tf专题

【深度学习 走进tensorflow2.0】TensorFlow 2.0 常用模块tf.config
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。人工智能教程 本篇文章将会教大家如何 合理分配显卡资源,设置显存使用策略。主要使用tf.config模块进行设置。下面我们一起了解下具体用法和例子。 一、指定当前程序使用的 GPU 例如,在一台具有 4 块 GPU 和一个 C

Tensorflow 中train和test的batchsize不同时, 如何设置: tf.nn.conv2d_transpose
大家可能都知道, 在tensorflow中, 如果想实现测试时的batchsize大小随意设置, 那么在训练时, 输入的placeholder的shape应该设置为[None, H, W, C]. 具体代码如下所示: # Placeholders for input data and the targetsx_input = tf.placeholder(dtype=tf.float32, s

NLP-词向量-发展:词袋模型【onehot、tf-idf】 -> 主题模型【LSA、LDA】 -> 词向量静态表征【Word2vec、GloVe、FastText】 -> 词向量动态表征【Bert】
NLP-词向量-发展: 词袋模型【onehot、tf-idf】主题模型【LSA、LDA】基于词向量的静态表征【Word2vec、GloVe、FastText】基于词向量的动态表征【Bert】 一、词袋模型(Bag-Of-Words) 1、One-Hot 词向量的维数为整个词汇表的长度,对于每个词,将其对应词汇表中的位置置为1,其余维度都置为0。 缺点是: 维度非常高,编码过于稀疏,易出

亦菲喊你来学机器学习(18) --TF-IDF方法
文章目录 TF-IDF词频TF逆文档频率IDF计算TF-IDF值 应用实验使用TF-IDF1. 收集数据2. 数据预处理3. 构建TF-IDF模型对象4. 转化稀疏矩阵5. 排序取值完整代码展示 jieba分词总结 TF-IDF TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)是一种用于信息检索与文本挖掘的常用加

NLP03:使用TF-IDF和LogisticRegression进行文本分类
公众号:数据挖掘与机器学习笔记 1.TF-IDF算法步骤 1.1 计算词频 考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。 1.2 计算逆文档频率 需要一个语料库(corpus),用来模拟语言的使用环境。 如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数
文本数据分析-(TF-IDF)(2)
文章目录 一、TF-IDF与jieba库介绍1.TF-IDF概述2.jieba库概述 二、TF-IDF与jieba库的结合1.结合2.提取步骤 三,代码实现1.导入必要的库读取文件:3.将文件路径和内容存储到DataFrame4.加载自定义词典和停用词5.分词并去除停用词 TF-IDF(Term Frequency-Inverse Document Frequency)与jieba
tf.train.batch 和 tf.train.batch_join的区别
先看两个函数的官方文档说明 tf.train.batch官方文档地址: https://www.tensorflow.org/api_docs/python/tf/train/batch tf.train.batch_join官方文档地址: https://www.tensorflow.org/api_docs/python/tf/train/batch_join tf.train.ba

《NLP自然语言处理》—— 关键字提取之TF-IDF算法
文章目录 一、TF-IDF算法介绍二、举例说明三、示例:代码实现四、总结 一、TF-IDF算法介绍 TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。词语的重要性随着它在文件中出现的次数成正比

《机器学习》数据分析之关键词提取、TF-IDF、项目实现 <下>
目录 一、内容回顾 1、核心算法 2、算法公式 3、拆分文本 二、再次操作 1、取出每一卷的地址和内容 得到下列结果:(此为DF类型) 2、对每一篇文章进行分词 3、计算TF-IDF值 得到以下数据: 三、总结 1、关键词提取 1)基于频率统计的方法 2)基于文本特征的方法 2、TF-IDF(Term Frequency-Inverse Document Freque

机器学习:TF-IDF算法原理及代码实现
TF-IDF是一种用于信息检索与文本挖掘的常用加权技术。它是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。它的主要思想是:如果某个词语在一篇文章中出现的频率高(Term Frequency,TF),并且在其他文章中很少出现(Inverse Document Frequency,IDF),则认为这个词语具有很好的类别区分能力,对这篇文章的内容有很好的指示作用。

《机器学习》文本数据分析之关键词提取、TF-IDF、项目实现 <上>
目录 一、如何进行关键词提取 1、关键词提取步骤 1)数据收集 2)数据准备 3)模型建立 4)模型结果统计 5)TF-IDF分析 2、什么是语料库 3、如何进行中文分词 1)导包 2)导入分词库 3)导入停用词库 4)使用jie
文本分析之关键词提取(TF-IDF算法)
键词提取是自然语言处理中的一个重要步骤,可以帮助我们理解文本的主要内容。TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的关键词提取方法,它基于词频和逆文档频率的概念来确定词语的重要性。 准备工作 首先,我们需要准备一些工具和库,包括 Pandas、jieba(结巴分词)、sklearn 等。 Pandas:用于数据处理。jieba

tf.nn.embedding_lookup()用法
embedding_lookup( )的用法 关于tensorflow中embedding_lookup( )的用法,在Udacity的word2vec会涉及到,本文将通俗的进行解释。 首先看一段网上的简单代码: #!/usr/bin/env/python# coding=utf-8import tensorflow as tfimport numpy as npinput_ids =
TensorFlow图变量tf.Variable的用法解析
TensorFlow中的图变量,跟我们平时所接触的一般变量在用法上有很大的差异。尤其对于那些初次接触此类深度学习库的编程人员来说,会显得十分难上手。 本文将按照如下篇幅深入剖析tf.Variable这个核心概念: 图变量的初始化方法 两种定义图变量的方法 scope如何划分命名空间 图变量的复用 图变量的种类 1.图变量的初始化方法 对于一般的Python代码,变量的初始化就是变量的定义,
Tensorflow中的降维函数总结:tf.reduce_*
在使用tensorflow时常常会使用到tf.reduce_*这类的函数,在此对一些常见的函数进行汇总 1.tf.reduce_sum tf.reduce_sum(input_tensor , axis = None , keep_dims = False , name = None , reduction_indices = None) 参数: input_tensor:要减少的张量。应

【TensorFlow】tf.where
官方API TensorFlow中文社区tf.where tf.where(input, name=None)`Returns locations of true values in a boolean tensor.This operation returns the coordinates of true elements in input. The coordinates are re
tf.train.ExponentialMovingAverage用法和说明
在这篇博客中对tf.train.ExponentialMovingAverage讲的很清楚,这里主要补充几点说明: 第一点: 当程序执行到 ema_op = ema.apply([w]) 的时候,如果 w 是 Variable, 那么将会用 w 的初始值初始化 ema 中关于 w 的 ema_value,所以 emaVal0=1.0。如果 w 是 Tensor的话,将会用 0.0 初始化。
tf.identity 和 tf.control_dependencies的用法
关于 tf.control_dependencies(具体参考博客,也是本文主要参考对象): tf.control_dependencies(control_inputs)设计是用来控制计算流图的,给图中的某些计算指定顺序。比如:我们想要获取参数更新后的值,那么我们可以这么组织我们的代码。 opt = tf.train.Optimizer().minize(loss)with tf.contr

tf.train.exponential_decay(学习率衰减)
#!/usr/bin/env python3# -*- coding: utf-8 -*-'''学习率较大容易搜索震荡(在最优值附近徘徊),学习率较小则收敛速度较慢,那么可以通过初始定义一个较大的学习率,通过设置decay_rate来缩小学习率,减少迭代次数。tf.train.exponential_decay就是用来实现这个功能。'''__author__ = 'Zhang Shuai'i
【深度学习】嘿马深度学习笔记第5篇:神经网络与tf.keras,学习目标【附代码文档】
本教程的知识点为:深度学习介绍 1.1 深度学习与机器学习的区别 TensorFlow介绍 2.4 张量 2.4.1 张量(Tensor) 2.4.1.1 张量的类型 TensorFlow介绍 1.2 神经网络基础 1.2.1 Logistic回归 1.2.1.1 Logistic回归 TensorFlow介绍 总结 每日作业 神经网络与tf.keras 1.3 神经网络基础 神经网络与tf.
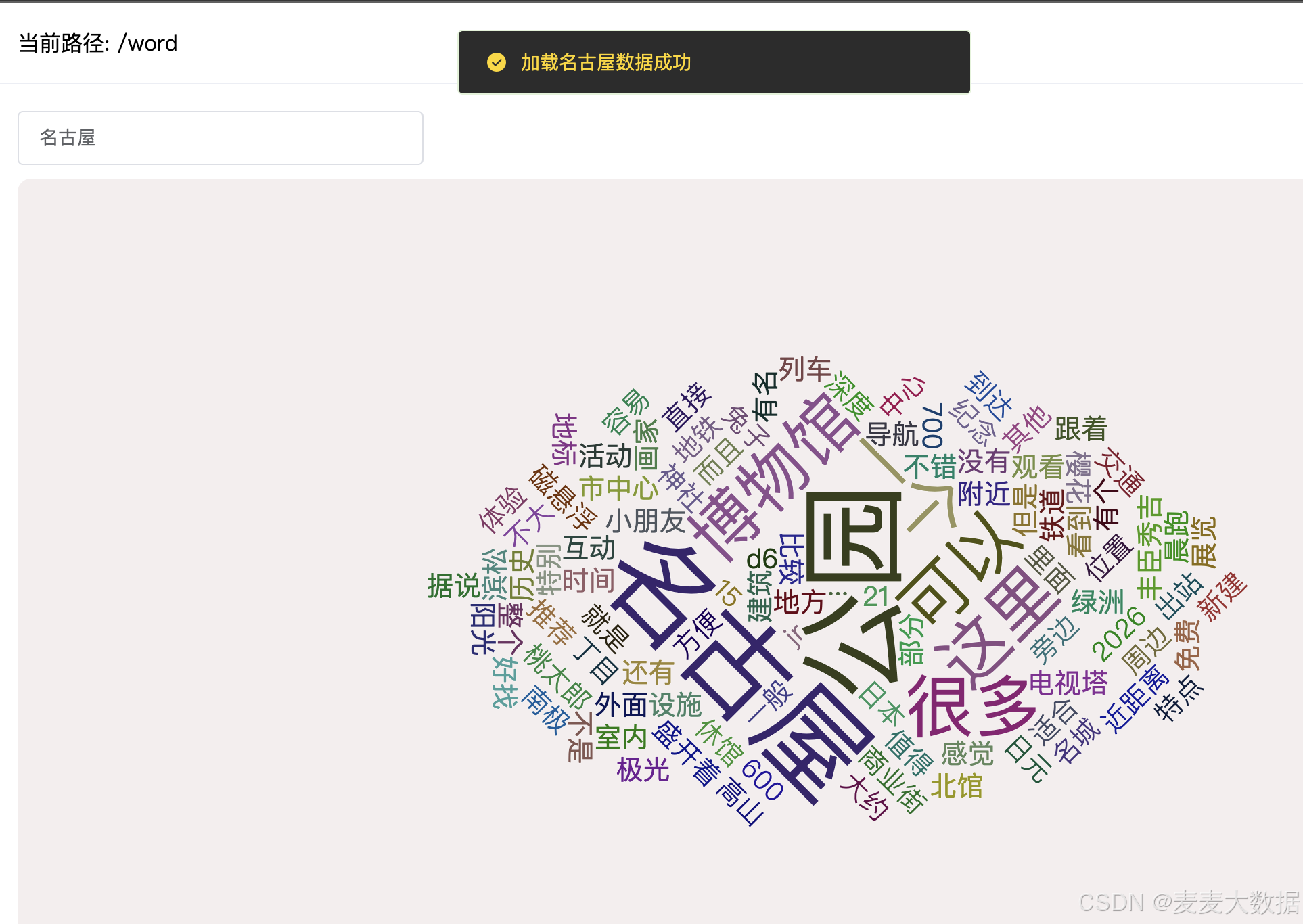
vue 精选评论词云 集成echarts-wordcloud TF-IDF算法
这一期在我们的系统里集成词云组件,开发的功能是景区精选评论的词云展示功能。 这个界面的逻辑是这样的: 在数据框里输入城市,可以是模糊搜索的,选择城市; 选择城市后,发往后台去查询该城市的精选评论,由于一个城市会有很多景点,所以精选评论也有很多,采用TF-IDF算法,计算关键词,返回给前端,使用echarts词云组件进行可视化; 再次输入城市,可以切换城市,同时词云会重新渲染。 1 词云页


Gmapping从开始到放弃—写一个TF 监听
这篇文章主要 记录如何监听一个TF广播,通过监听tf,我们可以避免繁琐的旋转矩阵的计算,而直接获取我们需要的相关信息.当然也是接着上一篇文章创建的开发包继续走下去 (1)在my_tf文件下的src下新建一个文件命名turtle_tf_listener.cpp. 添加代码如下 #include <ros/ros.h>#include <tf/transform_listener.h> //

Gmapping从开始到放弃—写一个TF 广播
这是一个关于实现把机器人的位姿广播到TF中,这是对ROS 有一定的熟悉之后教程 (1)cd catkin_ws/src 进入我们的ROS 的工作空间 (2)catkin_create_pkg my_tf tf roscpp rospy turtlesim 这一句是新建一个ROS 的包,也就是一个ROS的工程,并添加他的依赖项,主要依赖tf和C++以及你可以使用python开发 (3) c
Python实现TF-IDF算法
博客目录 引言 什么是TF-IDF?TF-IDF的应用场景为什么使用TF-IDF? TF-IDF的数学原理 词频(Term Frequency, TF)逆文档频率(Inverse Document Frequency, IDF)TF-IDF的计算公式TF-IDF的特点与优势 TF-IDF的实现步骤 数据预处理计算词频(TF)计算逆文档频率(IDF)计算TF-IDF值文本向量化 Pytho
使用estimator结构训练tf模型
一、使用estimator训练模型的流程 1、构建model_fn def my_metric_fn(labels, predictions):return {'accuracy': tf.metrics.accuracy(labels, predictions)}def model_fn(features, labels, mode, params):""" TODO: 模型函数必须有这四个