countvectorizer专题

spark CountVectorizer+IDF提取中文关键词(scala)
在提取关键词中,TF-IDF是比较常用的算法,spark mlib中也提供了TF以及IDF的方法,但是由于spark提供的TF算法是不可逆的,即无法获取TF的结果对应的原句子的文字,所以需要采用 CountVectorizer。提取关键词的过程如下: 1、中文分词以及去掉停用词: 中文分词使用的是ansj:maven如下: <!--ansj--><dependency><groupI
BOW模;型CountVectorizer模型;tfidf模型;
自然语言入门 一、BOW模型:使用一组无序的单词来表达一段文字或者一个文档,并且每个单词的出现都是独立的。在表示文档时是二值(出现1,不出现0); eg: Doc1:practice makes perfect perfect. Doc2:nobody is perfect. Doc1和Doc2作为语料库:词有(practice makes perfect nobody is) Doc
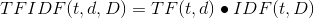
SparkML中三种文本特征提取算法(TF-IDF/Word2Vec/CountVectorizer)
在SparkML中关于特征的算法可分为Extractors(特征提取)、Transformers(特征转换)、Selectors(特征选择)三部分: Feature Extractors TF-IDFWord2VecCountVectorizer Feature Transformers TokenizerStopWordsRemover n n-gramBinarizerP

使用sklearn CountVectorizer 实现n-gram
#coding=utf-8'''Created on 2018-1-25'''from sklearn.feature_extraction.text import CountVectorizertext = ["A smile is the most charming part of a person forever.","A smile is"]# ngram_range=(2, 2)表明
CountVectorizer与TfidfVectorizer 对文本特征的特征抽取
CountVectorizer: 只考虑每种词汇在该条训练文本中出现的频率 TfidfVectorizer : 除了考量每种词汇在该条训练文本中出现的频率,同时包含这个词汇的文本的条数的倒数. 对新闻文本数据使用CountVectorizer与TfidfVectorizer 抽取特征,使用朴素贝叶斯进行分类。 # -*- coding:utf-8 -*-if __name__ == '

CountVectorizer TfidfVectorizer 中文处理
https://blog.csdn.net/shuihupo/article/details/80930801
【SparkML系列3】特征提取器TF-IDF、Word2Vec和CountVectorizer
本节介绍了用于处理特征的算法,大致可以分为以下几组: 提取(Extraction):从“原始”数据中提取特征。转换(Transformation):缩放、转换或修改特征。选择(Selection):从更大的特征集中选择一个子集。局部敏感哈希(Locality Sensitive Hashing, LSH):这类算法结合了特征转换的方面与其他算法。 ###Feature Extractors(特
python学习 文本特征提取(三) CountVectorizer TfidfVectorizer 朴素贝叶斯分类性能测试
python学习 文本特征提取(一) DictVectorizer shuihupo 博客地址,https://blog.csdn.net/shuihupo/article/details/80923414 python学习 文本特征提取(二) CountVectorizer TfidfVectorizer 中文处理 https://blog.csdn.net/shuihupo/article
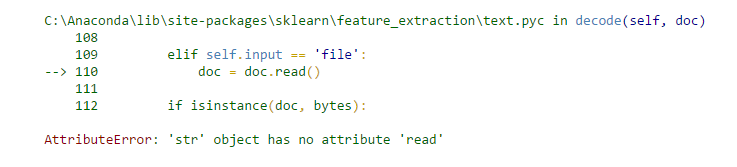
CountVectorizer.transform出现的一个错误的解决
问题 该错误的出现还是跟我上一个博客中讲述的问题有关,因为我将CountVectorizer的参数input设置为file,所以在本博客出现问题的代码中,因为给它的是一个字符串列表,所以就会出现错误。先看出现问题的代码: new_post = ['imaging databases']new_post_vec = vectorizer.transform(new_post)print(ne