本文主要是介绍SparkML中三种文本特征提取算法(TF-IDF/Word2Vec/CountVectorizer),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在SparkML中关于特征的算法可分为Extractors(特征提取)、Transformers(特征转换)、Selectors(特征选择)三部分:
- Feature Extractors
- TF-IDF
- Word2Vec
- CountVectorizer
- Feature Transformers
- Tokenizer
- StopWordsRemover
- n -gram
- Binarizer
- PCA
- PolynomialExpansion
- Discrete Cosine Transform (DCT)
- StringIndexer
- IndexToString
- OneHotEncoder
- VectorIndexer
- Interaction
- Normalizer
- StandardScaler
- MinMaxScaler
- MaxAbsScaler
- Bucketizer
- ElementwiseProduct
- SQLTransformer
- VectorAssembler
- QuantileDiscretizer
- Feature Selectors
- VectorSlicer
- RFormula
- ChiSqSelector
本篇文章主要对特征提取(Extracting)的3种算法(TF-IDF、Word2Vec以及CountVectorizer)结合Demo进行一下理解
TF-IDF算法介绍:
词频-逆向文件频率(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。
词语由t表示,文档由d表示,语料库由D表示。词频TF(t,,d)是词语t在文档d中出现的次数。文件频率DF(t,D)是包含词语的文档的个数。如果我们只使用词频来衡量重要性,很容易过度强调在文档中经常出现而并没有包含太多与文档有关的信息的词语,比如“a”,“the”以及“of”。如果一个词语经常出现在语料库中,它意味着它并没有携带特定的文档的特殊信息。逆向文档频率数值化衡量词语提供多少信息:
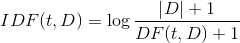
其中,|D|是语料库中的文档总数。由于采用了对数,如果一个词出现在所有的文件,其IDF值变为0。
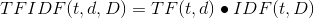
在下面的代码段中,我们以一组句子开始。首先使用分解器Tokenizer把句子划分为单个词语。对每一个句子(词袋),我们使用HashingTF将句子转换为特征向量,最后使用IDF重新调整特征向量。这种转换通常可以提高使用文本特征的性能。
词频(Term Frequency):某关键词在文本中出现次数
逆文档频率(Inverse Document Frequency):大小与一个诩的常见程度成反比
TF = 某个词在文章中出现的次数/文章的总词数
IDF = log(查找的文章总数 / (包含该词的文章数 + 1))
TF-IDF = TF(词频) x IDF(逆文档频率)
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.ml.feature.HashingTF;
import org.apache.spark.ml.feature.IDF;
import org.apache.spark.ml.feature.IDFModel;
import org.apache.spark.ml.feature.Tokenizer;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;import java.util.Arrays;
import java.util.List;public class MyTFIDF {public static void main(String[] args){SparkConf conf = new SparkConf().setAppName("TF-IDF").setMaster("local");JavaSparkContext sc = new JavaSparkContext(conf);SQLContext sqlContext = new SQLContext(sc);List<Row> data = Arrays.asList(RowFactory.create(0.0, "Hi I heard about Spark"),RowFactory.create(0.0, "I wish Java could use case classes"),RowFactory.create(1.0, "Logistic regression models are neat"));StructType schema = new StructType(new StructField[]{new StructField("label", DataTypes.DoubleType, false, Metadata.empty()),new StructField("sentence", DataTypes.StringType, false, Metadata.empty())});Dataset<Row> sentenceData = sqlContext.createDataFrame(data, schema);Tokenizer tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words");Dataset<Row> wordsData = tokenizer.transform(sentenceData);int numFeatures = 20;HashingTF hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(numFeatures);Dataset<Row> featurizedData = hashingTF.transform(wordsData);// alternatively, CountVectorizer can also be used to get term frequency vectorsIDF idf = new IDF().setInputCol("rawFeatures").setOutputCol("features");IDFModel idfModel = idf.fit(featurizedData);Dataset<Row> rescaledData = idfModel.transform(featurizedData);rescaledData.select("label", "features").show(false);//+-----+----------------------------------------------------------------------------------------------------------------------+
//|label|features |
//+-----+----------------------------------------------------------------------------------------------------------------------+
//|0.0 |(20,[0,5,9,17],[0.6931471805599453,0.6931471805599453,0.28768207245178085,1.3862943611198906]) |
//|0.0 |(20,[2,7,9,13,15],[0.6931471805599453,0.6931471805599453,0.8630462173553426,0.28768207245178085,0.28768207245178085]) |
//|1.0 |(20,[4,6,13,15,18],[0.6931471805599453,0.6931471805599453,0.28768207245178085,0.28768207245178085,0.6931471805599453])|
//+-----+----------------------------------------------------------------------------------------------------------------------+sc.stop();}
}Word2Vec算法介绍:
Word2vec是一个Estimator,它采用一系列代表文档的词语来训练word2vecmodel。该模型将每个词语映射到一个固定大小的向量。word2vecmodel使用文档中每个词语的平均数来将文档转换为向量,然后这个向量可以作为预测的特征,来计算文档相似度计算等等。
在下面的代码段中,我们首先用一组文档,其中每一个文档代表一个词语序列。对于每一个文档,我们将其转换为一个特征向量。此特征向量可以被传递到一个学习算法。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.ml.feature.Word2Vec;
import org.apache.spark.ml.feature.Word2VecModel;
import org.apache.spark.ml.linalg.Vector;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.*;import java.util.Arrays;
import java.util.List;public class MyWord2Vector {public static void main(String[] args){SparkConf conf = new SparkConf().setAppName("Word2Vector").setMaster("local");JavaSparkContext sc = new JavaSparkContext(conf);SQLContext sqlContext = new SQLContext(sc);// Input data: Each row is a bag of words from a sentence or document.List<Row> data = Arrays.asList(RowFactory.create(Arrays.asList("Hi I heard about Spark".split(" "))),RowFactory.create(Arrays.asList("I wish Java could use case classes".split(" "))),RowFactory.create(Arrays.asList("Logistic regression models are neat".split(" "))));StructType schema = new StructType(new StructField[]{new StructField("text", new ArrayType(DataTypes.StringType, true), false, Metadata.empty())});Dataset<Row> documentDF = sqlContext.createDataFrame(data, schema);// Learn a mapping from words to Vectors.Word2Vec word2Vec = new Word2Vec().setInputCol("text").setOutputCol("result").setVectorSize(1).setMinCount(0);Word2VecModel model = word2Vec.fit(documentDF);Dataset<Row> result = model.transform(documentDF);for(Row row : result.collectAsList()){List<String> text = row.getList(0);Vector vector = (Vector)row.get(1);System.out.println("Text: " + text + "\t=>\t Vector: " + vector);}//Text: [Hi, I, heard, about, Spark] => Vector: [-0.02205655723810196]
//Text: [I, wish, Java, could, use, case, classes] => Vector: [-0.009554644780499595]
//Text: [Logistic, regression, models, are, neat] => Vector: [-0.12159877410158515]sc.stop();}
}CountVectorizer算法介绍:
Countvectorizer和Countvectorizermodel旨在通过计数来将一个文档转换为向量。当不存在先验字典时,Countvectorizer可作为Estimator来提取词汇,并生成一个Countvectorizermodel。该模型产生文档关于词语的稀疏表示,其表示可以传递给其他算法如LDA。在fitting过程中,countvectorizer将根据语料库中的词频排序选出前vocabsize个词。一个可选的参数minDF也影响fitting过程中,它指定词汇表中的词语在文档中最少出现的次数。另一个可选的二值参数控制输出向量,如果设置为真那么所有非零的计数为1。这对于二值型离散概率模型非常有用。
示例:假设我们有一个DataFrame包含id和texts属性:
id | texts
----|----------0 | Array("a", "b", "c")1 | Array("a", "b", "b", "c", "a")
id | texts | vector
----|---------------------------------|---------------0 | Array("a", "b", "c") | (3,[0,1,2],[1.0,1.0,1.0])1 | Array("a", "b", "b", "c", "a") | (3,[0,1,2],[2.0,2.0,1.0])import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.ml.feature.CountVectorizer;
import org.apache.spark.ml.feature.CountVectorizerModel;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.*;import java.util.Arrays;
import java.util.List;public class MyCountVectorizer {public static void main(String[] args){SparkConf conf = new SparkConf().setAppName("CountVectorizer").setMaster("local");JavaSparkContext sc = new JavaSparkContext(conf);SQLContext sqlContext = new SQLContext(sc);// Input data: Each row is a bag of words from a sentence or document.//输入每一行都是一个文档类型的数组(字符串)List<Row> data = Arrays.asList(RowFactory.create(Arrays.asList("a", "b", "c")),RowFactory.create(Arrays.asList("a", "b", "b", "c", "a")));StructType schema = new StructType(new StructField[] {new StructField("text", new ArrayType(DataTypes.StringType, true), false, Metadata.empty())});Dataset<Row> df = sqlContext.createDataFrame(data, schema);// fit a CountVectorizerModel from the corpusCountVectorizerModel cvModel = new CountVectorizer().setInputCol("text").setOutputCol("feature").setVocabSize(3) //词典大小.setMinDF(2) //指定词汇表中的词语在文档中最少出现的次数.fit(df);cvModel.transform(df).show(false);//输出:每个向量代表文档的词汇表中每个词语出现的次数
//+---------------+-------------------------+
//|text |feature |
//+---------------+-------------------------+
//|[a, b, c] |(3,[0,1,2],[1.0,1.0,1.0])|
//|[a, b, b, c, a]|(3,[0,1,2],[2.0,2.0,1.0])|
//+---------------+-------------------------+sc.stop();}
}参考网址:
http://spark.apache.org/docs/latest/ml-features.html
这篇关于SparkML中三种文本特征提取算法(TF-IDF/Word2Vec/CountVectorizer)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




