word2vec专题

基于Python的自然语言处理系列(1):Word2Vec
在自然语言处理(NLP)领域,Word2Vec是一种广泛使用的词向量表示方法。它通过将词汇映射到连续的向量空间中,使得计算机可以更好地理解和处理文本数据。本系列的第一篇文章将详细介绍Word2Vec模型的原理、实现方法及应用场景。 1. Word2Vec 原理 Word2Vec模型由Google的Tomas Mikolov等人在2013年提出,主要有两种训练方式

第23周:使用Word2vec实现文本分类
目录 前言 一、数据预处理 1.1 加载数据 1.2 构建词典 1.3 生成数据批次和迭代器 二、模型构建 2.1 搭建模型 2.2 初始化模型 2.3 定义训练和评估函数 三、训练模型 3.1 拆分数据集并运行模型 3.2 测试指定数据 总结 前言 🍨 本文为[🔗365天深度学习训练营]中的学习记录博客🍖 原作者:[K同学啊] 说在前面 本周任务
每天一个数据分析题(五百二十七)- word2vec模型
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。关于word2vec模型,下面说法不正确的是: A. 得到的词向量维度小,可以节省存储和计算资源 B. 考虑了全局语料库的信息 C. 无法解决多义词的问题 D. 可以表示词和词之间的关系 数据分析认证考试介绍:点击进入 数据分析考试大纲下载 题目来源于CDA模拟题库 点

word2vec 两个模型,两个加速方法 负采样加速Skip-gram模型 层序Softmax加速CBOW模型 item2vec 双塔模型 (DSSM双塔模型)
推荐领域(DSSM双塔模型): https://www.cnblogs.com/wilson0068/p/12881258.html word2vec word2vec笔记和实现 理解 Word2Vec 之 Skip-Gram 模型 上面这两个链接能让你彻底明白word2vec,不要搞什么公式,看完也是不知所云,也没说到本质. 目前用的比较多的都是Skip-gram模型 Go

word2vec 自己训练中文语料
(1) 准备文本 可以用爬虫爬,也可以去下载,必须是全文本。 (2)对数据进行分词处理 因为英文但此只见是空格所以不需要分词,二中文需要分词, 中文分词工具还是很多的,我自己常用的: - 中科院NLPIR - 哈工大LTP - 结巴分词 注意:分词后保存的文件将会作为word2vec的输入文件进行训练 (3)训练与实验 python 需要先安装gensim,参考http://bl

word2vec python使用
(1)安装gensim pip install --upgrade setuptoolspip install gensimsudo pip install pattern (2)使用上次训练好的词向量vectors.bin vectors.bin 的生成参考http://blog.csdn.net/u013378306/art

word2vec centos 安装
google的下载地址国内已无法连接,下载地址http://download.csdn.net/detail/u013378306/9741439 安装步骤 1、下载word2vec,其目录结构如下: 2、进入word2vec所在目录,使用make指令进行安装 make 可以发现在安装的时候,会出现如下error: gcc word2ve

word2vec 入门基础(一)
一、基本概念 word2vec是Google在2013年开源的一个工具,核心思想是将词表征映 射为对应的实数向量。 目前采用的模型有一下两种 CBOW(Continuous Bag-Of-Words,即连续的词袋模型)Skip-Gram 项目链接:https://code.google.com/archive/p/word2vec 二、背景知识 词向量 词向量就是用来将语言中的词进
word2vec 入门(二)
word2vec 要解决问题: 在神经网络中学习将word映射成连续(高维)向量,这样通过训练,就可以把对文本内容的处理简化为K维向量空间中向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。 一般来说, word2vec输出的词向量可以被用来做很多 NLP 相关的工作,比如聚类、找同义词、词性分析等等。另外还有其向量的加法组合算法。官网上的例子是 : vector('Paris'
每天一个数据分析题(五百一十九)- Word2vec
Word2vec,是一群用来产生词向量的相关模型,用来训练以重新建构语言学之词文本。Word2Vec包含哪两种模型? A. CBOW模型和Skip-Gram模型 B. Bag-of-Words和GloVe模型 C. LSA模型和CBOW模型 D. GloVe模型和CBOW模型 数据分析认证考试介绍:点击进入 数据分析考试大纲下载 题目来源于CDA模拟题库 点击此处获取答案

Trm理论 2(Word2Vec)
神经网络模型(NNLM)和Word2Vec NNLM模型是上次说过的模型,其目的是为了预测下一个词。 softmax(w2tanh(w1x + b1)+b2) 会得到一个副产品词向量 而Word2Vue就是专门求词向量的模型 softmax(w2*(w1*x + b1)+b2) Word2Vec softmax(w2*(w1*x + b1)+b2),Word2vec比NNLM少了一个激活函数

NLP-词向量-发展:词袋模型【onehot、tf-idf】 -> 主题模型【LSA、LDA】 -> 词向量静态表征【Word2vec、GloVe、FastText】 -> 词向量动态表征【Bert】
NLP-词向量-发展: 词袋模型【onehot、tf-idf】主题模型【LSA、LDA】基于词向量的静态表征【Word2vec、GloVe、FastText】基于词向量的动态表征【Bert】 一、词袋模型(Bag-Of-Words) 1、One-Hot 词向量的维数为整个词汇表的长度,对于每个词,将其对应词汇表中的位置置为1,其余维度都置为0。 缺点是: 维度非常高,编码过于稀疏,易出

GNN-静态表征-随机游走-2014:DeepWalk【步骤:①随机游走策略生成每个节点的训练序列(DFS),得到训练数据集;②套用Word2vec算法得到节点表示】【捕获二阶相似度】【浅层、同质图】
一、概述 1、 2、DeepWalk、LINE、Node2vec对比 提出的顺序DeepWalk 2014, UNE 2015, Node2Vec 2016 Node2Vec设置 p = q = 1 p=q =1
自然语言处理系列四十八》Word2vec词向量模型》算法原理
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列四十八Word2vec词向量模型》算法原理Word2vec词向量模型》代码实战 总结 自然语言处理系列四十八 Word2vec词向量模型》算法原理 Google开源了一款用于词向量计算的工具——Wo

Word2Vec之Skip-Gram与CBOW模型
Word2Vec之Skip-Gram与CBOW模型 word2vec是一个开源的nlp工具,它可以将所有的词向量化。至于什么是词向量,最开始是我们熟悉的one-hot编码,但是这种表示方法孤立了每个词,不能表示词之间的关系,当然也有维度过大的原因。后面发展出一种方法,术语是词嵌入。 [1.词嵌入] 词嵌入(Word Embedding)是NL

第22周:调用Gensim库训练Word2Vec模型
目录 前言 一、Word2vec基本知识 1.1 Word2Vec是什么 1.2 Word2Vec两种主要模型架构 1.2.1 CBOW模型 1.2.2 Skip-gram模型 1.3 实例说明 1.4 调用方法 二、准备工作 2.1 安装Gensim库 2.2 对原始语料分词 2.2 添加自定义停用词 三、训练Word2Vec模型 四、模型应用 4.1 计算词汇相似

spark Word2Vec+LSH相似文本推荐(scala)
在上一篇博客,我们使用spark CountVectorizer与IDF进行了关键词提取,博客地址: spark CountVectorizer+IDF提取中文关键词(scala) 本篇博客在上一篇博客的基础上,介绍如何根据关键词获取文档的相似度,进行相似文本的推荐。在这里我们需要使用到两个算法:Word2Vec与LSH。 其中Word2Vec即将词转换为词向量,这样词之间的关系就可以向量距
word2Vec 获取训练好后所有的词
import gensimsentences = [['first', 'sentence',], ['second', 'sentence'],['haha','sentence']]# train word2vec on the two sentencesmodel = gensim.models.Word2Vec(sentences) 在gensim 1.0.0 以前的版本可以使用:
深度学习100问9-什么是word2vec模型
Word2vec 模型是一种用于将词语转换为向量表示的工具。 想象一下,我们有很多很多的词语,就像一个个不同的小盒子。Word2vec 模型的作用就是给每个小盒子都找到一个对应的位置,这个位置用一个向量来表示。这样,意思相近的词语在这个“向量空间”里就会离得比较近。 比如“猫”和“狗”,因为它们都是宠物,所以在 Word2vec 生成的向量空间中,它们对应的向量距离就会比较近。而“猫”和“

CS224N连载系列_word2vec作业的解析(2)
所有的语言模型的发展都离不开最基础的模型,统计语言模型是最重要的一环,word2vec也是如此,统计语言模型是用来计算一个句子的概率的概率模型,通常是基于一个语料库来构建,那什么叫一个句子的概率呢? 1、softmax softmax 函数通常处理机器学习分类问题的输出层的激活函数,它的输入是一个实数向量,输出向量的长度是与输入向量相同,但所有的取值范围是(0,1),且所有元素的和为1,输出向

自己动手写word2vec (一):主要概念和流程
转https://blog.csdn.net/u014595019/article/details/51884529 word2vec 是 Google 于 2013 年开源推出的一个用于获取词向量(word vector)的工具包,它简单、高效,因此引起了很多人的关注。我在看了@peghoty所写的《word2vec中的数学以后》(个人觉得这是很好的资料,各方面知识很全面,不像网上大部分有

word2vec and glove优缺点
传统方法 假设我们有一个足够大的语料库(其中包含各种各样的句子,比如维基百科词库就是很好的语料来源) 那么最笨(但很管用)的办法莫过于将语料库里的所有句子扫描一遍,挨个数出每个单词周围出现其它单词的次数,做成下面这样的表格就可以了。 假设矩阵是5W*5W维,矩阵运算量巨大。假设矩阵的每个数字都用标准32位Int表示,需要10,000,000,000个byte,也就是10GB的内存(且随着词

Word2Vec、GloVe、Fasttext等背后的思想简介
超长文, 建议收藏之后慢慢观看~ 1Efficient Estimation of Word Representations in Vector Space 本文是 word2vec 的第一篇, 提出了大名鼎鼎的 CBOW 和 Skip-gram 两大模型. 由于成文较早, 本文使用的一些术语有一些不同于现在的叫法, 我都替换为了现在的叫法. CBOW 的架构如下所示. 与作者提到的 feedfo
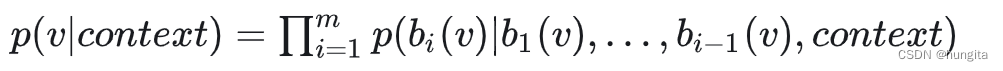
面试:关于word2vec的相关知识点Hierarchical Softmax和NegativeSampling
1、为什么需要Hierarchical Softmax和Negative Sampling 从输入层到隐含层需要一个维度为N×K的权重矩阵,从隐含层到输出层又需要一个维度为K×N的权重矩阵,学习权重可以用反向传播算法实现,每次迭代时将权重沿梯度更优的方向进行一小步更新。但是由于Softmax激活函数中存在归一化项的缘故,推导出来的迭代公式需要对词汇表中的所有单词进行遍历,使得每次迭代过程非常缓慢
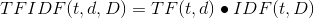
SparkML中三种文本特征提取算法(TF-IDF/Word2Vec/CountVectorizer)
在SparkML中关于特征的算法可分为Extractors(特征提取)、Transformers(特征转换)、Selectors(特征选择)三部分: Feature Extractors TF-IDFWord2VecCountVectorizer Feature Transformers TokenizerStopWordsRemover n n-gramBinarizerP

Word2Vec揭秘: 这是深度学习中的一小步,却是NLP中的巨大跨越
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Suvro Banerjee 编译:ronghuaiyang 前戏 做NLP现在离不开词向量,词向量给了我们一个非常好的单词的向量表示,用一个有限长度的向量,可以表示出所有的词,还可以表示出词与词之间的上下文相互关系,是不是很神奇?那么,这么神奇的东西到底是怎么来的呢?今天的这篇文章会一点一点给大家说清楚。虽然有一点公式,但是总