supervision专题
[CLIP] Learning Transferable Visual Models From Natural Language Supervision
通过在4亿图像/文本对上训练文字和图片的匹配关系来预训练网络,可以学习到SOTA的图像特征。预训练模型可以用于下游任务的零样本学习 1、网络结构 1)simplified version of ConVIRT 2)linear projectio
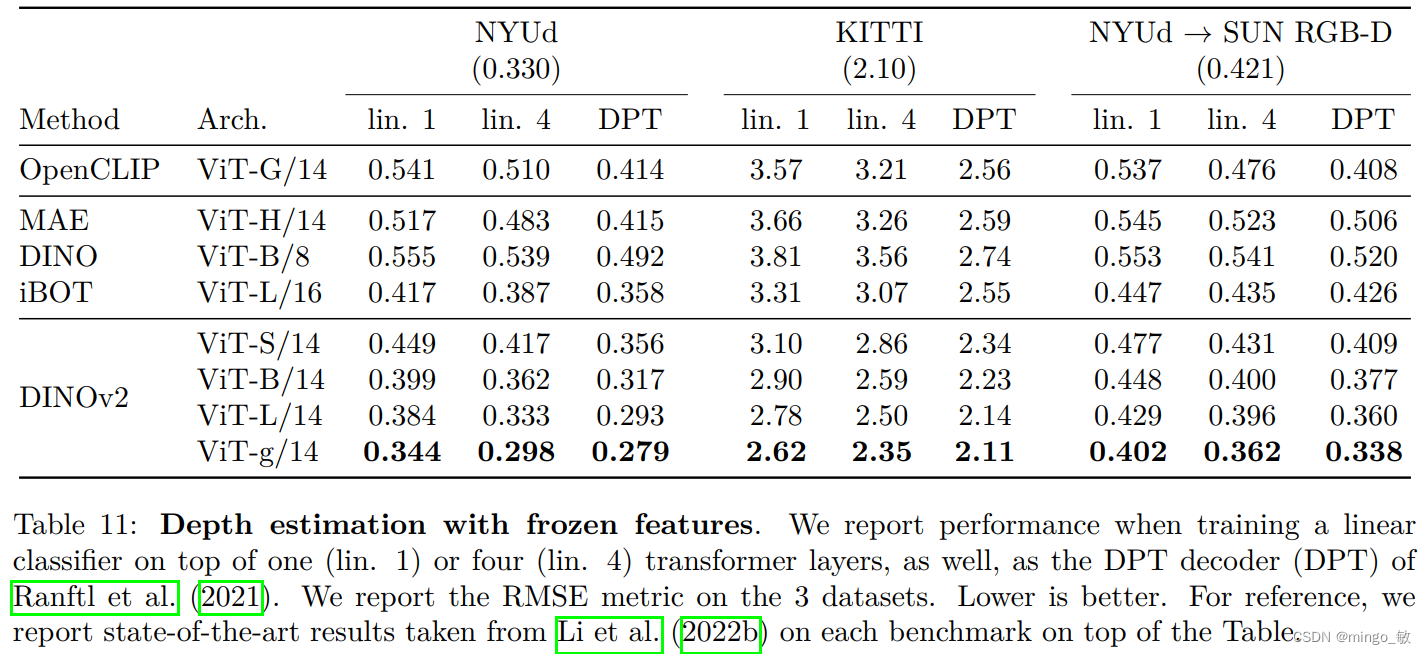
深度学习论文: DINOv2: Learning Robust Visual Features without Supervision
深度学习论文: DINOv2: Learning Robust Visual Features without Supervision DINOv2: Learning Robust Visual Features without Supervision PDF: https://arxiv.org/abs/2304.07193 PyTorch代码: https://github.com/shan
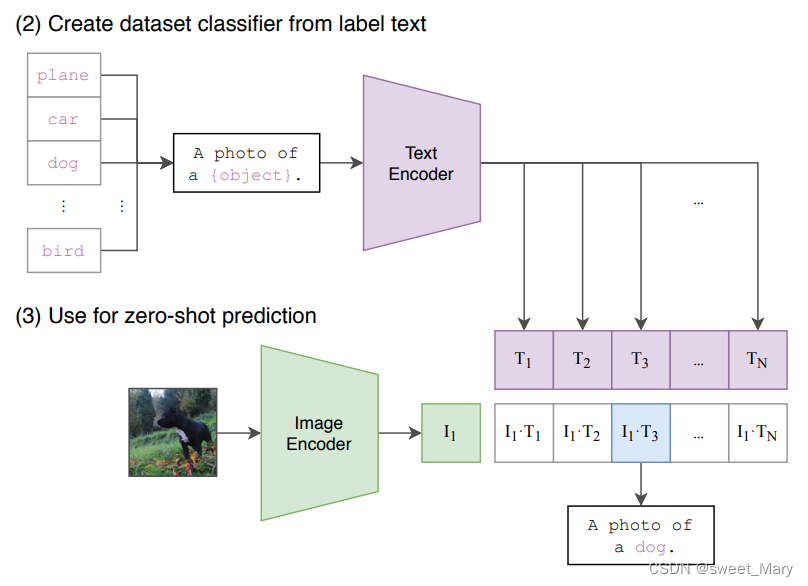
CLIP--Learning Transferable Visual Models From Natural Language Supervision
参考:CLIP论文笔记--《Learning Transferable Visual Models From Natural Language Supervision》_visual n-grams模型-CSDN博客 openAI,2021,将图片和文字联系在一起,----->得到一个能非常好表达图片和文字的模型主题:多模态理解任务 任务:计算图片和文本的相似度 训练:有监督的对比学习 背景

Learning-Pixel-level-Semantic-Affinity-with-Image-level-Supervision
paper when cvpr18,目前top榜第一。有代码。 who 基于像素级标签的图像语义分割 why 提出 分割标签的不足是在自然环境中使用语义分割的主要障碍之一。为了解决这个问题,我们提出了一种新颖的框架,可以根据图像级别的标签生成图像的分割标签。在这种弱监督的环境中,已知训练的模型将局部鉴别部分而不是整个对象区域分割。我们的解决方案是将这种定位响应传播到属于同一语义实
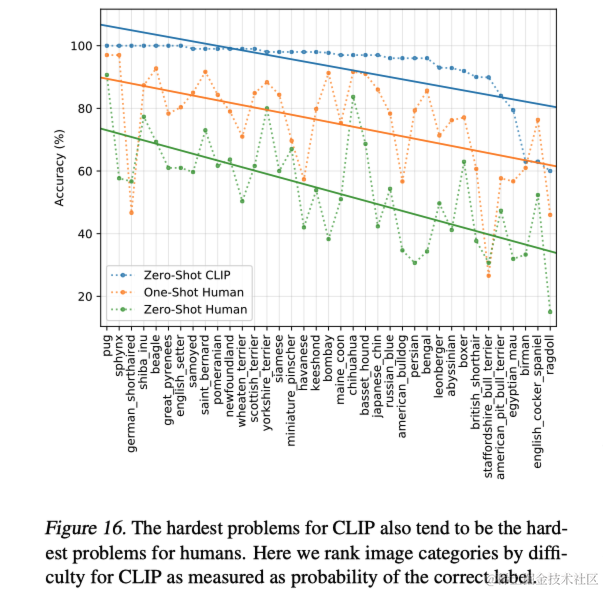
CLIP论文笔记:Learning Transferable Visual Models From Natural Language Supervision
导语 会议:ICML 2021链接:https://proceedings.mlr.press/v139/radford21a/radford21a.pdf 当前的计算机视觉系统通常只能识别预先设定的对象类别,这限制了它们的广泛应用。为了突破这一局限,本文探索了一种新的学习方法,即直接从图像相关的原始文本中学习。本文开发了一种简单的预训练任务,通过预测图片与其对应标题的匹配关系,从而有效地从一

supervision CV视觉可视化辅助工具
参考: https://supervision.roboflow.com/latest/ https://github.com/roboflow/supervision/tree/develop/examples 版本: pip install -U supervision ultralytics-8.1.35 (大于8.1才行,不然可能会有错误AttributeError: ‘Resul

O2O:Offline Meta-Reinforcement Learning with Online Self-Supervision
ICML 2022 paper Introduction 元强化学习(Meta RL)结合O2O。元RL需要学习一个探索策略收集数据,同时还需学习一个策略快速适应新任务。由于策略是在固定的离线数据集上进行元训练的,因此在适应探索策略收集的数据时,它可能表现得不可预测,该策略与离线数据可能存在系统性差异,从而导致分布偏移。 本文提出两阶段的Meta offline RL算法SMAC,该算法利用
supervision区域行人计数和轨迹追踪初步尝试
1、背景介绍 最近,一位朋友向我介绍了定位与视觉融合的需求,我发现这个想法非常有价值。恰逢我了解到了Supervision框架,便决定尝试运用它来进行初步的测试。这样做不仅有助于探索可以实际应用的项目,还能促进我自己在研究创新方面的发展。 2、Supervision介绍 Supervision 是一个开源的 Python 工具包,旨在简化计算机视觉项目的开发。它提供了一系列通用的工具和函数,
【域适应十五】Universal Domain Adaptation through Self-Supervision
1.motivation 传统的无监督域自适应方法假设所有源类别都存在于目标域中。在实践中,对于这两个领域之间的类别重叠可能知之甚少。虽然有些方法使用部分或开放集类别处理目标设置,但它们假设特定设置是已知的先验设置。本文提出了一个更普遍适用的领域自适应框架,可以处理任意类别的转移,称为通过熵优化的领域自适应邻域聚类(DANCE)。DANCE结合了两个新颖的思想:首先,由于不能完全依赖源分类来判别

基于Box Supervision的弱监督图像语义分割
简介 为什么要“弱监督”做图像语义分割 让我们来看看论文怎么说的。 ICCV 2015 BoxSup[1], “But pixel-level mask annotations are time-consuming, frustrating, and in the end commercially expensive to obtain.” ICCV 2015 WSSL[2], “Acqui
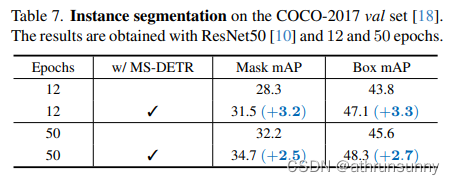
MS-DETR: Efficient DETR Training with Mixed Supervision论文学习笔记
论文地址:https://arxiv.org/pdf/2401.03989.pdf 代码地址(中稿后开源):GitHub - Atten4Vis/MS-DETR: The official implementation for "MS-DETR: Efficient DETR Training with Mixed Supervision" 摘要 DETR 通过迭代生成多个基于图像特征
weak-to-strong-generalization始终比母体更智能的人工智能,能否被它的母体所监管supervision,从而变的更强
正如supervison这个词,就像就是母亲对孩子的超级super愿景vision,比母亲更聪明更强,也就意味着要按照母亲期望的那样成长,不合理的行为要能够纠正supervison。 一代比一代强,一代比一代好。 弱模型监督能否激发出更强大模型的全部能力。 研究发现,虽然在弱监督下微调的强大模型确实能超越其弱监督者的表现,但仅靠弱监督并不能完全发挥出强大模型的潜能。 弱到强的泛化:研究表
基于GAN的小目标检测算法总结(3)——《Better to Follow, Follow to Be Better: Towards Precise Supervision ......》
基于GAN的小目标检测算法总结(3)——《Better to Follow, Follow to Be Better: Towards Precise Supervision of Feature Super-Resolution》 1.前言2.算法简介2.1 核心idea2.1.1 为什么使用feature-level的超分?2.1.2 低分特征和高分目标特征的相对感受野匹配问题 2.2网

【论文翻译】Denoising Relation Extraction from Document-level Distant Supervision
1. 介绍 关系抽取(relationship extraction, RE)的目的是识别文本实体之间的关系事实。最近,神经关系提取(NRE)模型在句子级RE中得到了验证。远程监控(DS) 提供了大规模的远程监控数据,使实例成倍增加,并支持足够的模型训练。 句子层次的重新重点是提取句子中实体之间的句子内关系。然而,由于存在大量的句间关系事实隐藏在多个句子中,在实践中其通用性和覆盖面受到极大的限
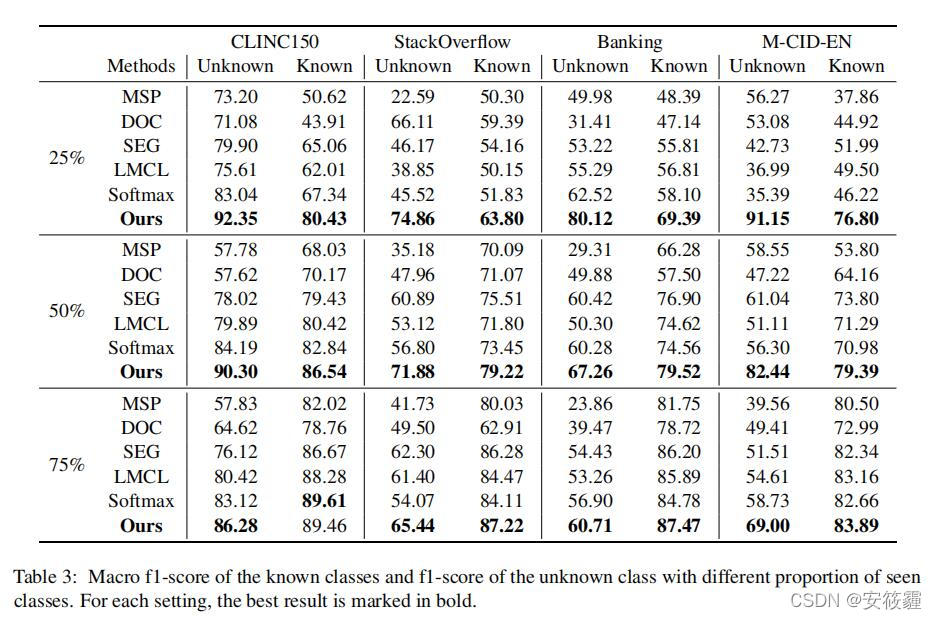
有自监督和有判别力训练的域外意图检测(Out-of-Scope Intent Detection with Self-Supervision andDiscriminative Training)阅读
发表在ACL2021上面的一篇文章 论文链接:Out-of-Scope Intent Detection with Self-Supervision and Discriminative Training - ACL Anthology 代码链接:https:// github.com/liam0949/DCLOOS Abstract 在任务型对话中域外意图检测十分重要。在训练阶段,

SF-Net: Single-Frame Supervision for Temporal Action Localization
SF-Net Abstract1 Introduction3 Proposed Method3.1 Problem Definition3.2 Framework3.3 Pseudo Label Mining and Training Objectives3.4 Inference ExperimentsDatasetsImplementation DetailsResults Conclu

Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions
主要贡献 作者提出了基于句子级别的Attention模型来选择有效的句子。从FreeBase和Wikipedia页面去获取实体描述,从而弥补背景知识不足的缺陷,从而给实体更好的representation。做了很多实验,效果很好。 任务定义 所有句子被分到N组bags中, {B1,B2,⋯,Bi} { B 1 , B 2 , ⋯ , B i } \{ B_1,B_2,⋯,
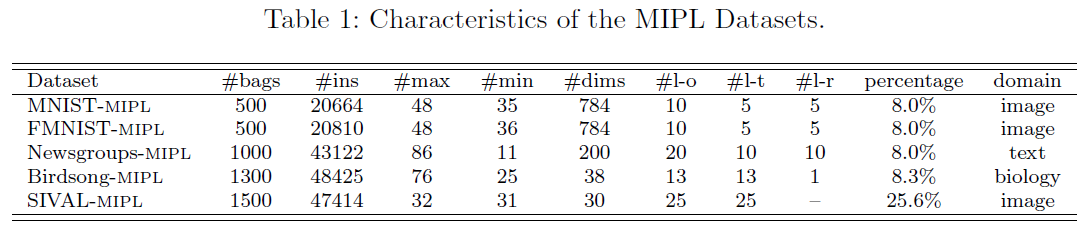
论文阅读 (91):Multi-Instance Partial-Label Learning: Towards Exploiting Dual Inexact Supervision
文章目录 1 要点1.1 概述1.2 代码及数据集1.3 引用 2 方法2.1 标签增广2.2 Dirichlet消歧2.3 高斯过程回归模型 3 实验3.1 实验设置3.1.1 数据集 1 要点 1.1 概述 名称:多示例偏标签学习:探索面向对偶不确切监督信息的学习范式 (multi-instance partial-label learning: towards ex

Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision
学习人脸反欺骗的深度模型:二进制或辅助监控 摘要 人脸反欺骗是防止人脸识别系统的安全漏洞的关键。以往的深度学习方法将人脸反欺骗表述为一个二值分类问题。他们中的许多人很难掌握足够的欺骗线索,因而无法进行有效的归纳。在本文中,我们认为辅助监督对于引导朝着区分性和普遍性限线索的学习的很重要。利用CNN-RNN模型对人脸深度进行像素监督估计对rPPG信号进行序列监督评估。估计深度和rPPG信号被融合来

EnlightenGAN: Deep Light Enhancement without Paired Supervision--论文阅读笔记
Introduction 一种高效无监督的生成对抗网络,称为EnlightenGAN,可以在没有低/正常光图像对的情况下进行训练Difficulties 1)同步捕获损坏和地面实况图像相同的视觉场景是非常困难甚至不切实际的(例如,光线和普通光照图像对在同一时间) 2)从干净的图像中合成损坏的图像有时会有帮助,但这种合成的结果通常不够逼真,当训练后的模型应用于真实的低光图像时,会产生各种伪影 3)特

ECCV2022_Point-to-Box Network for Accurate Object Detection via Single Point Supervision 论文阅读
ECCV2022_P2BNet 论文阅读 文章目录 ECCV2022_P2BNet 论文阅读0 Abstract**0-1 MIL:multiple instance learning(多示例学习)** 1 Introduction**1-0 WSOD:weakly supervised object detection(弱监督对象检测)** 2 Contributions**2-0 P2

ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
论文地址:https://arxiv.org/pdf/2102.03334.pdf 代码地址:https://github.com/dandelin/vilt. 摘要 目前的VLP方法严重依赖于图像特征提取过程,其中大部分涉及区域监督(如目标检测)和卷积体系结构(如ResNet)。虽然在文献中被忽略了,但我们发现在效率/速度方面存在问题,简单地提取输入特征比多模态交互步骤需要更多的计算,本文在

Detecting Twenty-thousand Classes using Image-level Supervision
Detecting Twenty-thousand Classes using Image-level Supervision 摘要背景方法PreliminariesDetic:具有图像类别的检测器loss技术细节扩展Grad-CAMGrad-CAM原理 总结 摘要 摘要 由于检测数据集的规模较小,目前的物体检测器在词汇量方面受到限制。而图像分类器的数据集更大,也更容易收集