sparkml专题
SparkML中三种文本特征提取算法(TF-IDF/Word2Vec/CountVectorizer)
在SparkML中关于特征的算法可分为Extractors(特征提取)、Transformers(特征转换)、Selectors(特征选择)三部分: Feature Extractors TF-IDFWord2VecCountVectorizer Feature Transformers TokenizerStopWordsRemover n n-gramBinarizerP

【SparkML系列2】DataSource读取图片数据
DataSource(数据源) 在本节中,我们将介绍如何在机器学习中使用数据源加载数据。除了一些通用的数据源,如 Parquet、CSV、JSON 和 JDBC 外,我们还提供了一些专门用于机器学习的数据源。 ###Image data source(图像数据源) 该图像数据源用于从目录加载图像文件,它可以通过 Java 库中的 ImageIO 加载压缩图像(jpeg、png 等)到原始图像表
【SparkML系列1】相关性、卡方检验和概述器实现
Correlation(相关性) 计算两组数据之间的相关性在统计学中是一种常见的操作。在spark.ml中,我们提供了计算多组数据之间成对相关性的灵活性。目前支持的相关性方法是皮尔逊(Pearson)相关系数和斯皮尔曼(Spearman)相关系数。 相关性计算使用指定的方法为输入的向量数据集计算相关性矩阵。输出将是一个数据框,其中包含向量列的相关性矩阵。 import org.apache
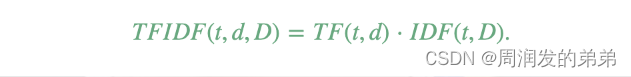
【SparkML系列3】特征提取器TF-IDF、Word2Vec和CountVectorizer
本节介绍了用于处理特征的算法,大致可以分为以下几组: 提取(Extraction):从“原始”数据中提取特征。转换(Transformation):缩放、转换或修改特征。选择(Selection):从更大的特征集中选择一个子集。局部敏感哈希(Locality Sensitive Hashing, LSH):这类算法结合了特征转换的方面与其他算法。 ###Feature Extractors(特

sparkml和mllib分别实现KMeans算法
正如大家所知道的MLLib这个算法包apache已经宣布只维护不更新了,所以大家如果做算法本人推荐使用ML的算法包。 原理的话本人就不在讲了,因为很多资料都写的比较清晰明白,这里我只写代码 本人在这里写了一些sparkml和mllib的示例入门程序 SparkML import org.apache.spark.ml.clustering.{KMeans, KMeansModel}im