本文主要是介绍【论文笔记】Active Domain Adaptation via Clustering Uncertainty-weighted Embeddings(ICCV2021),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:Active Domain Adaptation via Clustering Uncertainty-Weighted Embeddings
代码:https://github.com/virajprabhu/CLUE
本人计算机视觉研究僧,欢迎交流。
Abstract
本文通过主动学习方式,解决在域适应问题(Domain adaptation)中,选择信息量最大的目标域(target domain)子集做标签,得到最大的域适应性能效益,本文称此问题为主动域适应(Active DA)。提出了基于特征(embeding)不确定性加权的聚类,选择权衡了模型不确定性和特征空间多样性的目标域样本,在多个域适应数据集,多种域适应训练的范式下,实现了比其他样本选择策略取得了更好的域适应效果。
1. Introduction
2. Related Works
3. Method
3.1 问题设定
我们讨论主动学习增益域适应问题,与传统的推广在源域上训练的模型指向未标记的目标域的域适应问题不同的是,可以选择查询一小部分目标域数据的标签,本文研究的就是如何用主动学习选择足有价值的这批数据来标注。
3.2 基于特征不确定性加权的聚类(Clustering Uncertainty-weighted Embeddings)
认为在model输出的熵在域适应问题中可以代表样本的不确定性(uncertainty)和域难分性(domainness),并认为熵越大越倾向于目标域特有的样本。
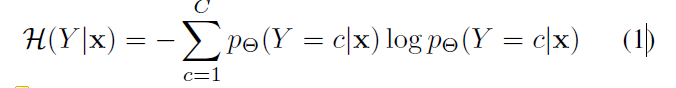
下一步是定义多样性。这里用的是特征提取器的embedding(也就是分类头之前一层的特征),根据embedding作为输入,希望将目标域数据(此时均为未标注)划分为K个尽可能不同的子集。设聚类的优化对象是每个子集的中心,选到最好的子集中心的依据有两方面:一方面是要把一个子集中的样本对之间的方差优化的小一点,这同时将导致不同子集之间的样本对之间的方差大:
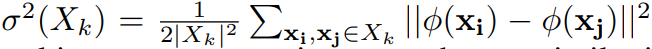
上式中, ϕ ( x ) \phi(x) ϕ(x)是数据x的embedding。
另一方面是要在划分的时候要把每个子集中元素和中心的距离优化的小一点,这里用到了不确定作为距离的权重,为之后不确定性和多样性的权衡(trade-off)作了准备:
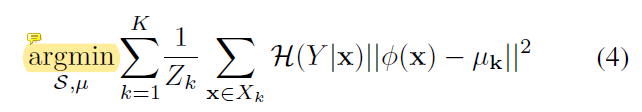
在选择样本的时候希望得到的重要性权重是模型不确定性和特征空间的多样性之间的平衡,权衡就是通过温度T实现。提高 T T T则是提高了每个样本每个预测类的熵,那么每个样本的不确定都很大没有很大的差距,这时候多样性占到了主导作用。反之亦然。
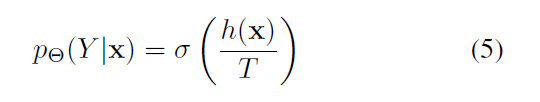
上式中, T T T是可控温度, h ( x ) h(x) h(x)是样本x的分类logits。
选择样本的时候选择每个簇中与簇中心最近的样本做标注,得到本轮的标注图像,通过半监督域适应的模型更新方式的算法的完整流程如下图。

Domain adaptation
获取标签后进入主动DA的下一步训练,已有的数据包括:获取的目标数据标签、有标记的源数据和未标记的目标数据。在实验中,用三种学习策略:
i)根据目标数据标签对源域模型进行finetune
ii)根据DANN[10]增加一个目标交叉熵损失,实现领域对抗性学习
iii)通过极大极小熵(MME[33),实现半监督域适应
三种设定下的实验效果都还优越于其他策略,说明了选择的样本集的有效性。
4. Experiment
这篇文章开源,方法简单但在多个分类数据集上多种设定已经丰富的参数设定下给出了有说服力的结果。笔者仍然在复现实验,本文有10个赞再更新对实验的分析。
Ref
[10] Unsupervised domain adaptation by backpropagation.(ICML2015)
[33] Semi-supervised domain adaptation via minimax entropy. (ICCV2019)
这篇关于【论文笔记】Active Domain Adaptation via Clustering Uncertainty-weighted Embeddings(ICCV2021)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







