特征提取专题

使用Python实现图像LBP特征提取的操作方法
《使用Python实现图像LBP特征提取的操作方法》LBP特征叫做局部二值模式,常用于纹理特征提取,并在纹理分类中具有较强的区分能力,本文给大家介绍了如何使用Python实现图像LBP特征提取的操作方... 目录一、LBP特征介绍二、LBP特征描述三、一些改进版本的LBP1.圆形LBP算子2.旋转不变的LB

【LVI-SAM】激光雷达点云处理特征提取LIO-SAM 之FeatureExtraction实现细节
激光雷达点云处理特征提取LIO-SAM 之FeatureExtraction实现细节 1. 特征提取实现过程总结1.0 特征提取过程小结1.1 类 `FeatureExtraction` 的整体结构与作用1.2 详细特征提取的过程1. 平滑度计算(`calculateSmoothness()`)2. 标记遮挡点(`markOccludedPoints()`)3. 特征提取(`extractF
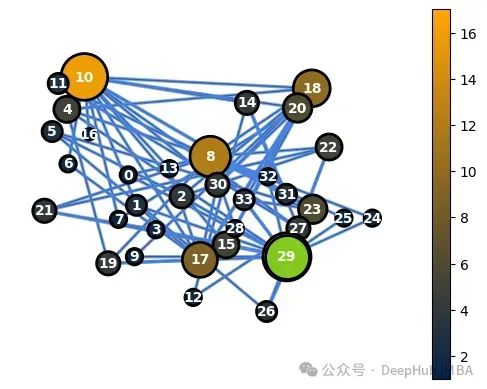
图特征工程实践指南:从节点中心性到全局拓扑的多尺度特征提取
图结构在多个领域中扮演着重要角色,它能有效地模拟实体间的连接关系,通过从图中提取有意义的特征,可以获得宝贵的信息提升机器学习算法的性能。 本文将介绍如何利用NetworkX在不同层面(节点、边和整体图)提取重要的图特征。 本文将以NetworkX库中提供的Zachary网络作为示例。这个广为人知的数据集代表了一个大学空手道俱乐部的社交网络,是理解图特征提取的理想起点。 我们先定义一些辅助函数

语音特征提取方法 (二)MFCC
下面总结的是第四个知识点:MFCC。因为花的时间不多,所以可能会有不少说的不妥的地方,还望大家指正。谢谢。 在任意一个Automatic speech recognition 系统中,第一步就是提取特征。换句话说,我们需要把音频信号中具有辨识性的成分提取出来,然后把其他的乱七八糟的信息扔掉,例如背景噪声啊,情绪啊等等。 搞清语音是怎么产生的对于我们理解语音有很大

Dimension out of range 等报错解决,可以加拼接后的深度特征提取了
报错 Extracting test features for class bagel: 0%| | 0/110 [00:00<?, ?it/s]Traceback (most recent call last):File "/home/cszx/c1/zgp/3D-ADS-main/patchcore_runner.py", line 46, in evaluatemet

跨模态检索研究进展综述【跨模态检索的核心工作在于:①不同模态数据的特征提取、②不同模态数据之间内容的相关性度量】【主流研究方法:基于传统统计分析的技术、基于深度学习的技术】【哈希编码提高检索速度】
随着互联网上多媒体数据的爆炸式增长,单一模态的检索已经无法满足用户需求,跨模态检索应运而生. 跨模态检索旨在以一种模态的数据去检索另一种模态的相关数据。 跨模态检索的核心任务是:数据特征提取 和 不同模态数据之间内容的相关性度量。 文中梳理了跨模态检索领域近期的研究进展,从以下角度归纳论述了跨模态检索领域的研究成果.: 传统方法;深度学习方法;手工特征的哈希编码方法;深度学习的哈希编码方法

Pointnet++改进即插即用系列:全网首发ACConv2d|即插即用,提升特征提取模块性能
简介:1.该教程提供大量的首发改进的方式,降低上手难度,多种结构改进,助力寻找创新点!2.本篇文章对Pointnet++特征提取模块进行改进,加入ACConv2d,提升性能。3.专栏持续更新,紧随最新的研究内容。 目录 1.理论介绍 2.修改步骤 2.1 步骤一 2.2 步骤二 2.3 步骤三 1.理论介绍 由于在给定的应用环境中

计算特征相关性的方法,特征提取的方法,如何判断特征是否重要
计算特征相关性可以用皮尔逊系数 (公式及含义解释:表示两组数据的线性关系程度,取值为[-1,1]),衡量的是变量之间的线性相关性,简单快速,但是只对线性关系敏感,非线性不适合;计算特征相关性的指标还有互信息MIC和距离相关系数(Python gist包),取值为[0,1]。 特征工程中包含特征选择和特征提取(区别),特征选择用的是Lasso,OMP,WOMP(特征排序)算法(流程讲清楚),

【通俗理解】深度学习特征提取——Attention机制的数学原理与应用
【通俗理解】深度学习特征提取——Attention机制的数学原理与应用 关键词提炼 #深度学习 #特征提取 #Attention机制 #CNN #Transformer #关联特征 #MLP #拟合处理 第一节:Attention机制的类比与核心概念 1.1 Attention机制的类比 Attention机制可以被视为一个“特征筛选器”,它像是一个精细的筛子,在众多的特征中筛选出

spark之特征提取
1、特征处理分类 特征抽取:从原始数据中抽取特征 特征转换:特征的维度、特征的转化、特征的修改 特征选取:从大规模特征集中选取一个子集 2、特征提取 2.1、TF-IDF 词频-逆向文件频率;词频TF(t,d)是词语t在文档d中出现的次数。文件频率DF(t,D)是包含词语的文档的个数。 tf=|t|/|d| tf-idf=tf*idf 公式中使用log函数,当词出现在所有文档中

ASR-声学特征提取
文章目录 方法一:MFCC特征提取step 1:A/D转换(采样)step 2:预加重step 3:加窗分帧step 4:DFT+取平方step 5:Mel滤波step 6:取对数step 7:IDFTstep 8:动态特征 方法二:深度学习特征提取step 1:采样step 2:分帧step 3:傅里叶变换step 4:识别字符step 5:获取映射图 方法一:MFCC特征提

PSMNet:Pyramid Stereo Matching Network学习测试笔记04-特征提取部分前向传播
写在前面的话: 2019年9月21日18:56:48好久没回来更新博客了。因为在实习中,实习的新问题一大堆,并且实习的工作内容整理了也是发在公司内网wiki,外面是不可能发的(专业,有节操)。周末再做做毕业论文相关的工作。 写在前面的话2: 2019年09月28日18:02:55补充说明:CSDN博客发布版权更新,如果您看了博客并且用到PSMNet相关东西,请注明引用原作者的文章: @inpr

基于 YOLOv8n-pose 模型的图像特征提取,可用于识别特定的姿态
目录 1. __init__ 方法:初始化类的实例 2. save_pose_feat 方法: 3. load_db_pose_feat 方法: 4. cal_similarity 方法: 实现了一个基于 YOLOv8n-pose 模型的图像特征提取和相似性比较系统。它可以从图像中提取人体关键点信息,并将其保存为特征文件。然后,通过计算输入图像与数据库中图像特征的相似度,确定输入
描述一下SIFT特征提取算法的工作原理
SIFT(Scale-Invariant Feature Transform,尺度不变特征变换)是由 David Lowe 于 1999 年提出的一种特征提取算法,用于检测和描述图像中的局部特征点。SIFT 特征具有旋转、尺度和光照不变性,因此在各种计算机视觉任务中广泛应用,如图像匹配、物体识别等。 SIFT 的工作原理主要分为四个步骤: 1. 尺度空间极值检测(Scale-Space Ext

人工智能NLP--特征提取之词嵌入(Word Embedding)
一、前言 在上篇文章中,笔者详细讲解介绍了人工智能自然语言处理特征提取中的TD-IDF型文本处理方法,那么接下来,笔者将为大家揭晓,目前阶段,在特征提取,也就是文本数据转成数字数据领域内最常用也是最好用的方法–词嵌入(Word Embedding)。 二、定义,组成和基本介绍 在自然语言处理(NLP)领域,词嵌入(Word Embedding)是一种将词汇映射到向量空间的技术。通过词嵌入,词

OpenCV3中的SURF特征提取及匹配
原理不多介绍了(哈哈因为还不懂原理),直接上代码和效果吧,只是为了记录下用法省的忘了。 环境:Ubuntu14.04,Clion,OpenCV3.2 //// Created by xiangqian on 18-2-20.//#include <iostream>#include "opencv2/core.hpp"#include "opencv2/features2d.hpp"

CV学习笔记3-图像特征提取
图像特征提取是计算机视觉中的一个关键步骤,其目标是从图像中提取有意义的特征,以便进行进一步的分析或任务,如分类、检测、分割等。特征提取可以帮助减少数据的维度,同时保留重要的信息。以下是常见的图像特征提取方法和技术: 1. 传统特征提取方法 1.1 边缘检测 Canny 边缘检测:通过计算图像中像素的梯度,找出边缘。Sobel 算子:计算图像在 x 和 y 方向的梯度,用于边缘检测。Lapla

【机器学习】特征提取 特征降维
特征工程 特征工程是将原始数据转化为可以用于机器学习的数字特征,比如字典的特征提取,文档的特征提取等。 字典特征提取 把字典的每个唯一的键作为数据集特征的一个维度,有这个维度的就为1,没有就是0。其他相同的键,该维度的值就是其键值。 这样的操作把字典样本的每一条数据转化为了矩阵,但是矩阵中含有大量的0(因为数据中的键和值有很多不同),所以称之为稀疏矩阵 为了保存数据的高效,一般使用三元组
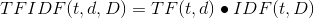
SparkML中三种文本特征提取算法(TF-IDF/Word2Vec/CountVectorizer)
在SparkML中关于特征的算法可分为Extractors(特征提取)、Transformers(特征转换)、Selectors(特征选择)三部分: Feature Extractors TF-IDFWord2VecCountVectorizer Feature Transformers TokenizerStopWordsRemover n n-gramBinarizerP

文本挖掘之降维技术之特征提取之因子分析(FA)
因子分析法(FA) 因子分析法是通过将原有变量内部的相互依赖关系进行数据化,把大量复杂关系归为少量的几个综合因子的统计方法。它的基本思想是通过分析各变量之间的方差贡献效果,将大的即相关性高的联系比较紧密的分在同一个类别中,而不同类的则相关性是比较低的,这其中一个类别描述了一种独立结构,这个结构在因子分析法中叫做公共因子。这个方法的研究目的就是尝试使用少数几个不可测的通过协方差矩阵计算得来
如何利用机器学习算法进行数据分析和挖掘,数据优化、预处理、特征提取等老板吩咐的工作
在利用机器学习算法进行数据分析和挖掘时,数据优化、预处理和特征提取是非常重要的步骤。 1. 数据收集 收集相关数据,这是整个过程的起点和基础。数据可以来自多个来源,如数据库、API、网络爬虫等。 2. 数据预处理 数据预处理是保证数据质量和算法效果的关键步骤,主要包括以下几个方面: 2.1 数据清洗 处理缺失值:可以选择删除缺失值、填充缺失值(如用平均值、中位数、最频繁值等)。处理异常

基于 Arm 虚拟硬件实现人脸特征提取模型的部署
基于 Arm 虚拟硬件实现人脸特征提取模型的部署 文章目录 1 实验背景1.1 Arm 虚拟硬件介绍1.2 文章简介 2 实验目标3 实验前准备3.1 订阅 Arm 虚拟硬件镜像的百度智能云云服务器 BCC 实例3.2 克隆实验代码 4 实验步骤4.1 配置开发环境4.1.1 配置 CMSIS-Toolbox 环境4.1.2 配置 Python 环境4.1.3 配置 CMSIS-Pa

目标检测的图像特征提取—Haar特征
1、Haar-like特征 Haar-like特征最早是由Papageorgiou等应用于人脸表示,Viola和Jones在此基础上,使用3种类型4种形式的特征。 Haar特征分为三类:边缘特征、线性特征、中心特征和对角线特征,组合成特征模板。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。Haar特征值反映了图像的灰度变化情况。例如:脸部

Talk|CVPR‘24 Oral:超越3D - Point Transformer V3中的多模态特征提取新构想
本期为TechBeat人工智能社区第599期线上Talk。 北京时间6月12日(周三)20:00,香港大学博士生—吴虓杨的Talk已经准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “超越3D - Point Transformer V3中的多模态特征提取新构想”,他通过PTv3的两个核心思想——骨干网络设计的规模准则与非结构化数据的序列化技术,探究3D点云骨干网络作为一种多
【Python机器学习】PCA——特征提取(2)
上一篇写过了用单一最近邻分类器训练后的精度只有0.22. 现在用PCA。想要度量人脸的相似度,计算原始像素空间中的距离是一种相当糟糕的方法。用像素表示来比较两张图像时,我们比较的是每个像素的灰度值与另一张图像对应位置的像素灰度值。这种表示与人们对人脸图像的解释方式有很大不同,使用这种原始表示很难获取到面部特征。例如,如果使用像素距离,那么将人脸向右移动一个像素将发生巨大变化,得到一个完全不同的表