dinov2专题
深度学习论文: DINOv2: Learning Robust Visual Features without Supervision
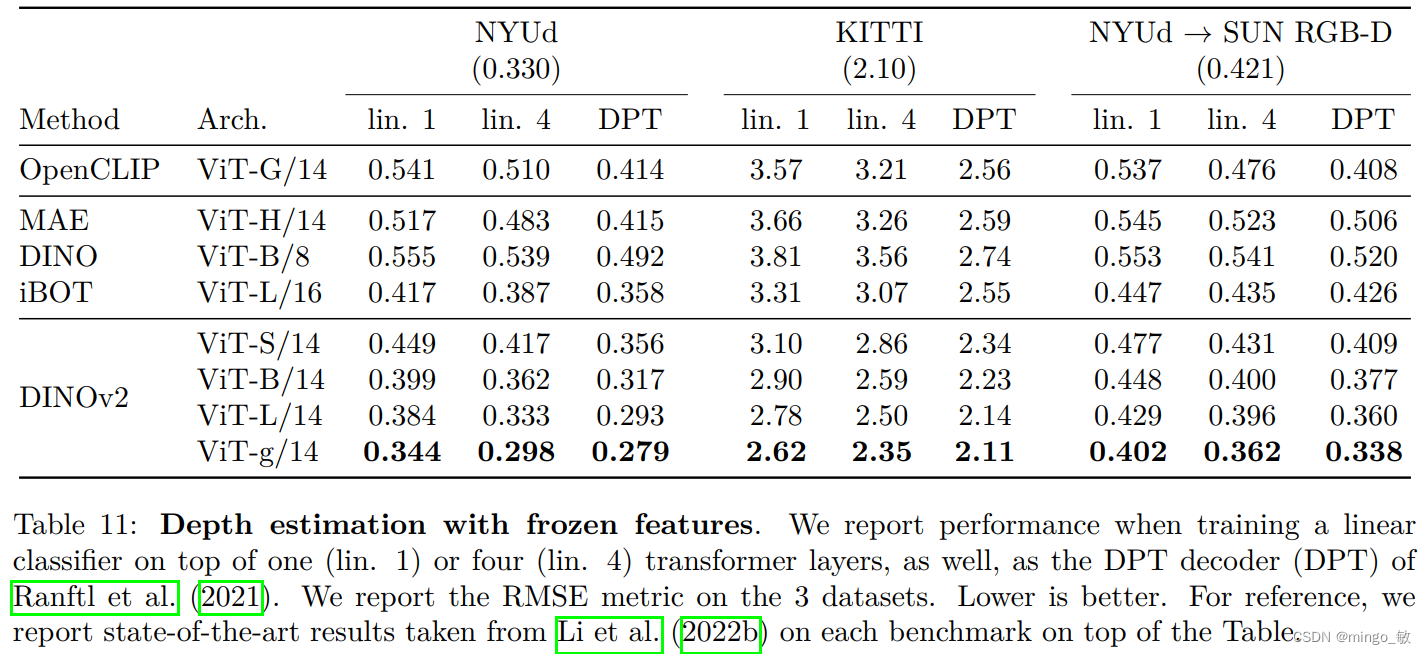
深度学习论文: DINOv2: Learning Robust Visual Features without Supervision DINOv2: Learning Robust Visual Features without Supervision PDF: https://arxiv.org/abs/2304.07193 PyTorch代码: https://github.com/shan

【大模型系列】根据文本检索目标(DINO/DINOv2/GroundingDINO)
文章目录 1 DINO(ICCV2021, Meta)1.1 数据增强1.2 损失函数 2 DINOv2(CVPR2023, Meta)2.1 数据采集方式2.2 训练方法 3 Grounding DINO3.1 Grounding DINO设计思路3.2 网络结构3.2.1 Feature Extraction and Enhancer3.2.2 Language-Guided Query
基于dinoV2分类模型修改
前言 dinoV2已经发布有一段时间了,faecbook豪言直接说前面的结构我们都不需要进行修改,只需要修改最后的全连接层就可以达到一个很好的效果。我们激动的揣摸了下自己激动的小手已经迫不及待了,这里我使用dinoV2进行了实验,来分享下实验结果。 dinoV2官方地址:github链接 一、模型介绍 1、预训练模型介绍 # dinov2_vits14_pretrain.pth 结构

CLIP与DINOv2的图像相似度对比
在计算机视觉领域有两个主要的自监督模型:CLIP和DINOv2。CLIP彻底改变了图像理解并且成为图片和文字之间的桥梁,而DINOv2带来了一种新的自监督学习方法。 在本文中,我们将探讨CLIP和DINOv2的优势和它们直接微妙的差别。我们的目标是发现哪些模型在图像相似任务中真正表现出色。 CLIP 使用CLIP计算两幅图像之间的相似性是一个简单的过程,只需两步即可实现:提取两幅图像的特征,