idf专题
![WIN11 ESP32 IDF + VSCODE 环境搭建[教程向]](https://i-blog.csdnimg.cn/direct/72b607b6912243f7b49949c0dbb6e4ed.png)
WIN11 ESP32 IDF + VSCODE 环境搭建[教程向]
前言 目录 前言 安装ESP32-IDF VSCODE插件安装 编译测试 很多时候我们想学习一门新的技能,需要使用全新的开发环境,很多时候我们会在安装环境这个环节卡住很久,这里简单介绍一下ESP32+VSCODE环境搭建。 安装ESP32-IDF https://dl.espressif.cn/dl/esp-idf/?idf=4.4 直接复制上面链接,进入idf下载界面。

【ESP32 IDF】WS2812B灯驱动
WS2812B灯驱动 1. 简单描述2. 驱动过程3.主函数添加驱动程序 1. 简单描述 开发环境为 IDF5.2.2采用乐鑫官方组件库 组件库地址 : https://components.espressif.com/components/espressif/led_strip/versions/2.5.5 2. 驱动过程 复制led_strip组件命令 在自

NLP-词向量-发展:词袋模型【onehot、tf-idf】 -> 主题模型【LSA、LDA】 -> 词向量静态表征【Word2vec、GloVe、FastText】 -> 词向量动态表征【Bert】
NLP-词向量-发展: 词袋模型【onehot、tf-idf】主题模型【LSA、LDA】基于词向量的静态表征【Word2vec、GloVe、FastText】基于词向量的动态表征【Bert】 一、词袋模型(Bag-Of-Words) 1、One-Hot 词向量的维数为整个词汇表的长度,对于每个词,将其对应词汇表中的位置置为1,其余维度都置为0。 缺点是: 维度非常高,编码过于稀疏,易出

亦菲喊你来学机器学习(18) --TF-IDF方法
文章目录 TF-IDF词频TF逆文档频率IDF计算TF-IDF值 应用实验使用TF-IDF1. 收集数据2. 数据预处理3. 构建TF-IDF模型对象4. 转化稀疏矩阵5. 排序取值完整代码展示 jieba分词总结 TF-IDF TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)是一种用于信息检索与文本挖掘的常用加

NLP03:使用TF-IDF和LogisticRegression进行文本分类
公众号:数据挖掘与机器学习笔记 1.TF-IDF算法步骤 1.1 计算词频 考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。 1.2 计算逆文档频率 需要一个语料库(corpus),用来模拟语言的使用环境。 如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数

文本数据分析-(TF-IDF)(2)
文章目录 一、TF-IDF与jieba库介绍1.TF-IDF概述2.jieba库概述 二、TF-IDF与jieba库的结合1.结合2.提取步骤 三,代码实现1.导入必要的库读取文件:3.将文件路径和内容存储到DataFrame4.加载自定义词典和停用词5.分词并去除停用词 TF-IDF(Term Frequency-Inverse Document Frequency)与jieba

【ESP-IDF FreeRTOS】信号量
下一个内容,信号量。 先包含头文件。 #include "freertos/semphr.h" 我们通过队列可以进行任务间的数据传递,也可以通过队列来控制任务间的同步。如果我只需要控制任务而不需要传递数据,那么我们完全可以用信号量来代替队列。 简单介绍一下信号量,它约等于是没有容量的队列,或者把它当成是一个计数器。我们对信号量的操作有加一和减一。 如果信号量当前的值为0并且我需要进行减一

《NLP自然语言处理》—— 关键字提取之TF-IDF算法
文章目录 一、TF-IDF算法介绍二、举例说明三、示例:代码实现四、总结 一、TF-IDF算法介绍 TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。词语的重要性随着它在文件中出现的次数成正比

《机器学习》数据分析之关键词提取、TF-IDF、项目实现 <下>
目录 一、内容回顾 1、核心算法 2、算法公式 3、拆分文本 二、再次操作 1、取出每一卷的地址和内容 得到下列结果:(此为DF类型) 2、对每一篇文章进行分词 3、计算TF-IDF值 得到以下数据: 三、总结 1、关键词提取 1)基于频率统计的方法 2)基于文本特征的方法 2、TF-IDF(Term Frequency-Inverse Document Freque

机器学习:TF-IDF算法原理及代码实现
TF-IDF是一种用于信息检索与文本挖掘的常用加权技术。它是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。它的主要思想是:如果某个词语在一篇文章中出现的频率高(Term Frequency,TF),并且在其他文章中很少出现(Inverse Document Frequency,IDF),则认为这个词语具有很好的类别区分能力,对这篇文章的内容有很好的指示作用。

《机器学习》文本数据分析之关键词提取、TF-IDF、项目实现 <上>
目录 一、如何进行关键词提取 1、关键词提取步骤 1)数据收集 2)数据准备 3)模型建立 4)模型结果统计 5)TF-IDF分析 2、什么是语料库 3、如何进行中文分词 1)导包 2)导入分词库 3)导入停用词库 4)使用jie

文本分析之关键词提取(TF-IDF算法)
键词提取是自然语言处理中的一个重要步骤,可以帮助我们理解文本的主要内容。TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的关键词提取方法,它基于词频和逆文档频率的概念来确定词语的重要性。 准备工作 首先,我们需要准备一些工具和库,包括 Pandas、jieba(结巴分词)、sklearn 等。 Pandas:用于数据处理。jieba
spark CountVectorizer+IDF提取中文关键词(scala)
在提取关键词中,TF-IDF是比较常用的算法,spark mlib中也提供了TF以及IDF的方法,但是由于spark提供的TF算法是不可逆的,即无法获取TF的结果对应的原句子的文字,所以需要采用 CountVectorizer。提取关键词的过程如下: 1、中文分词以及去掉停用词: 中文分词使用的是ansj:maven如下: <!--ansj--><dependency><groupI

MQTT入门(基于ESP-IDF)
主要参考资料: ESP8266开发之旅 阿里云物联网平台篇: https://blog.csdn.net/dpjcn1990/article/details/104544175 阿里云物联网官方文档: https://help.aliyun.com/zh/iot/ ESP32基础应用之ESP32与阿里云物联网平台实现数据互传(MQTT协议): https://blog.csdn.net/qq_4
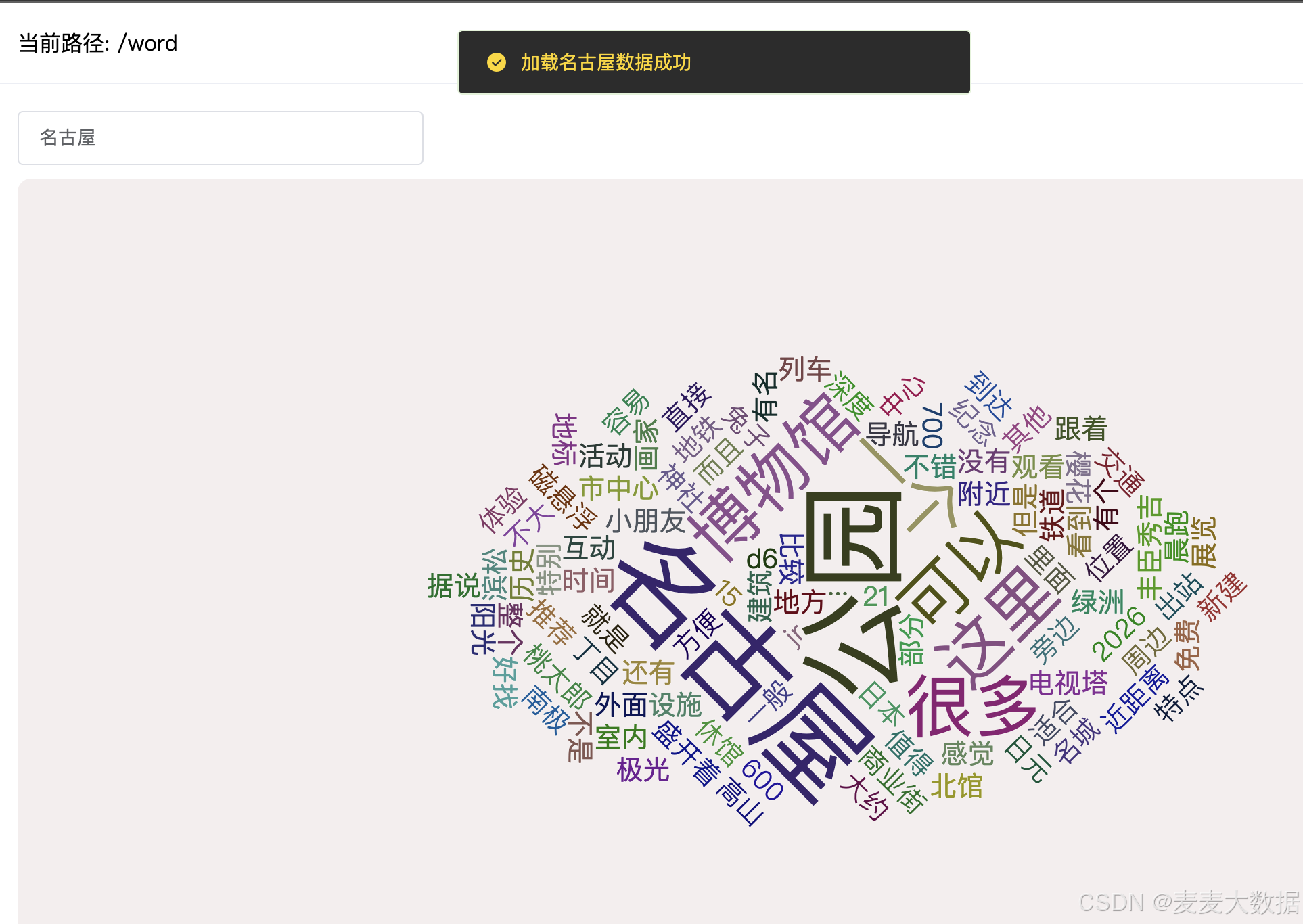
vue 精选评论词云 集成echarts-wordcloud TF-IDF算法
这一期在我们的系统里集成词云组件,开发的功能是景区精选评论的词云展示功能。 这个界面的逻辑是这样的: 在数据框里输入城市,可以是模糊搜索的,选择城市; 选择城市后,发往后台去查询该城市的精选评论,由于一个城市会有很多景点,所以精选评论也有很多,采用TF-IDF算法,计算关键词,返回给前端,使用echarts词云组件进行可视化; 再次输入城市,可以切换城市,同时词云会重新渲染。 1 词云页

基于vscode安装EPS-IDF环境与创建例程
安装ESP-IDF 在vscode中安装esp-idf插件 然后打开插件,左侧选择Configure ESP-IDF Extension ![![[Pasted image 20240821221256.png]](https://i-blog.csdnimg.cn/direct/3993e22c37644097b464aef0bbc244a5.png) 点击安装 自动下载ESP
【ESP32 IDF】WEB服务程序更新为vue3+vitify3
WEB服务程序更新为vue3+vitify3 1. 简单描述2. 代码仓库 1. 简单描述 开发环境为 IDF5.2.2官方给的例子【restful_server】是vue2+vuetify2,但是因为vuetify2官网已经好久没有更新了,故换为vue3+vuetify3参考连接为 ESP32——WEB服务程序移植(基于示例restful_server) 2. 代码仓库 h

Python实现TF-IDF算法
博客目录 引言 什么是TF-IDF?TF-IDF的应用场景为什么使用TF-IDF? TF-IDF的数学原理 词频(Term Frequency, TF)逆文档频率(Inverse Document Frequency, IDF)TF-IDF的计算公式TF-IDF的特点与优势 TF-IDF的实现步骤 数据预处理计算词频(TF)计算逆文档频率(IDF)计算TF-IDF值文本向量化 Pytho

机器学习第五篇----TF-IDF算法详解
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由两部分组成,TF和IDF。在前期的关键词提取和文本one-hot的时候使用较多 1、TF-IDF 算法 TF(词频):表示词w在文档Di中出现的频率,计算公式如下 其中count(w)为关键词w出现的次数,|Di| 为文档Di中所有词的数量。 IDF(逆文

【ESP-IDF FreeRTOS】任务管理
上一篇我们介绍了延时函数。讲到了因为FreeRTOS是多任务的,因此我们使用延时函数可以将当前任务挂起,就可以让CPU去执行其他任务,等到延时时间结束,再接着执行之前的任务,这样可以充分利用CPU的性能。 那么既然ESP-IDF FreeRTOS是多任务的,那么我们必然是可以创建任务的,之前一直用的app_main是ESP-IDF FreeRTOS默认创建的main任务。 创建任务可用的函数有

ESP32 esp-idf esp-adf环境安装及.a库创建与编译
简介 ESP32 功能丰富的 Wi-Fi & 蓝牙 MCU, 适用于多样的物联网应用。使用freertos操作系统。 ESP-IDF 官方物联网开发框架。 ESP-ADF 官方音频开发框架。 文档参照 https://espressif-docs.readthedocs-hosted.com/projects/esp-adf/zh-cn/latest/get-started/index
使用tf*idf实现对文档集合的检索
步骤: 读取三篇文档1.txt,2.txt,3.txt,里边的内容分别为“this is php”,“this is html html”,“this is java” 分词,并统计词频tf 计算文档频率df 计算每篇文档的特征向量 计算搜索词与文档的夹角余弦值 <?php$_txts = array('1.txt','2.txt','3.txt');$_len = cou
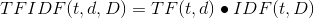
SparkML中三种文本特征提取算法(TF-IDF/Word2Vec/CountVectorizer)
在SparkML中关于特征的算法可分为Extractors(特征提取)、Transformers(特征转换)、Selectors(特征选择)三部分: Feature Extractors TF-IDFWord2VecCountVectorizer Feature Transformers TokenizerStopWordsRemover n n-gramBinarizerP

【NLP项目-01】手把手教你基于TF-IDF提取向量+贝叶斯或者随机森林进行文本分类
【NLP项目-01】手把手教你基于TF-IDF提取向量+贝叶斯或者随机森林进行文本分类 本次修炼方法请往下查看 🌈 欢迎莅临我的个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地! 🎇 相关内容文档获取 微信公众号 🎇 相关内容视频讲解 B站 🎓 博主简介:AI算法驯化师,混迹多个大厂搜索、推荐、广告、数据分析、数据挖掘岗位 个人申请专利40+,
TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用于信息检索和文本挖掘的统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。它的重要性随着词语在文本中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF算法主要应用于关键词抽取、文档相似度计算和文本挖掘等领域。 以下是TF-IDF算法的

TF-IDF在现代搜索引擎优化策略中的作用
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于文本挖掘和信息检索的统计方法,用来评估一个词语对于一个文档或一个语料库的重要程度。TF-IDF算法结合了词频(TF)和逆文档频率(IDF)两个指标,既考虑了词语在单个文档中的出现频率,也考虑了词语在整个语料库中的普遍性。 1. 术语解释 1.1 词频(TF) 词频(Term Frequ