本文主要是介绍深度学习论文: DINOv2: Learning Robust Visual Features without Supervision,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深度学习论文: DINOv2: Learning Robust Visual Features without Supervision
DINOv2: Learning Robust Visual Features without Supervision
PDF: https://arxiv.org/abs/2304.07193
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
提出一种自监督学习方法DINOv2,可在不需要微调的情况下,生成适用于各种图像分布和任务的通用视觉特征,使用精心筛选的大量图像数据进行预训练,并利用自动流程构建数据集以提高稳定性并加速训练。

2 Data Processing
本文创建了LVD-142M数据集,通过从大量未筛选的网络数据中挑选与现有筛选数据集相似的图像。数据管道包括筛选/未筛选数据源、图像去重和检索系统,直接处理图像,不依赖元数据或文本。
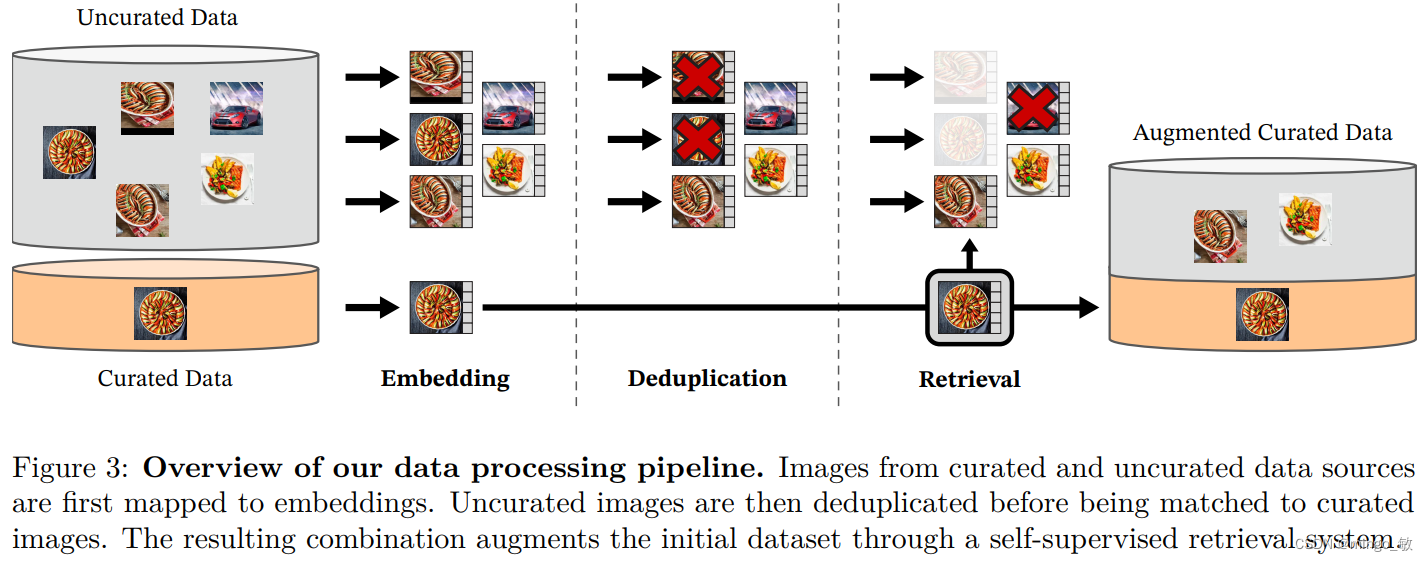
数据源包括多个筛选数据集如ImageNet,以及从公开网络爬取的未筛选图像。从网页中提取图像URL,并进行后处理,包括去重、过滤不当内容和模糊人脸,最终获得12亿张独特图像。
去重阶段使用现有技术移除近乎重复图像,提高数据多样性。自监督图像检索通过计算图像嵌入和余弦相似度,从未筛选数据中挑选与筛选数据集中图像接近的图像。
实现细节方面,使用Faiss库进行高效的索引和批量搜索最近嵌入,利用GPU加速处理,并通过计算集群在不到两天的时间内完成了LVD-142M数据集的生成。
3 Discriminative Self-supervised Pre-training
本文采用自监督学习方法来训练特征,结合了DINO、iBOT损失和SwAV居中。同时还加入了特征分散的正则化器和高分辨率训练阶段。
-
图像级目标:计算学生和教师网络提取特征间的交叉熵损失,使用DINO头处理类标记,并通过softmax和居中处理得到损失项。
-
补丁级目标:对学生网络的输入补丁进行随机遮蔽,应用iBOT头处理掩码标记,计算损失项。
-
头权重解耦:DINO和iBOT损失使用独立的MLP头,避免参数共享。
-
Sinkhorn-Knopp居中:采用SwAV的居中方法进行批归一化。
-
KoLeo正则化:基于Kozachenko-Leonenko熵估计器,促使批次内特征均匀分布。
-
分辨率调整:在预训练的最后阶段提高图像分辨率至518×518,以适应像素级任务需求。
4 Efficient implementation
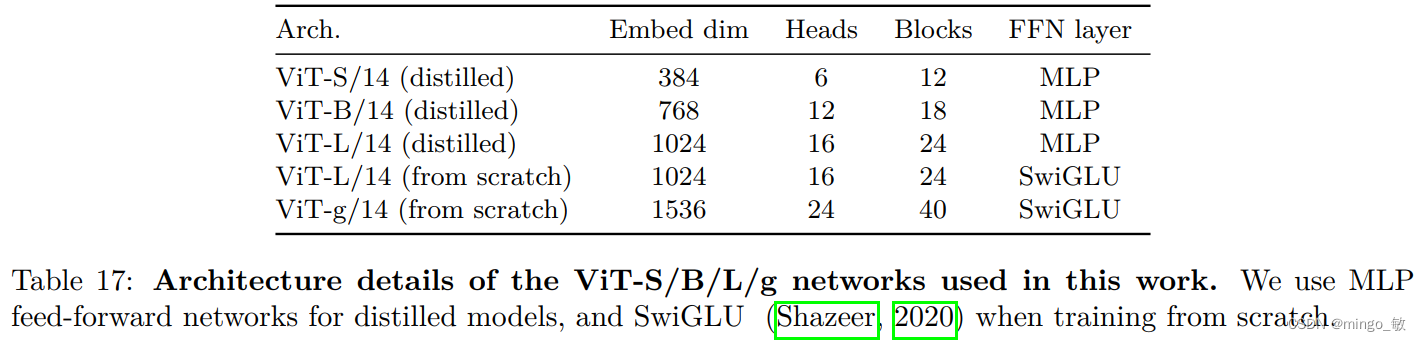
为了在更大规模上训练模型,采用了以下改进措施:
-
快速内存高效注意力:实现了改进版的FlashAttention,提高自注意力层的内存使用效率和速度。
-
序列打包:采用序列打包技术,将不同长度的标记序列合并为一个长序列,提高训练效率。
-
高效随机深度:改进随机深度实现,跳过丢弃残差的计算,节省内存和计算资源。
-
全分片数据并行(FSDP):使用FSDP跨GPU分割模型副本,减少内存占用,提高计算效率和扩展性。
-
模型蒸馏:对于较小模型,采用知识蒸馏方法,从最大的ViT-g模型中提取知识,而不是从头开始训练。
这些技术改进旨在提高大规模数据集上大型模型的训练效率,同时保持或提高最终模型的性能。通过蒸馏方法,即使是较小的模型也能获得与大型模型相似的性能。
5 Results
5-1 ImageNet Classification

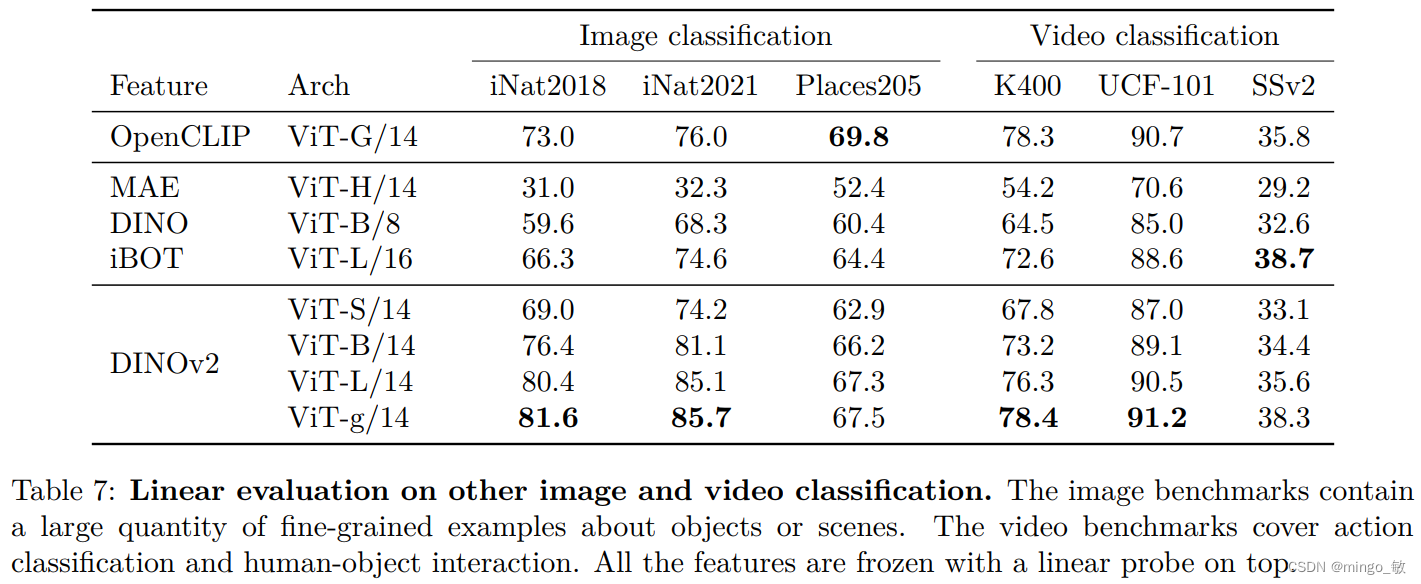
5-2 Image and Video classification Benchmarks
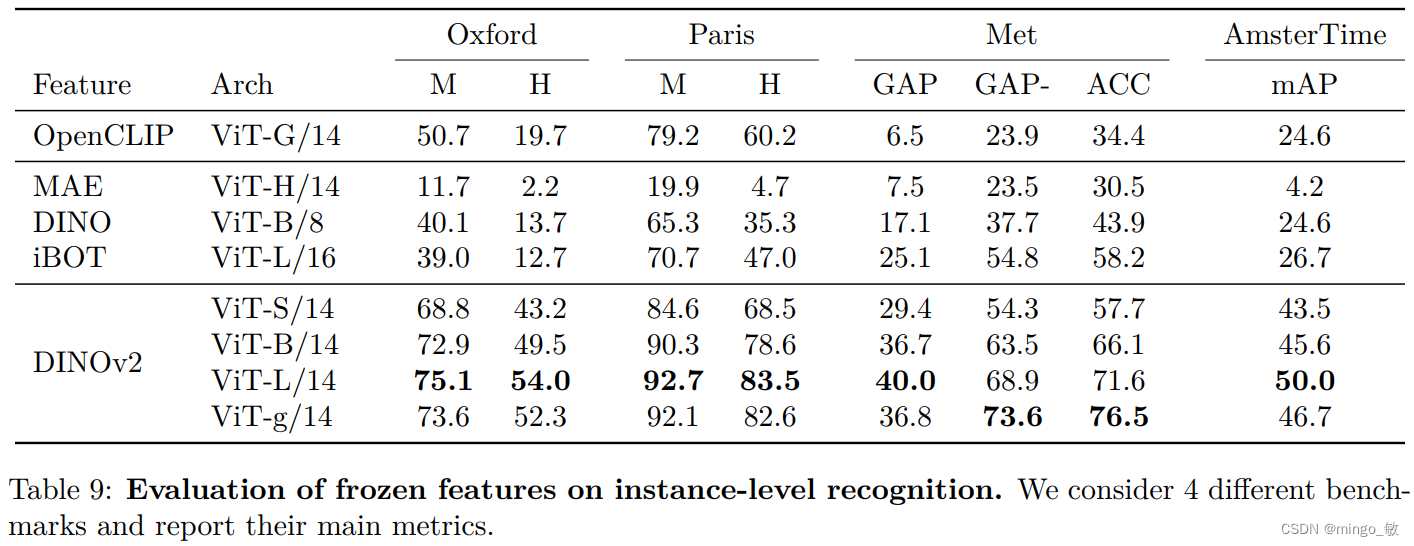
5-3 Instance Recognition
5-4 Semantic segmentation

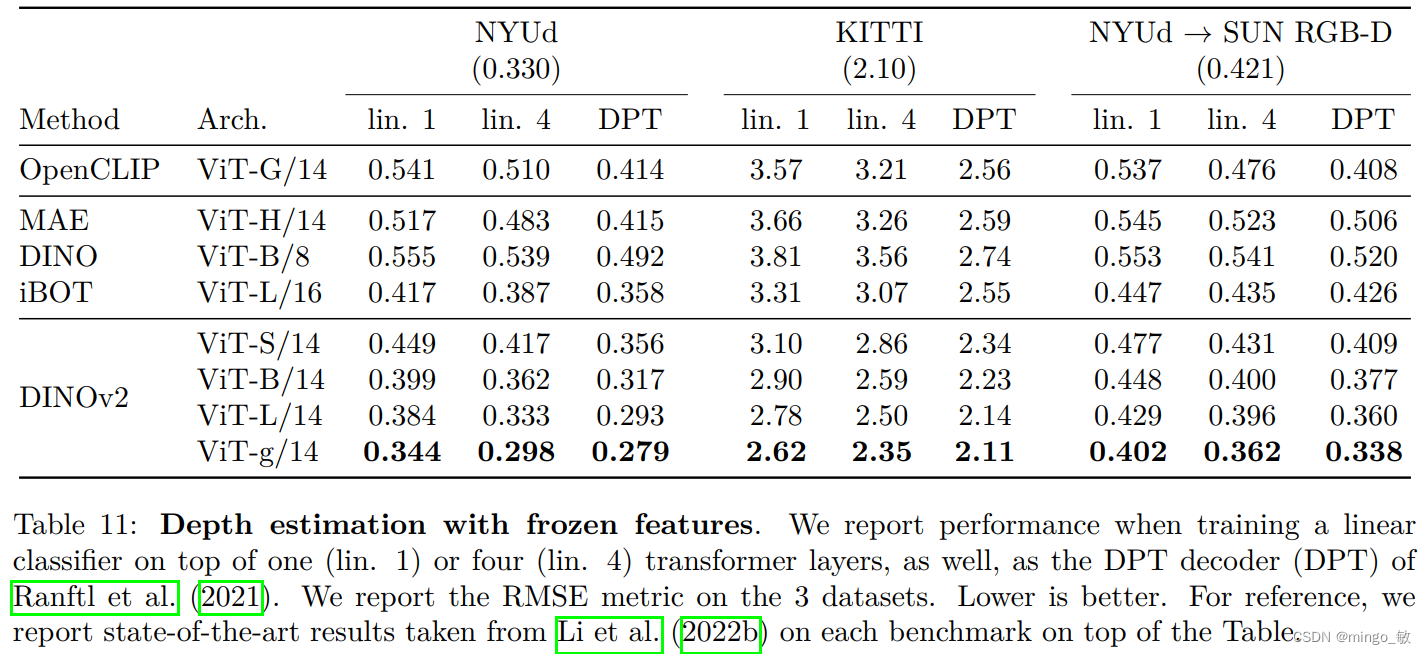
5-5 Depth estimation
这篇关于深度学习论文: DINOv2: Learning Robust Visual Features without Supervision的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




