robust专题

Image Transformation can make Neural Networks more robust against Adversarial Examples
Image Transformation can make Neural Networks more robust against Adversarial Examples 创新点 1.旋转解决误分类 总结 可以说简单粗暴有效

Segmentation简记2-RESIDUAL PYRAMID FCN FOR ROBUST FOLLICLE SEGMENTATION
创新点 与resnet结合,五层/level的分割由此带来的梯度更新问题,设计了两种方案。 总结 有点意思。看图吧,很明了。 细节图: 全流程图: 实验 Res-Seg-Net-horz: 在UNet上堆叠5个细节图中的结构,没有上采样层。 Res-Seg-Net-non-fixed: 普通方式的更新 Res-Seg-Net-fixed: 每一层的更新,只依据距离它最近的一

论文泛读: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
文章目录 TransNeXt: Robust Foveal Visual Perception for Vision Transformers论文中的知识补充非QKV注意力变体仿生视觉建模 动机现状问题 贡献方法 TransNeXt: Robust Foveal Visual Perception for Vision Transformers 论文链接: https://o

2010-ECCV - Two-phase kernel estimation for robust motion deblurring
项目地址:http://www.cse.cuhk.edu.hk/~leojia/projects/robust_deblur/index.html 贾佳亚团队 边缘预测与边缘选择,过滤细微结构对于模糊核估计的影响分两阶段估计模糊核,第一阶段:L2范数,第二阶段:L1范数图像先验,在估计模糊核过程中使用空间结构先验,非盲阶段时使用TV范数 文章首先了图像结构如何影响模糊核结构: Salien
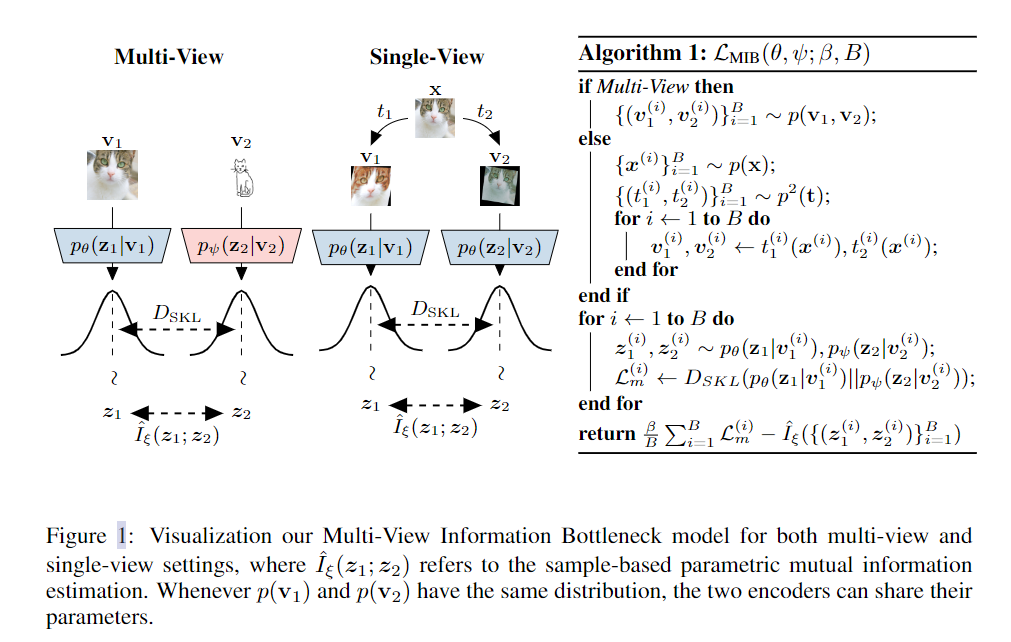
论文学习 Learning Robust Representations via Multi-View Information Bottleneck
Code available at https://github.com/mfederici/Multi-View-Information-Bottleneck 摘要:信息瓶颈原理为表示学习提供了一种信息论方法,通过训练编码器保留与预测标签相关的所有信息,同时最小化表示中其他多余信息的数量。然而,最初的公式需要标记数据来识别多余的信息。在这项工作中,我们将这种能力扩展到多视图无监督设置,其中提供
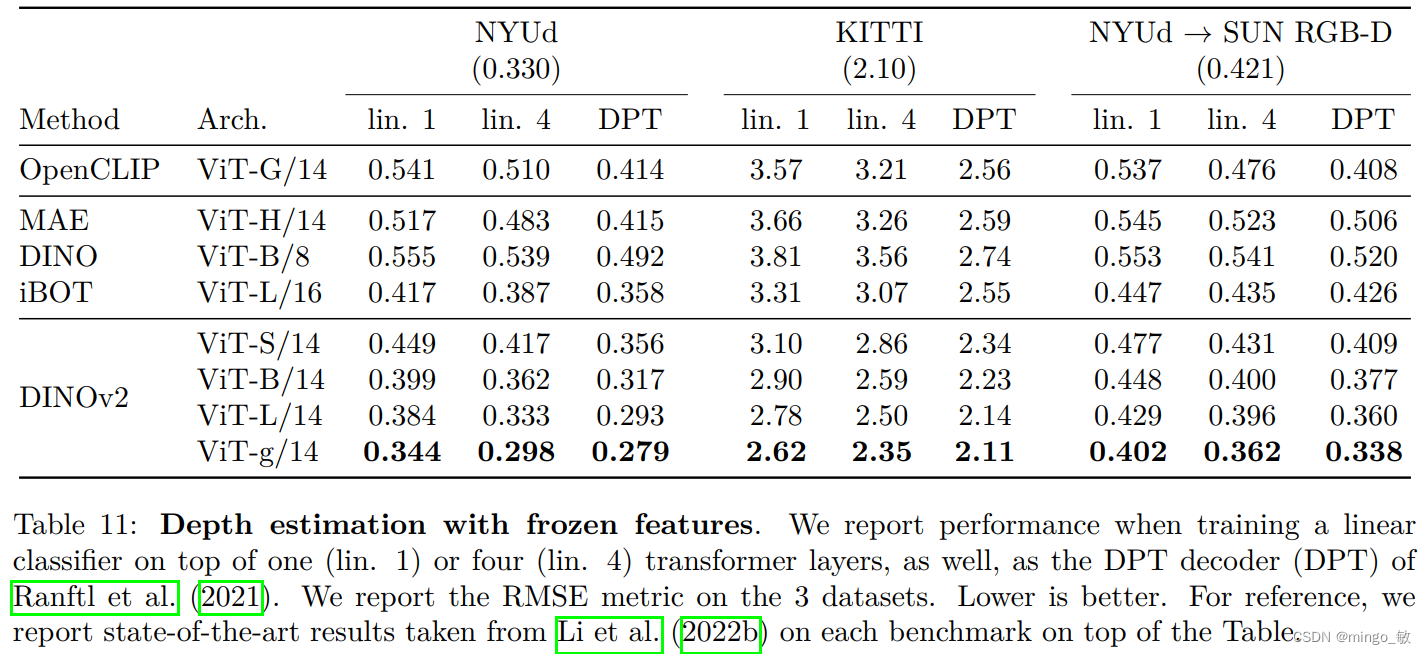
深度学习论文: DINOv2: Learning Robust Visual Features without Supervision
深度学习论文: DINOv2: Learning Robust Visual Features without Supervision DINOv2: Learning Robust Visual Features without Supervision PDF: https://arxiv.org/abs/2304.07193 PyTorch代码: https://github.com/shan

【机器学习论文阅读笔记】Robust Recovery of Subspace Structures by Low-Rank Representation
前言 终于要轮到自己汇报了好崩溃。。盯着论文准备开始做汇报ppt感觉一头乱麻,决定还是写博客理清思路再说吧 参考资料: 论文原文:arxiv.org/pdf/1010.2955 RPCA参考文章:RPCA - 知乎 (zhihu.com) 谱聚类参考文章:谱聚类(spectral clustering)原理总结 - 刘建平Pinard - 博客园 (cnblogs.com) 一、问题描

论文解读 Combating Adversarial Misspellings with Robust Word Recognition
1. 简介 论文链接 https://www.aclweb.org/anthology/P19-1561.pdf 这篇文章发表在ACL19,目的是为了解决错误拼写的对抗(adversarial misspellings)问题。尽管现在的deep learning和Transformer已经非常先进,但是当他们面对错误拼写时仍然十分的脆弱(brittle),一个单词的字母写错就可以愚弄(fool

数字水印 | 图像标准化论文:Digital Watermarking Robust to Geometric Distortions(一)
目录 II Watermark Based on Image NormalizationA 图像的矩和仿射变换B 图像的标准化 🤖原文: Digital Watermarking Robust to Geometric Distortions 🤖前言: 这是一篇 2005 年的 SCI 一区 + CCF-A,但是网上关于它的讲解貌似挺少的。文中提出了两种数字水印方

数字水印 | 图像标准化论文:Digital Watermarking Robust to Geometric Distortions(二)
目录 C 变换参数的确定D 水印的影响E 可替代的标准化过程 🤖原文: Digital Watermarking Robust to Geometric Distortions 🤖前言: 这是一篇 2005 年的 SCI 一区 + CCF-A,但是网上关于它的讲解貌似挺少的。文中提出了两种数字水印方案,但是我只关注第一种方案中的图像标准化技术。由于本人很菜,因此可
NID-SLAM: Robust Monocular SLAM using Normalised Information Distance - Part2
在上一篇博客中, 我介绍了NID-SLAM中的的Robust Direct NID Tracking的实现。这篇继续记录一下文章中 Multi-resolution NID Tracking的部分。 Multi-resolution NID Tracking 文中提到LSD-SLAM中为提高鲁棒性而使用image-pyramid的方法。LSD-SLAM中是对待匹配的原始图像建立图像金字塔。NI

Paper Share_ NID-SLAM_ Robust Monocular SLAM using Normalised Information Distance
【写在前面】 一直都有写博客的意愿,但是一直都没有实际行动。尝试了几次也都没有坚持下来。这次打算逼自己一下,坚持下去。 这次决心坚持写博客也是出于记录平时自己日常所学的考虑。平时有时间或者需要会去看论文,但是一篇论文当时看的时候似乎是懂了,但是过几天就没什么印象了。感觉这样效果很不好。所以打算写博客记录自己所看的论文。其一是加深自己的理解,其二是记录分析的内容和过程,方便日后查看与

Enterprise Java 2 Security: Building Secure and Robust J2EE Applications
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Enterprise Java(TM) Security: Building Secure J2EE(TM) Applications provides application developers and
鲁棒线性模型估计(Robust linear model estimation)
鲁棒线性模型估计 1.RANSAC算法1.1 算法的基本原理1.2 迭代次数N的计算1.3 参考代码 参考文献 当数据中出现较多异常点时,常用的线性回归OLS会因为这些异常点的存在无法正确估计线性模型的参数: W = ( X T X ) − 1 X T Y \qquad \qquad W=(X^TX)^{-1}X^TY W=(XTX)−1XTY 此时就需要寻找更鲁棒的方法过滤掉

【ViT系列】TransNeXt: Robust Foveal Visual Perception for Vision Transformers
论文链接:https://arxiv.org/pdf/2311.17132.pdf 代码链接:https://github.com/DaiShiResearch/TransNeXt 一、摘要 1、引入了Pixel-focused Attention(PFA),它采用双路径设计。在一个路径中,每个查询对其最近邻特征具有细粒度的注意力,而在另一个路径中,每个查询对空间下采样特征具有粗粒度的注

PSENet:Shape Robust Text Detection with Progressive Scale Expansion Network ---- 论文翻译
论文地址:https://arxiv.org/abs/1903.12473 论文解读:https://blog.csdn.net/m0_38007695/article/details/96438264 渐进式扩展网络的形状鲁棒文本检测 摘要 场景文本检测已经取得了快速进展,特别是随着最近卷积神经网络的发展。但是,仍然存在两个阻碍算法进入工业应用的挑战。一方面,大多数现有技术都需要四边

论文阅读——Efficient and Robust Feature Selection via Joint L2,1-Norms Minimization
一、前言 最近因为对结构化多任务学习,以及对带范数目标函数求解的学习,一直都很想求解带L2,1范数的目标函数(其实这只是个过程),针对这样的不光滑目标函数,梯度下降法并不合适。 虽然sklearn中的MultiTaskLasso也是这样的目标函数,并且使用了坐标下降法来求解,但是当目标函数中的损失函数也用L2,1范数时我又懵圈了。 正当我琢磨是不是能把两部分合在一起求解一个L2,1范数时(其
Robust Neural Network for Novelty Detection on Data Streams
基本信息 题目:Robust Neural Network for Novelty Detection on Data Streams. 会议: International Conference on Artificial Intelligence and Soft Computing. 出版社: Springer-Verlag, 2012:178-186. 作者:Andrzej Rusi

A Robust and Simple Measure for Quality-Guided 2 D Phase Unwrapping Algorithms
A Robust and Simple Measure for Quality-Guided 2 D Phase Unwrapping Algorithms 论文总共分为六个部分,分别是:介绍,质量引导求解相位,残差点,载波信号的影响,本文建议的求解质量方法,实验与结论。 质量引导解包 本节中介绍的质量引导解包是2002年的一篇文章:Fast two dimensional phase-unw

【论文简述】MVSFormer:Multi-View Stereo by Learning Robust Image Features and Temperature-based(TMLR 2023)
一、论文简述 1. 第一作者:Chenjie Cao 2. 发表年份:2023 3. 发表期刊:TMLR 4. 关键词:MVS、3D重建、预训练、Vision Transformers 5. 探索动机:正则化并不能完全纠正来自反射或无纹理区域的模糊特征匹配,这些区域具有不可靠的2D图像特征。因此,在特征提取过程中学习良好的代表性特征,对于提高MVS的泛化程度仍具有重要意义。此前很少有工作
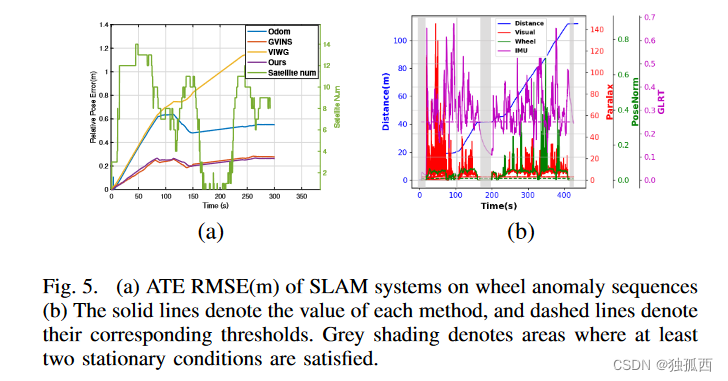
论文阅读:Ground-Fusion: A Low-cost Ground SLAM System Robust to Corner Cases
前言 最近看到一篇ICRA2024上的新文章,是关于多传感器融合SLAM的,好像使用了最近几年文章中较火的轮式里程计。感觉这篇文章成果不错,代码和数据集都是开源的,今天仔细读并且翻译一下,理解创新点、感悟研究方向、指导自己的研究。这篇文章通篇略读,主要做了工作做了一个紧耦合的RGBD - Wheel - IMUGNSS SLAM系统,然后加了两个创新点工作,一个是初始化,一个是传感器退化检测。
Learning by tracking:Siamese CNN for robust target association
来源:arXiv:1604.07866v3 Aug 2016 Abstract 本文介绍了一种新的数据关联的方法,引入两阶段(two-stage)学习的模式来匹配检测对。 First,训练了一个孪生卷积神经网络来学习编码两个输入图像块的之间的local spatio-temporal structures,把像素值和光流信息给聚合起来。 Second,一系列上下文特征derived fro
![[深度估计]RIDERS: Radar-Infrared Depth Estimation for Robust Sensing](https://img-blog.csdnimg.cn/direct/59775cc2cdb84404b75b21fd2f2dbd31.png#pic_center)
[深度估计]RIDERS: Radar-Infrared Depth Estimation for Robust Sensing
RIDERS: 恶劣天气及环境下鲁棒的密集深度估计 论文链接:https://arxiv.org/pdf/2402.02067.pdf 作者单位:浙江大学, 慕尼黑工业大学 代码链接:https://github.com/MMOCKING/RIDERS 1. 摘要(Abstract) 恶劣的天气条件, 包括雾霾、灰尘、雨雪和黑暗, 给准确的密集深度估计带来了巨大挑战。对于依赖
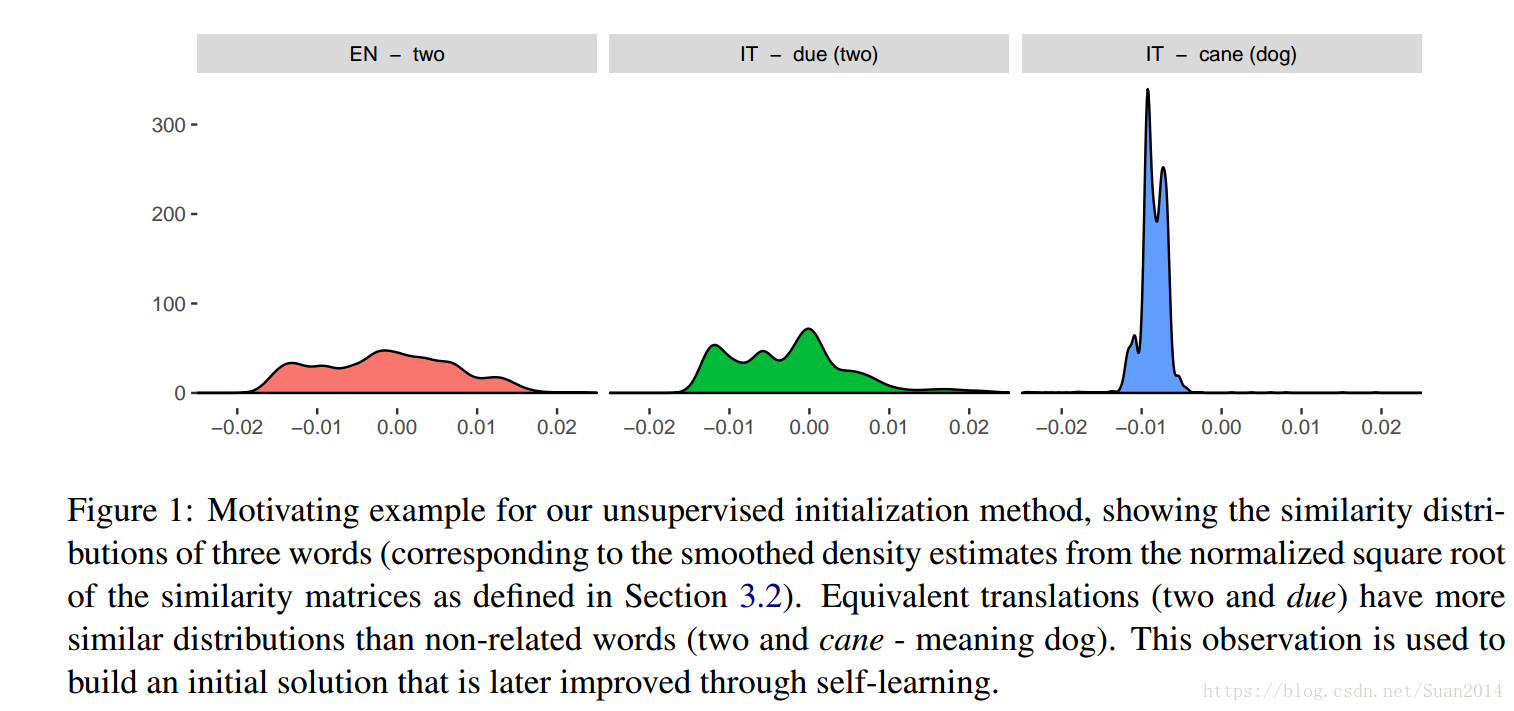
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings论文笔记
回看前几篇笔记发现我剪贴的公式显示很乱,虽然编辑时调整过了,但是不知道为什么显示的和编辑时的不一样,为方便大家的阅读,我开始尝试着采用markdown的形式写笔记,前几篇有时间的话再修改。 这篇论文阅读完,我依然有很多不懂的地方,对其操作不是很清晰,因为我没做过这方面的内容,且近期估计没时间学习其项目,所以记录理解的可能有误,希望大家带着思考阅读。 PS:感觉这篇文章的作者是这个方向的大神呢,
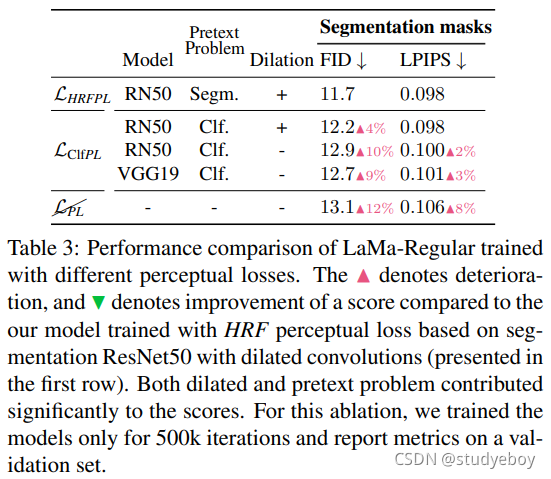
Resolution-robust Large Mask Inpainting with Fourier Convolutions(2021)
[Paper] Resolution-robust Large Mask Inpainting with Fourier Convolutions(2021) [Code]saic-mdal/lama 基于傅里叶卷积的分辨率稳健的大型掩码修复 现在的图像修复系统,尽管取得了重大进展,但经常与大面积缺失区域、复杂几何结构和高分辨率图像做斗争。我们发现造成这种情况的主要原因之一是修复网络和损失函

ECOC 2020 Th1D-4 End-to-End Deep Learning for Phase Noise-Robust Multi-Dimensional Geometric Shaping
有作者在ECOC上讲的视频 https://www.youtube.com/watch?v=8pLfItf_yws&t=271s 一种针对相位噪声的端到端学习模型,在autoencoder中加入了卷积层,模型有2dB的增益。 背景: 相位噪声是相干光通信系统中很大的问题,有很多关于载波相位估计和相位噪声增强技术。比如,log-likelihood ratio (LLR)用来处理参与相位噪声