本文主要是介绍大型语言模型的语义搜索(二):文本嵌入(Text Embeddings),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在我写的上一篇博客:关键词搜索中,我们解释了关键词搜索(Keyword Search)的技术,它通过计算问题和文档中重复词汇的数量,来搜索与问题相关的文档,常用的关键词搜索算法是Okapi BM25,简称BM25,关键词搜索算法的局限性在与它并不是根据文本本身的语义来进行文档搜索的,当文档与问题在语义上相关,但它们之间却没有重复词汇时,关键词搜索算法失效,它将无法搜索到该相关文档。为了解决这个问题,我们应该让机器理解文本本身的语义,然后根据文本的语义去搜索相关文档,这就引出了下面我们要解释的文本嵌入(Text Embeddings)的概念。
一、环境配置
我们需要安装如下的python包:
pip install cohere umap-learn altair datasets这里简单介绍一下cohere是一家从事大模型应用开发的公司,接下来我们需要导入一些基础配置,这些基础配置主要包含cohere的api_key:
import os
import cohere
import pandas as pd
from dotenv import load_dotenv, find_dotenv#导入cohere的api_key
_ = load_dotenv(find_dotenv()) # read local .env file#创建cohere的Client
co = cohere.Client(os.environ['COHERE_API_KEY'])这里需要说明一下的是关于COHERE_API_KEY我们需要去cohere的网站自己注册一个cohere账号然后自己创建一个自己的api_key。
二、词嵌入(Word Embedding)
要了解什么是词嵌入,我们先来看下面这个例子,我们有一个二维的网格坐标图,上面摆放了各种物品,接下来我想要将一个apple(苹果)放入到这个网格中,请选择一个合适的位置,如下图所示:

仔细观察这个网格,在左上角是各种球类,左下角是各种建筑,右下角是各种交通工具,而右上角是各种水果,很显然apple应该放入到右上角,因为它属于水果,所以apple需要远离球类,建筑,交通工具,它需要和水果类的物品放在一起,最合适的位置应该是(5,5),如下图所示:

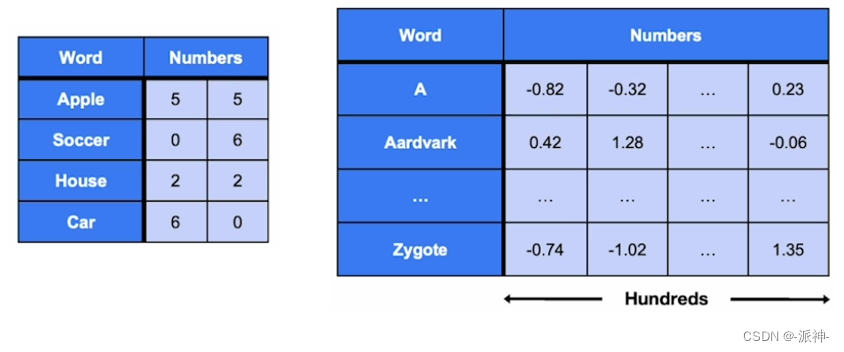
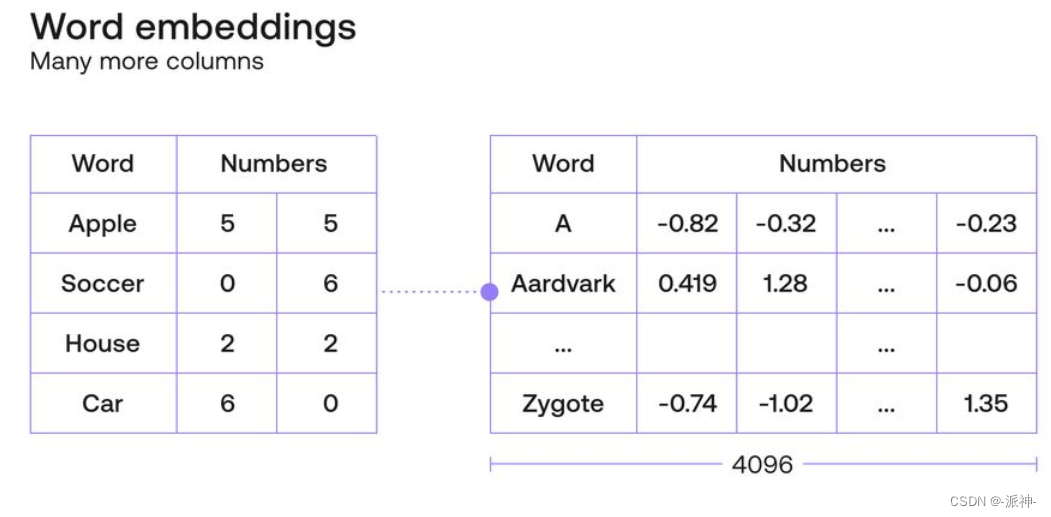
将一个词汇放入到词向量空间中的一个合适的位置这就是所谓的词嵌入(Word Embedding) ,在上图中我们用两个数值表示一个词汇在二维平面中的位置如apple(5,5),banana(6,5),car(6,0)等,但在实际的应用中一个词汇可能需要使用几百个,甚至几千个数字来表示其在多维空间中的位置,如下图所示:
一个好的词嵌入应该具备以下一些性质:
- 性质1:含义相似的词汇它们在多维空间中的位置应该相互接近(或者说它们有较高的相似度的分数)。
- 性质2:含义不同的词汇它们在多维空间中的位置应该相互远离(或者说它们有较底的相似度的分数)。
词嵌入与词汇的特征的捕捉
上面介绍的关于词嵌入的例子似乎满足了性质1和性质2,但这远远还不够,因为它只捕捉了词义的相似性特征,在一般情况下我们需要捕捉词汇中的更多特征,在自然语言中,单词可以组合起来得到更复杂的含义。在数学中,数字可以相加或相减得到其他数字。我们能否构建一个词嵌入来捕获单词之间的关系,就像数字之间的关系一样?
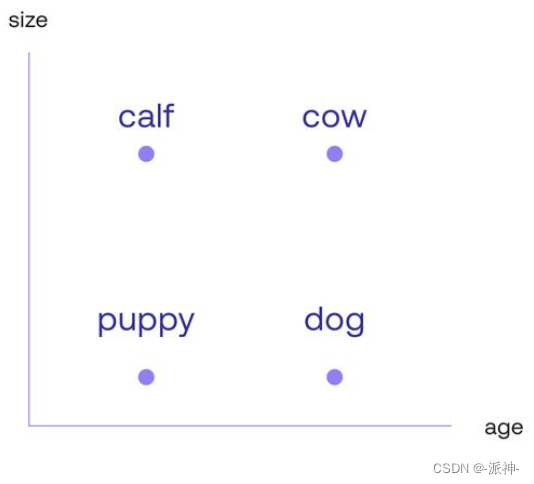
让我们看一下四个单词:“Puppy(小狗)”、“Dog(狗)”、“Calf(小牛)”和“Cow(牛)”。这些单词之间有着明显的相关性。现在我们将在平面网格中放入单词“Puppy”、“Dog”和“Calf”,然后希望您在网格中添加单词“Cow”。现在有三个可以先选择的位置 A、B 或 C 的位置,你会选择哪一个?
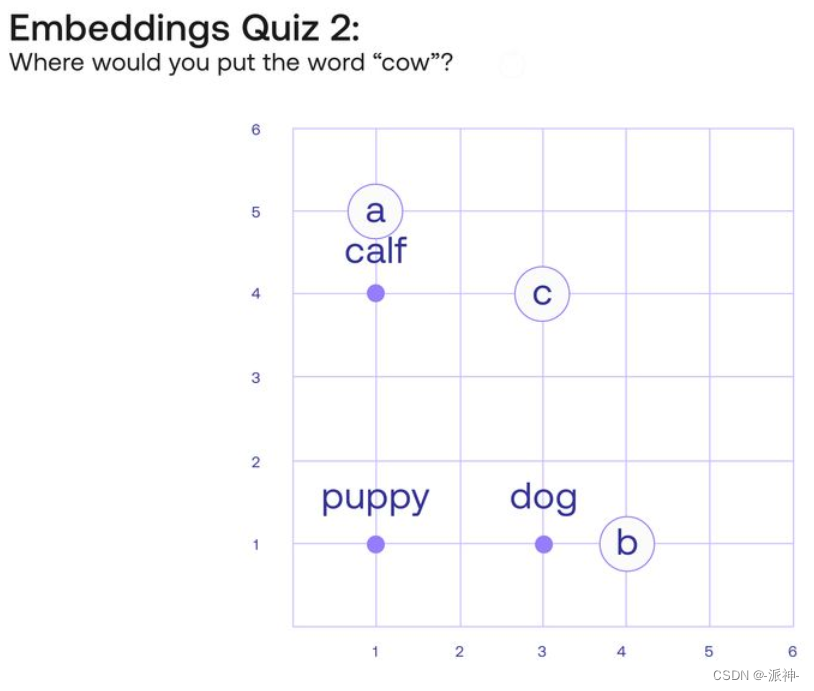
您可能会将“Cow(牛)”放入到位置 A 中,因为这样它会更接近“Calf(小牛)”,因为它们都是牛,或者放到位置在 B 中,因为它是成年动物,如“Dog(狗)”,但最合理的位置应该是C ,即坐标[3,4]。因为这四个词形成的矩形平面体现了词汇之间的一些非常重要的关系。例如,这里会有两个类比。类比“小狗之于狗,就像小牛之于牛”可以理解为“从单词“Puppy(小狗)”到单词“Dog(狗)”的路径与从单词“Calf(小牛)”到单词“Cow(牛)”的路径相同”。“狗之于牛,就像小狗之于小牛”的类比也体现在这个矩形中,如下图所示:
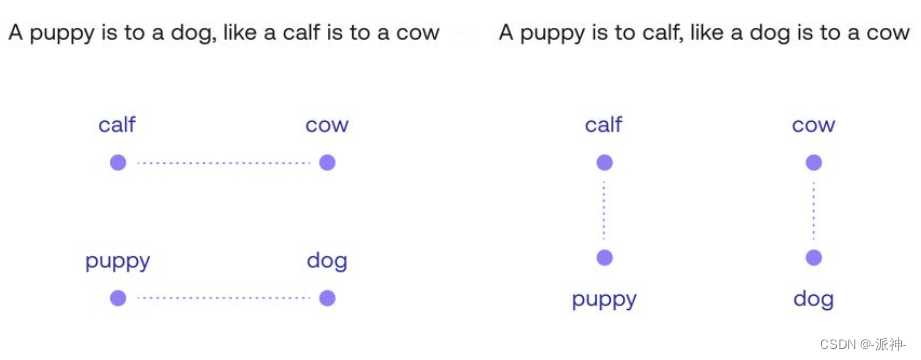
然而,这还不足以成为冰山一角。此处词嵌入的主要属性是两个轴(垂直和水平)它们代表不同的含义。仔细看,向右移动,小狗变成了狗,小牛变成了牛,这是随年龄的增长产生的变化。同样,向上移动会将小狗变成小牛,将狗变成牛,这是随动物体型的增大产生的变化。因此这种嵌入是在理解了单词包含的两个主要属性或特征:年龄和大小。此外,词嵌入似乎将年龄定位在横轴上,将大小定位在竖轴上。那么,你会想象“whale(鲸鱼)”这个词应该放置在什么位置?可能在“Cow(牛)”这个词上面的某个地方。如果有一个词可以形容“一条老狗”呢?这个词会出现在“dog”这个词右边的某个地方:
一个好的词嵌入不仅能够捕获年龄和大小,还能捕获单词的更多特征。由于每个特征都是一个新轴或坐标,因此良好的嵌入模型必须为每个单词分配两个以上的坐标。例如,Cohere 嵌入模型具有与每个单词关联的 4096 个维度。不同的维度可能代表单词的一些重要属性,例如年龄、性别、大小。有些可能代表属性的组合。但还有一些可能代表人类可能无法理解的晦涩属性。但总而言之,词嵌入可以被视为将人类语言(单词)翻译成计算机语言(数字)的好方法。
下面我们来看看如何在python中如何实现词嵌入,这里我们会使用cohere的词嵌入模型embed-english-v2.0,不过仍然还有很多开源的embedding模型可以使用,比如我之前博客中多次使用的bge的embedding模型,它不仅支持英文也能支持中文。不过这里我们出于演示的目的我们使用的是仅支持英文的cohere的词嵌入模型embed-english-v2.0,下面我们首先创建一个包含3个单词的dataframe:
import pandas as pdthree_words = pd.DataFrame({'text':['joy','happiness','potato']})three_words
这里我们有3个单词:“joy”、“happiness”、“potato”, 接下来我们调用cohere的embedding模型对这3个单词进行向量化,并查看每个词向量的长度:
three_words_emb = co.embed(texts=list(three_words['text']),model='embed-english-v2.0').embeddingsword_1 = three_words_emb[0]
word_2 = three_words_emb[1]
word_3 = three_words_emb[2]print(len(word_1))
print(len(word_2))
print(len(word_3))
这里我们看到每个词向量的长度都是4096,也就是说在cohere中一个英文单词可以由4096个维度特征来表示,下面我们看看词向量的具体向量值是多少:
word_1[:10]
这里我们查看了“word_1”前10个维度的值,它们都是由0附近的浮点数组成。
二、句子嵌入(Sentence Embeddings)
词嵌入看起来非常有用,但实际上,人类语言比简单的一堆单词放在一起要复杂得多。一个单词摆放在一个句子中的不同位置可能给这个句子带来不同的含义,句子要比单词更能清晰的表达出人类语言的含义,句子嵌入就像单词嵌入一样,只不过它以连贯的方式将每个句子与充满数字的向量相关联。这里所说的连贯性是指它满足与词嵌入类似的属性。例如,内容相似的句子被分配给相似的向量,不同的句子被分配给不同的向量,最重要的是,向量的每个坐标都标识了句子的一些(无论是清晰的还是模糊的)属性:
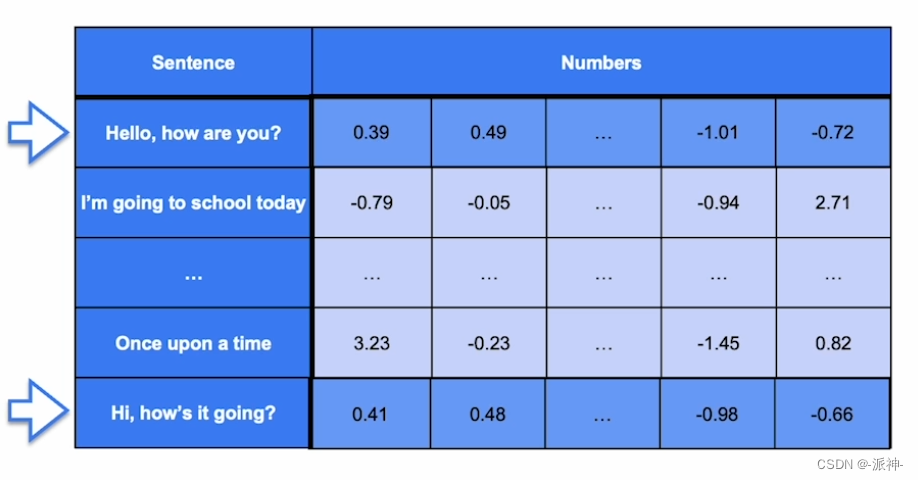
在上图中句子“Hello, how are you?”与句子“Hi, how's it going?”在英语中都表示朋友见面时相互打招呼的意思,因此这两个句子含义相同它们会被分配相似的向量值。而cohere的embedding模型采用“transformers”, “attention ”机制以及其他一些尖端算法,它会将一个句子转换成4096个维度的向量。下面我们来看看如何在python中实现cohere的Sentence Embeddings:
sentences = pd.DataFrame({'text':['Where is the world cup?','The world cup is in Qatar','What color is the sky?','The sky is blue','Where does the bear live?','The bear lives in the the woods','What is an apple?','An apple is a fruit',]})sentences
这里我们生成了一组句子,这组句子由4个问题和4个答案组成,显然问题答案与问题之间是相互关联的,下面我们对这些句子进行向量化处理,然后我们查看以下这些句子向量的前3个维度的向量值:
emb = co.embed(texts=list(sentences['text']),model='embed-english-v2.0').embeddings# Explore the 10 first entries of the embeddings of the 3 sentences:
for e in emb:print(e[:3])
下面我们来查看一下每个句子向量的长度:
for e in emb:print(len(e))
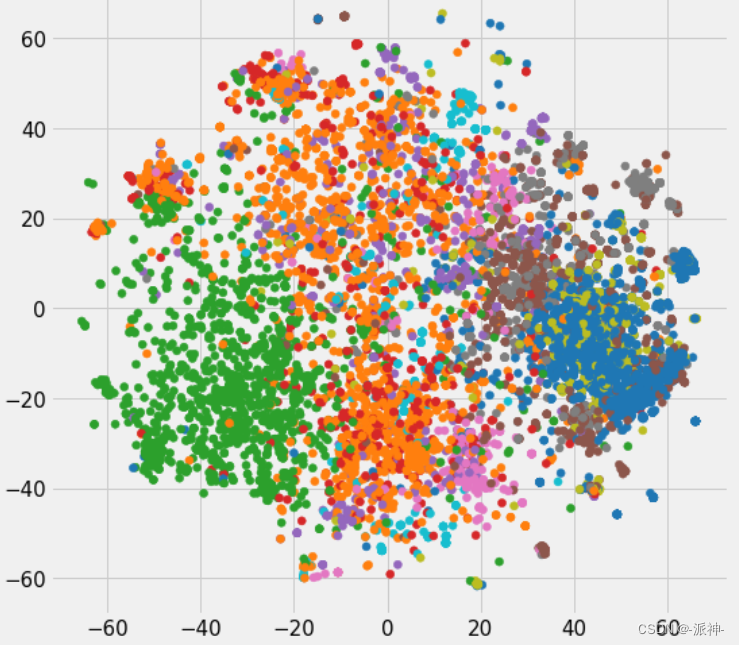
这里我们看到8个句子的向量长度都是4096,接下来我们对些句子向量进行可视化,我们通过UMAP(uniform manifold approximation and projection)算法对句子向量的4096个维度进行降维后画出句子向量的散点图,UMAP算法是近年来新出现的一种相对灵活的非线性降维算法,目前在统计遗传学等领域也有了较为广泛的应用。接下来我们首先定义一个绘图函数,然后我们会利用这个绘图函数来画出这8个句子向量的散点图,当我们单击图中的某个点时将会看到对应的句子内容:
import umap
import altair as altdef umap_plot(text, emb):cols = list(text.columns)reducer = umap.UMAP(n_neighbors=2)umap_embeds = reducer.fit_transform(emb)df_explore = text.copy()df_explore['x'] = umap_embeds[:,0]df_explore['y'] = umap_embeds[:,1]# Plotchart = alt.Chart(df_explore).mark_circle(size=60).encode(x=#'x',alt.X('x',scale=alt.Scale(zero=False)),y=alt.Y('y',scale=alt.Scale(zero=False)),tooltip=cols#tooltip=['text']).properties(width=700,height=400)return chartchart = umap_plot(sentences, emb)
chart.interactive()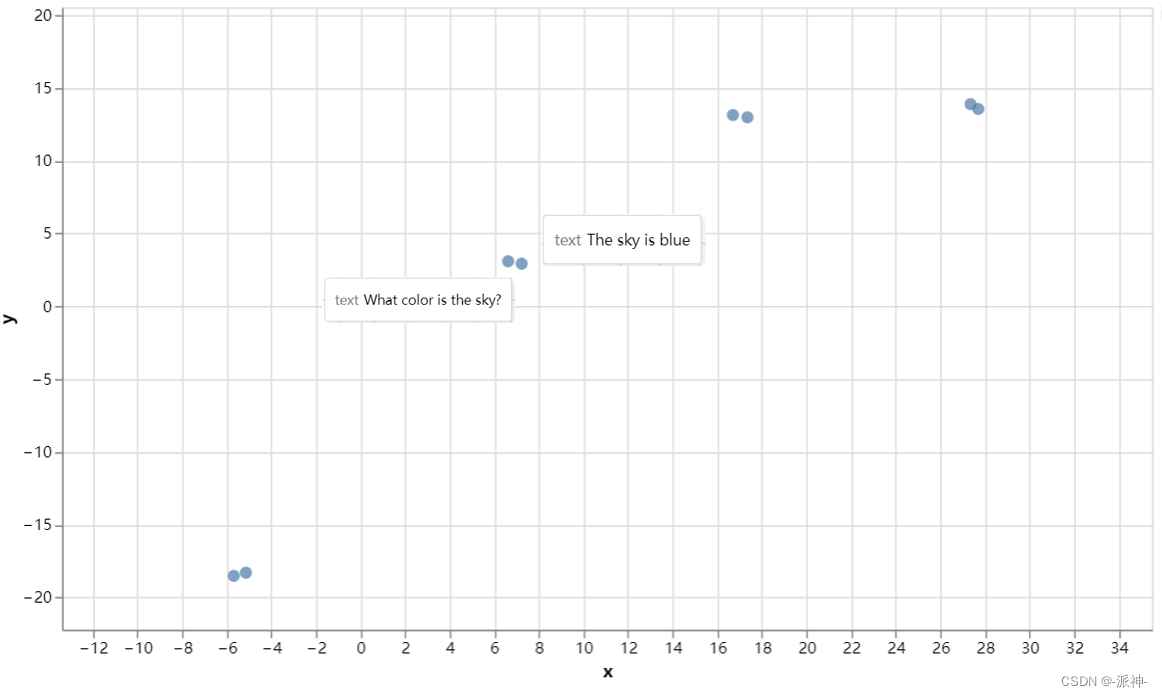
从输出图像上看,句子内容相关的向量点都相互靠的很近,而句子内容不相关的点都相互远离。这也进一步说明句子嵌入能更好的从语义上识别内容相关的句子。
三、文章嵌入
上面我们介绍了单一句子嵌入,同样我们也可以实现多个句子的嵌入,即文章嵌入,接下来我们导入一个已做嵌入的维基百科文章的数据集,然后对文章向量进行可视化:
import pandas as pdwiki_articles = pd.read_pickle('wikipedia.pkl')
wiki_articles
接下来我们根据该数据集的emb字段来绘制散点图,图中的每一个点表示wiki_articles的一个text,不过首先我们需要定义一个绘图函数umap_plot_big,在函数中我们调用umap的降维算法将原先的4096个维度降到两个维度,这样我们才能在二维平面中画出散点图:
import numpy as npdef umap_plot_big(text, emb):cols = list(text.columns)reducer = umap.UMAP(n_neighbors=100)umap_embeds = reducer.fit_transform(emb)df_explore = text.copy()df_explore['x'] = umap_embeds[:,0]df_explore['y'] = umap_embeds[:,1]# Plotchart = alt.Chart(df_explore).mark_circle(size=60).encode(x=#'x',alt.X('x',scale=alt.Scale(zero=False)),y=alt.Y('y',scale=alt.Scale(zero=False)),tooltip=cols#tooltip=['text']).properties(width=700,height=400)return chartarticles = wiki_articles[['title', 'text']]
embeds = np.array([d for d in wiki_articles['emb']])chart = umap_plot_big(articles, embeds)
chart.interactive()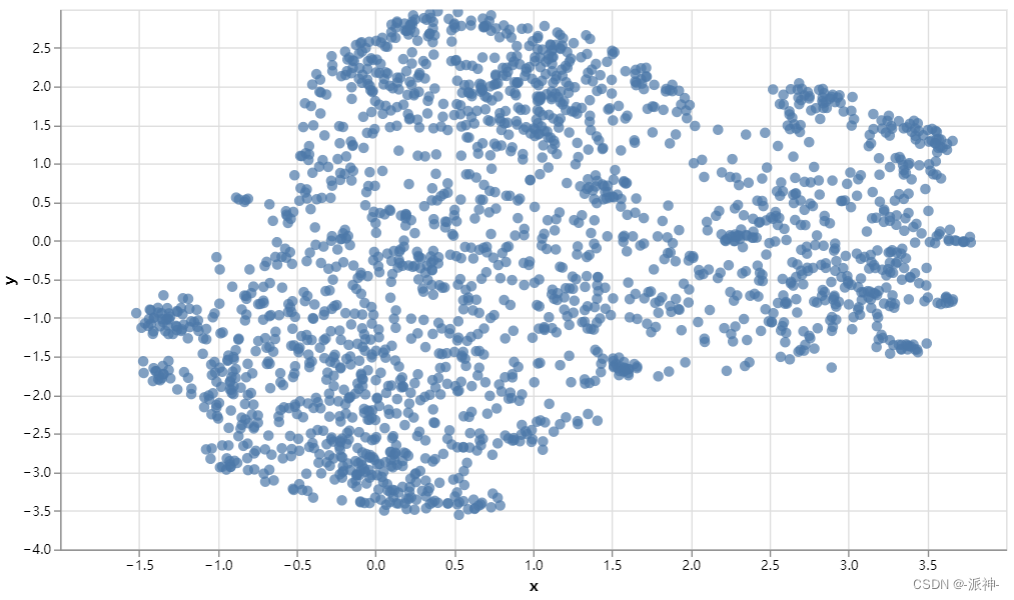
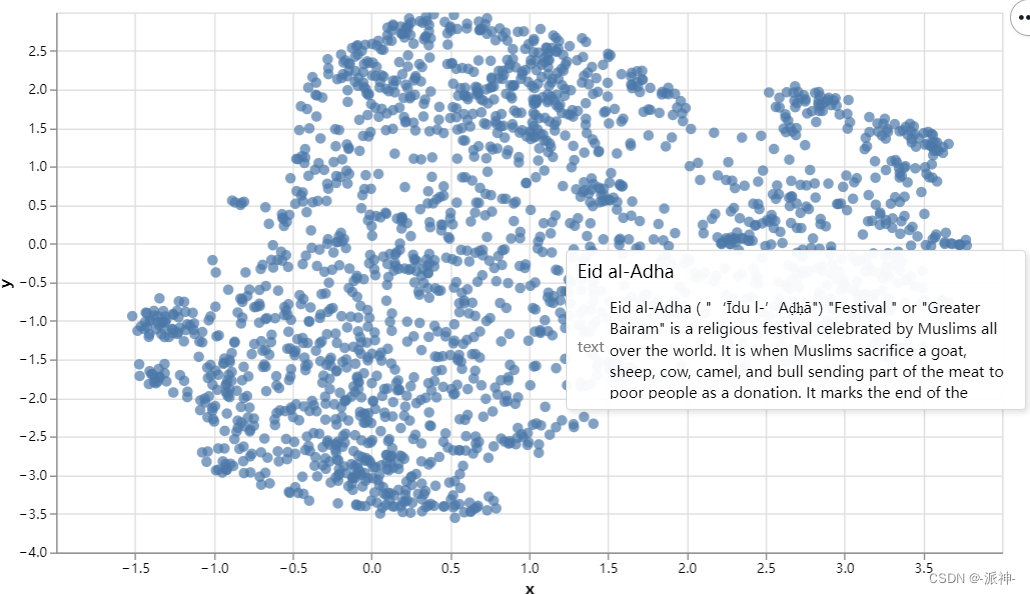
当我们单击图中某个点时将会看到对应的title 和 text:
四、总结
单词和句子嵌入是大型语言模型(LLM)的主要工作。它们是大多数语言模型的基础构件,它通过捕获了单词、语义和语言细微差别之间的许多关系,并将其转换为有关相应数字,从而将人类语言(单词)翻译为计算机能理解的语言(数字)。
这篇关于大型语言模型的语义搜索(二):文本嵌入(Text Embeddings)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






