件分类
- 对于word n-gram(基于单词),特征维度随着语料词汇增大和n增大而指数增大(curse of dimensionality,维度灾难)
- 对于character n-gram(基于字母),特征维度只随着n增大而增大
单词的语义表征
- 稀疏式:one-hot encoding,只有1个位置上的元素是1,只能反应单词在单词表中的位置,维度很长,不利于计算。
- 分布式:类似于word embedding,连续浮点型的向量,维度是固定的,隐式的语义表征。
- 应用场景:
- word/character/phrase/sentence/paragraph embedding
- speaker/user/item embedding
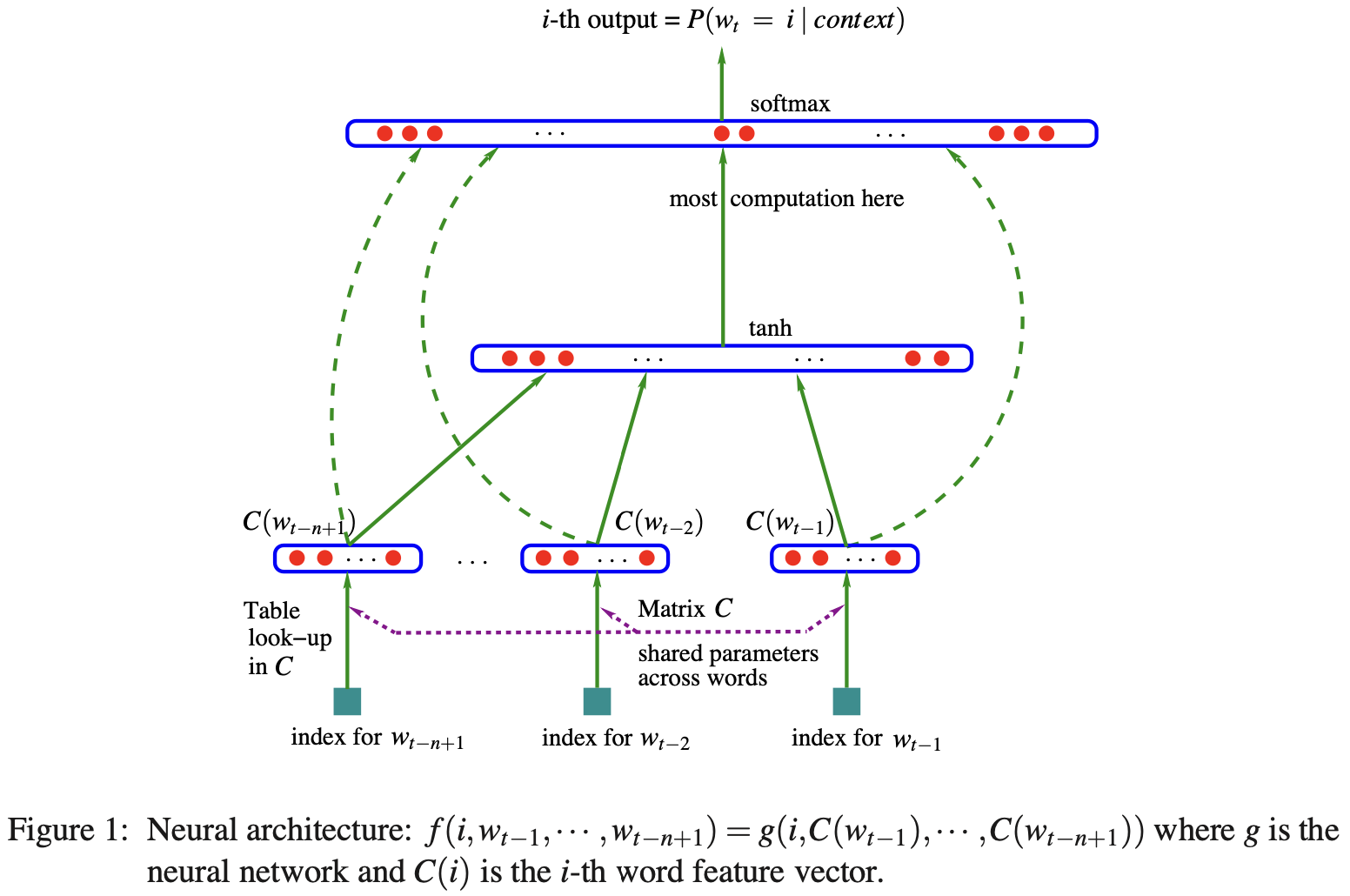
基于神经网络的语言模型(NNLM)
- 由Bengio(CA,University of California,加州大学)提出,解决Curse of Dimensionality问题。
- NNLM包含:
- 输入层(one-hot),排列矩阵
- 投影层,查询embedding table,将离散的index转换为连续的向量表示。
- 隐含层,映射为隐含层
- 输出层,映射到大小为单词表数量的embedding之上。
- word embeddings是副产物,隐含的语义表征
- 主要复杂度:
N*D*H + H*V - 如何降低复杂度,如何训练大数据,2010年左右面临的问题
Word2vec模型
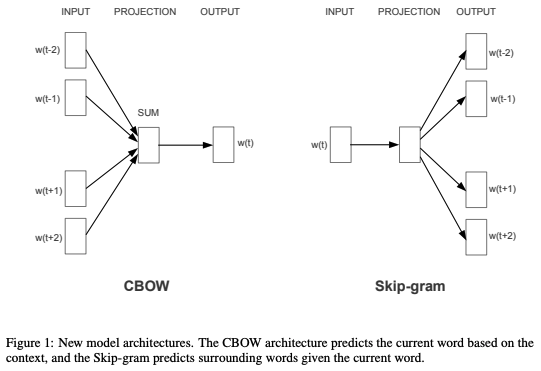
- 改进1:抛弃隐含层,并提出CBOW和Skip-gram
- Continuous Bag-of-Words(CBOW)连续词袋算法,与BERT类似
- 不同于NNLM,CBOW考虑到了前后上下文
- 使用周围单词预测中间单词
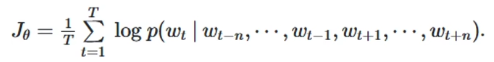
- Skip-gram
- 与CBOW相反,使用中间单词预测周围单词,判断两个单词是否为相邻单词
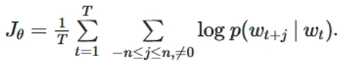
- 论文《Efficient Estimation of Word Representations in Vector Space》,Tomas Mikolov,CA
Word2vec模型
-
改进2:优化Softmax
-
Softmax计算量跟K呈线性关系,单词维度
-
Hierarchical Softmax,参考详解Hierarchical Softmax,Huffman树
- l o g 2 K log_2K log2K次的二分类
- N个单词,N个节点
- 选择权重最小的2个单词,合并一课树的左右子树
- 重复筛选。
- 统计全部单词出现的次数,构建Huffman树的权重,

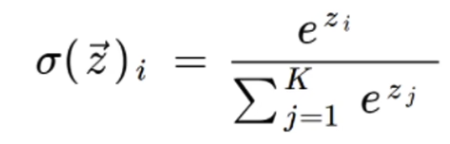
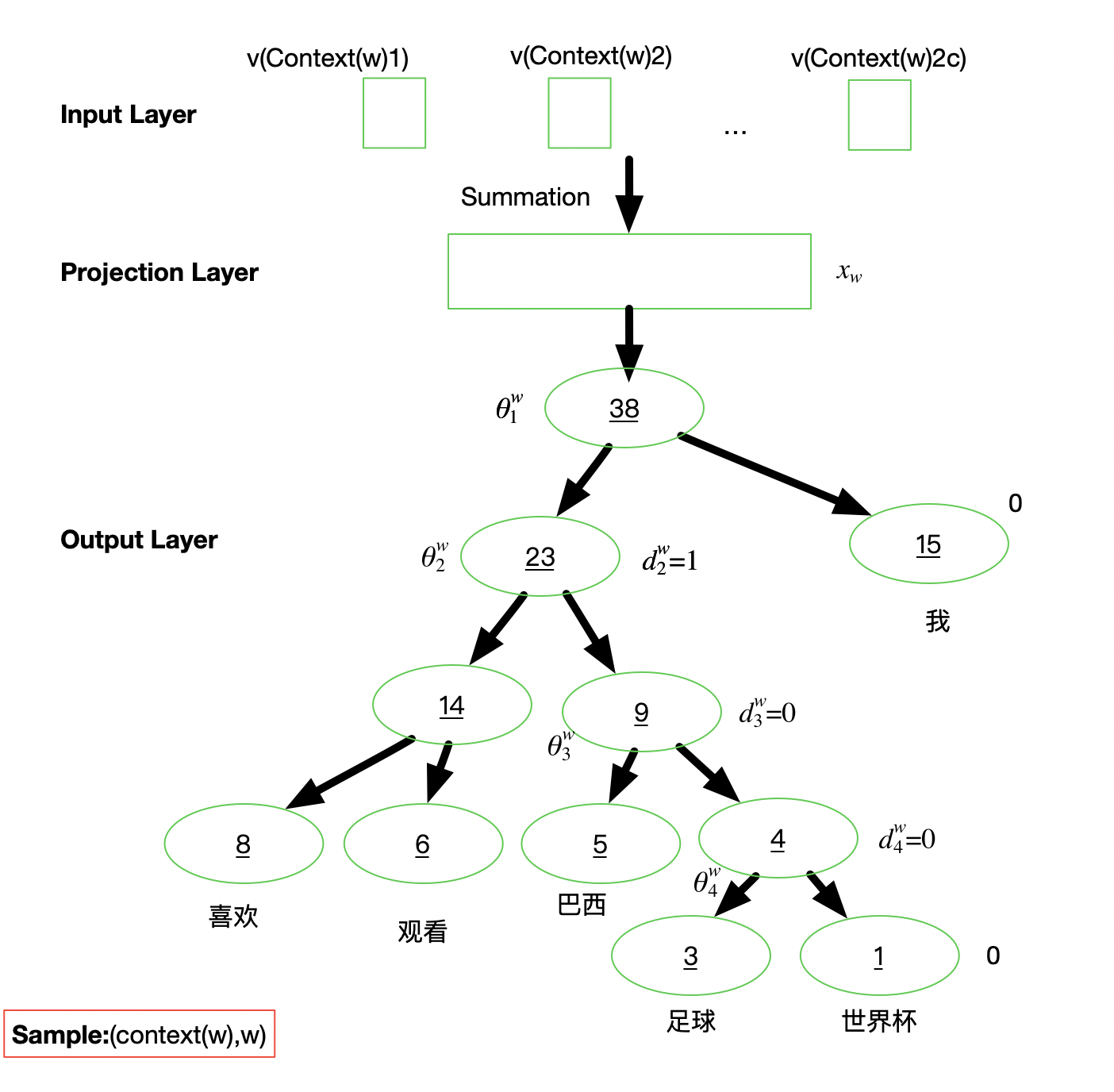
基于H-Softmax的word2vec
- Continuous Bog of Words (CBOW)
- 输入:前n个单词和后n个单词
- 目标:基于H-Softmax预测中间单词
- Skip-gram
- 输入:中间单词
- 目标:基于H-Softmax预测前n个单词和后n个单词
这篇关于PyTorch笔记 - Word Embeddings Word2vec 原理与源码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





